
Programadores Anónimos
7.9K posts

Programadores Anónimos
@thecap_anonimo
Programadores Anónimos Podcast. Acá hablamos de software y cuántica
가입일 Şubat 2010
174 팔로잉449 팔로워

LLM Knowledge Bases
Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So:
Data ingest:
I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them.
IDE:
I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides).
Q&A:
Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale.
Output:
Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base.
Linting:
I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into.
Extra tools:
I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries.
Further explorations:
As the repo grows, the natural desire is to also think about synthetic data generation + finetuning to have your LLM "know" the data in its weights instead of just context windows.
TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
English
@ing_juani7a @Registraduria has podido comprobar estos leaks? al menos los de la nacional básicamente concluyeron que fue falsa alarma.
Español

Otro dia, otra brecha.
Hoy la presunta victima involucra a @Registraduria y de nuevo por los NyxarGroup.
Explotando vulnerabilidades q no habian querido parchar? Información vieja? Se les metieron? Información sin relevancia? No sabemos.
Pues veremos.
VECERT Analyzer@VECERTRadar
🚨 CYBERINTEL ALERT: Critical Data Leak at Colombia’s National Registry 🇨🇴🗳️ Our platform has identified a massive security breach compromising the database of Colombia’s National Civil Registry (Registraduría Nacional del Estado Civil), affecting the privacy of thousands of citizens. Victim: Registraduría Nacional de Colombia (registraduria.gov.co) 🏛️. Threat Actor: NyxarGroup 🎭. Volume: 120,000 detailed records offered for sale. Date: March 21, 2026 🗓️. Highly Sensitive Information Compromised: The dataset—structured in JSON format—contains comprehensive biographical and contact identifiers that enable the complete reconstruction of a citizen's identity: 🔹 Identity and Kinship: NUIP (Unique Personal Identification Number), full names and surnames, parental details (names, ID numbers, and country of origin), and blood type. 🔹 Location and Contact: Residential addresses, email addresses, mobile phone numbers, and landline numbers. 🔹 Civil Records: Dates and places of birth, municipalities of document issuance, and registration dates. 🔹 Ethnic and Gender Data: Information regarding ethnic affiliation and gender identity. Monitor: analyzer.vecert.io #CyberSecurity #Colombia #Registraduria #DataBreach #NyxarGroup #InfoSec #CyberAlert #DigitalIdentity
Español
Programadores Anónimos 리트윗함

Once a doctor re-invented integration by trapezoidal rule because she did not learn it in school.
She received 75 citations for her novel work.
She even named it after herself. lol.

Valentin Ignatev@valigo
I desperately need to learn more math. Recently I invented "lerp" from first principles. Would have saved some time if I knew its industry-standard name :/
English
Programadores Anónimos 리트윗함

Si no respetas una voz distinta, no estás listo para representar a todas.
Español
Programadores Anónimos 리트윗함

@ing_juani7a foto / código estudiante. Aunque no recomiendan navegar al foro, hablan que están monitoreando quién accede.
Español
Ya podemos decir q pasa algo con las universidades en Locombia?
Llueven databreaches.
Para nada normal.
😱
VECERT Analyzer@VECERTRadar
🚨 CRITICAL BREACH: 100K Student Records Leaked from Universidad Nacional de Colombia 🚨 Victim: Universidad Nacional de Colombia (UNAL) 🇨🇴 Threat Actor: NyxarGroup Timestamp: February 26, 2026 Sector: Education Volume: 100,000 Student Records The threat actor NyxarGroup has claimed responsibility for the exfiltration and publication of a database stolen directly from the official domain of the National University of Colombia (unal.edu.co). Monitor: analyzer.vecert.io #CyberSecurity #DataBreach #Colombia #UNAL #UnalMed #NyxarGroup #EducationSecurity #PII #ThreatIntel #InfoSec #OSINT
Español
@carlosvillu Todo muy bonito, “darle control total a todos los sistemas a un agente”. Después te encuentras con los de ciberseguridad y las políticas de los servicios Cloud, y el agente no puede hacer nada.
“Dime que no sabes de software sin decirlo”
Español

MCP tuvo su momento. Pero cuando puedes tener acceso directo a todo lo que necesitas, ¿para qué pagar el peaje de un protocolo?
El futuro no tiene intermediarios.
Programmatic Tool Calling > MCP.
platform.claude.com/docs/en/agents…
Español
🔥 UNPOPULAR OPINION:
MCP está muerto.
OpenClaw fue el último clavo en su ataúd.
Y el reemplazo ya está aquí. 🧵👇

Español
Programadores Anónimos 리트윗함

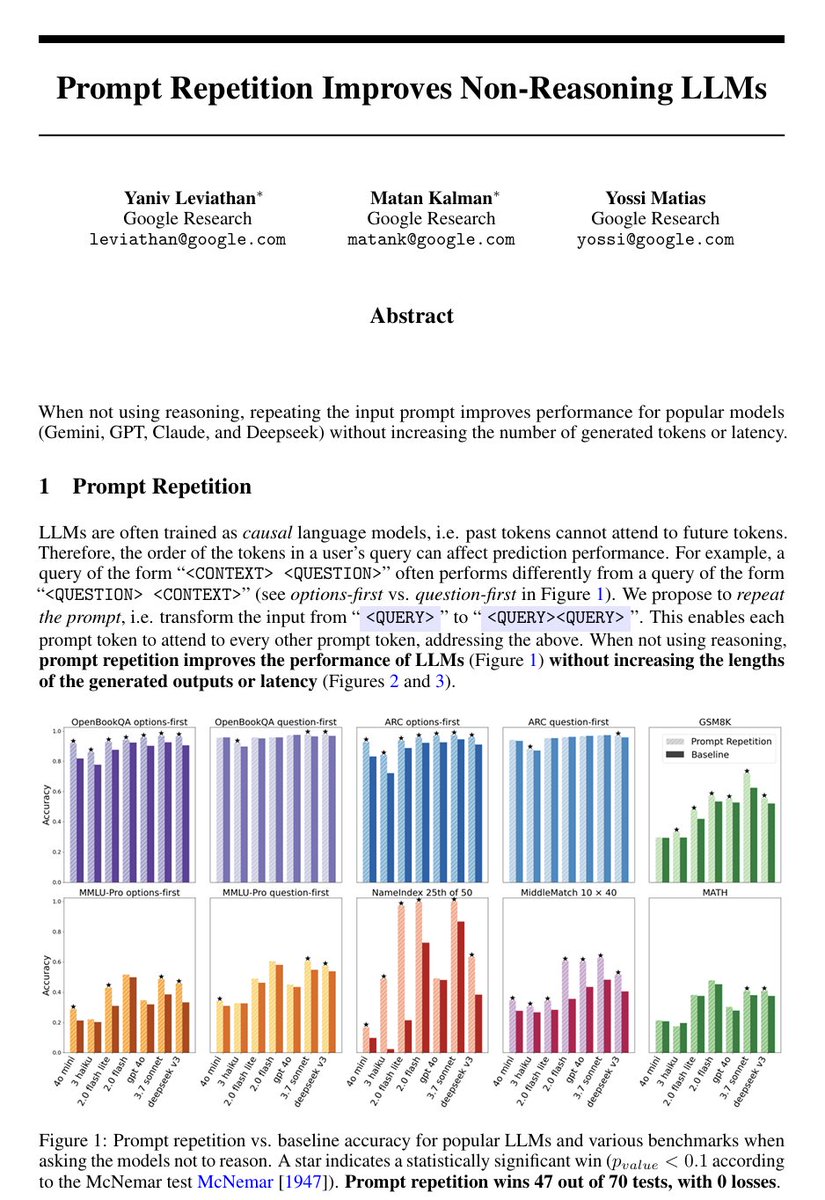
LLMs process text from left to right — each token can only look back at what came before it, never forward. This means that when you write a long prompt with context at the beginning and a question at the end, the model answers the question having "seen" the context, but the context tokens were generated without any awareness of what question was coming. This asymmetry is a basic structural property of how these models work.
The paper asks what happens if you just send the prompt twice in a row, so that every part of the input gets a second pass where it can attend to every other part. The answer is that accuracy goes up across seven different benchmarks and seven different models (from the Gemini, ChatGPT, Claude, and DeepSeek series of LLMs), with no increase in the length of the model's output and no meaningful increase in response time — because processing the input is done in parallel by the hardware anyway.
There are no new losses to compute, no finetuning, no clever prompt engineering beyond the repetition itself.
The gap between this technique and doing nothing is sometimes small, sometimes large (one model went from 21% to 97% on a task involving finding a name in a list). If you are thinking about how to get better results from these models without paying for longer outputs or slower responses, that's a fairly concrete and low-effort finding.
Read with AI tutor: chapterpal.com/s/1b15378b/pro…
Get the PDF: arxiv.org/pdf/2512.14982
English
Programadores Anónimos 리트윗함


Programadores Anónimos 리트윗함

The amount of crap I get for putting out a hobby project for free is quite something.
People treat this like a multi-million dollar business. Security researchers demanding a bounty.
Heck, I can barely buy a Mac Mini from the Sponsors.
It's supposed to inspire people. And I'm glad it does.
And yes, most non-techies should not install this.
It's not finished, I know about the sharp edges.
Heck, it's not even 3 months old.
And despite rumors otherwise, I sometimes sleep.
English
@Docarlosalvarez @petrogustavo Independiente de si es falsa la información. Interesante como nadie habla del tope mínimo para salarios integrales, y asumen directamente que les pagaban el mínimo a los internistas. 🤷🏻♀️🤦🏽♀️
Español

Hoy despidieron a los 18 internistas de planta que trabajamos en la fundación shandafé, nos informaron que NO pueden asumir un incremento de salario tan alto...
Gracias @petrogustavo eres una escoria...
Español
Programadores Anónimos 리트윗함

Nobel de Física 2025. Efecto túnel mecánico cuántico macroscópico, Francis Villatoro.
#YouTube en La Fábrica de la Ciencia @jonsulve1170
youtube.com/watch?v=PD1Vpa…

YouTube
Español
Programadores Anónimos 리트윗함

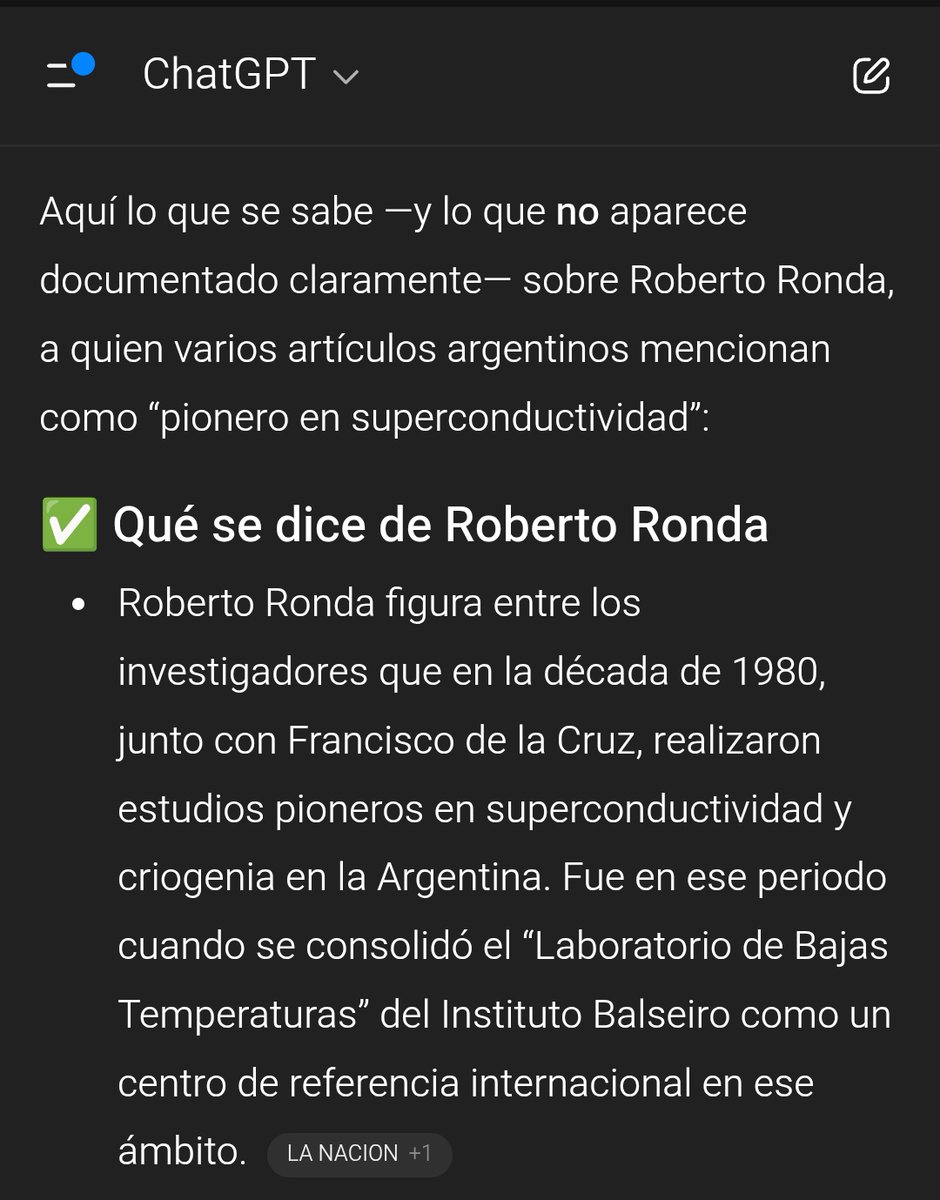
Problemón: las alucinaciones de los chatbots IA comienzan a ser replicadas como información "verificada".
Caballero escribió esta nota usando IA, inventó un físico llamado Roberto Ronda. Ahora cuando le preguntás a ChatGPT sobre Ronda, cita la nota como fuente. 🤷♂️

Español
Programadores Anónimos 리트윗함

Quantum theory is no longer imaginary.
quantamagazine.org/physicists-tak…
English
@RincnCuriosoo Yo viendo que no lo cortó en el borde 😩
Español

¿Conoces el nombre de este postre?
twitter.com/jenekemi/statu…
Español
Programadores Anónimos 리트윗함

Las clases del Prof. Edward Witten en la Escuela Giambiagi 2025 están disponibles en nuestro canal de YouYube:
youtu.be/kXxDpPZBWvM?fe…

YouTube

Español
Dicen que es más duro hacer crecer una cuenta vieja con pocos seguidores, que hacer crecer una desde 0
Español
Una compra con tarjeta, el dinero sale de mi cuenta, les falla el datáfono del comercio y termino pagando dos veces por el producto. instagram.com/maxcotascenter… no se hace responsable. Básicamente me robaron, en la 🫥. Será que me ayudan reportando el comercio por fraude? 🫠
Español
@InformaCosmos De esos 4 votos en blanco. Me postulo yo como vocero! 🙄
Español



Diga lo que siente por este gobierno con un emoticón...
#NoticiasParaHuir
Español