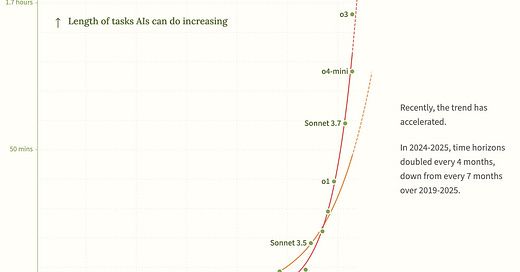
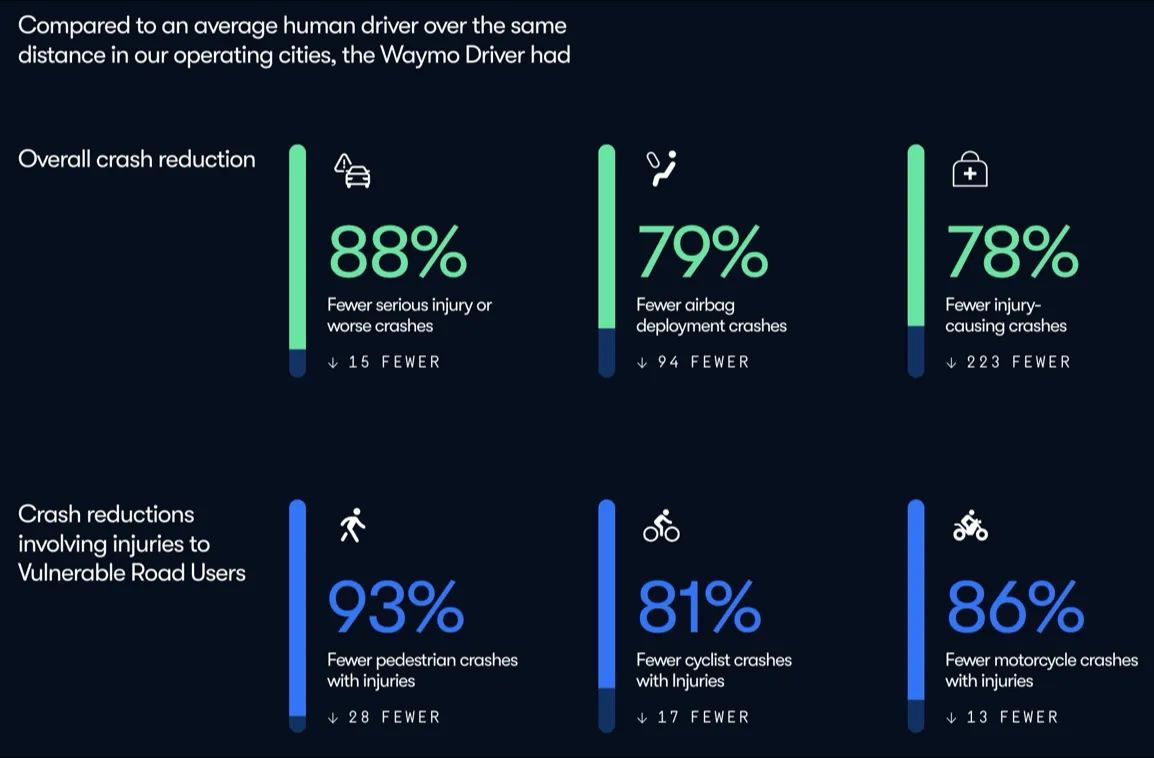
고정된 트윗

1/
You want to build a prototype fast.
Show it to clients. Get feedback. Iterate.
But jumping from Figma to real code always breaks the flow.
Until now.
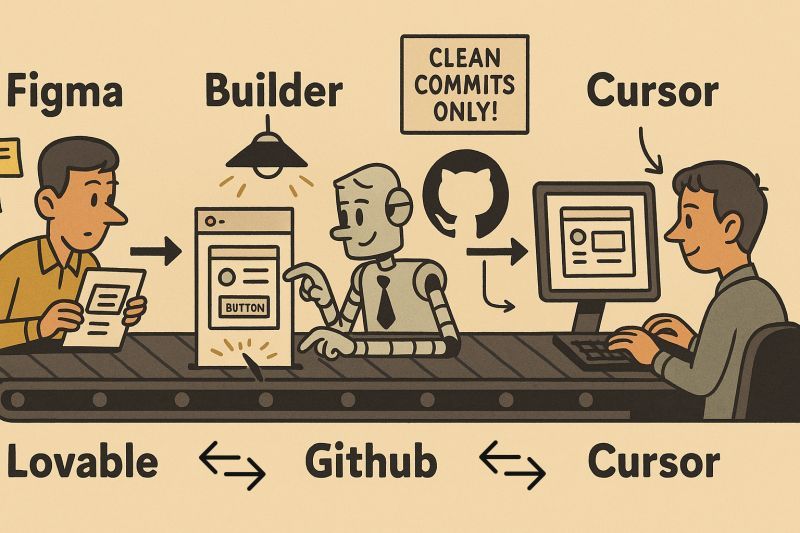
I’ve been testing this new AI-native prototyping stack 👇
@figma > Builder.io > @lovable > @github > @cursor_ai
English