고정된 트윗
Theta
16 posts


For a deeper dive, check out our blog with @SeanZCai: thetasoftware.ai/#/blog/market-…
English
Why Now? (4/4)
AI-first browsers are poised to disrupt the massive web browser market, with highly anticipated releases like Comet from @perplexity_ai on the way. It's yet to be seen how Google integrates Project Mariner and other AI tools within Chrome.
English

Theta 리트윗함

The AI labs need better evals and one of my favorite current YC batch companies just released a one with a *lot* of headroom
Theta@trytheta
Introducing CUB: Humanity's Last Exam for Computer and Browser Use Agents
English
The Theta team started CUB as an internal evalset, but it quickly grew into a full-fledged benchmark over the past month. We're excited to test even more models and frameworks. For more on the benchmark, including examples and a full paper, check out our blog:
thetasoftware.ai/#/blog/introdu…
English
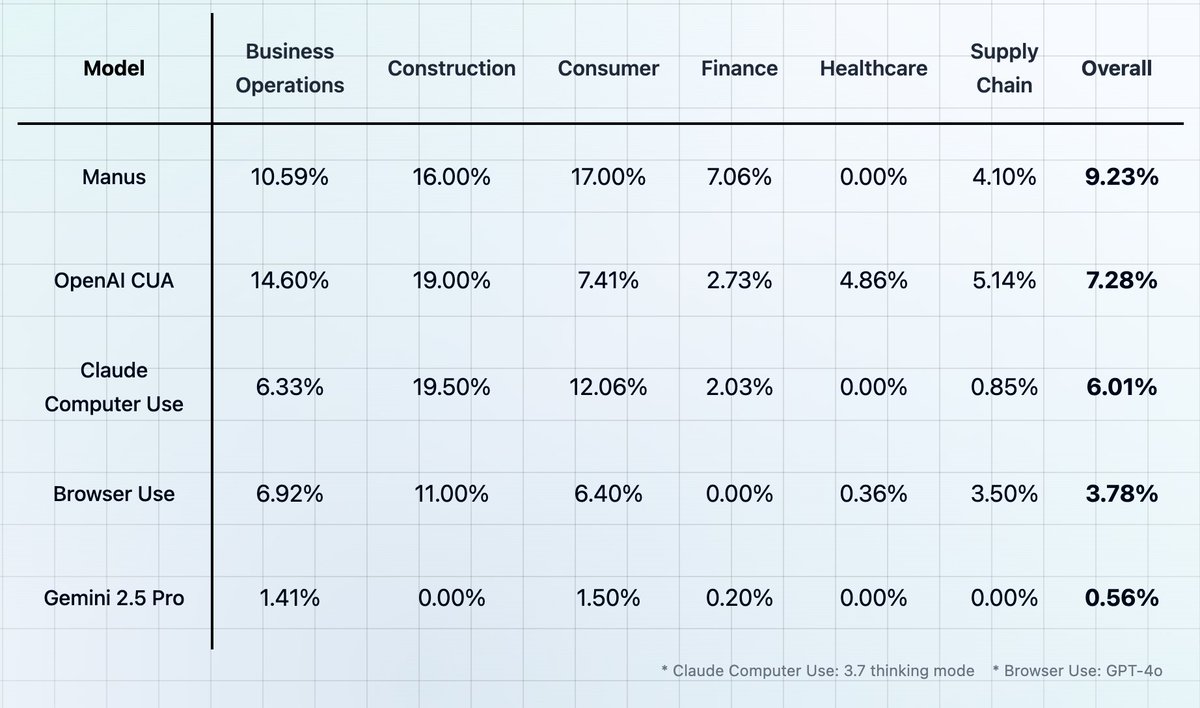
Computer/browser use agents still have a long way to go for more complex, end-to-end workflows. Actual task completion is far below our reported numbers: we gave credit for partially correct solutions and reaching key checkpoints. In total, there were less than 10 instances across our thousands of runs where an agent successfully completed a full task.
English
Theta 리트윗함

we've been misled to believe that manual prompt hacking is the solution to teaching LLMs how to approach complex problems. why write a "magic prompt" to pattern match for every type of problem you might care about, when LLMs have already shown extraordinary ability to self-review and self-correct given the right feedback loops
@karpathy alludes to it here, but what's missing is a memory layer so that LLMs can learn from their previous mistakes. they suffer from amnesia because they lack a mechanism to record and build upon problem solving strategies. a memory layer allows for this "system prompt learning" instead of relying on explicit human feedback
there's a lot of engineering challenges in getting this to work effectively. how do you measure which insights are effective, and how do you refine them from feedback? building a "scratchpad" of notes that can be maintained over thousands of runs and indexed efficiently to get the right notes is a non-trivial problem, and it's exactly what we're tackling at @trytheta
Andrej Karpathy@karpathy
We're missing (at least one) major paradigm for LLM learning. Not sure what to call it, possibly it has a name - system prompt learning? Pretraining is for knowledge. Finetuning (SL/RL) is for habitual behavior. Both of these involve a change in parameters but a lot of human learning feels more like a change in system prompt. You encounter a problem, figure something out, then "remember" something in fairly explicit terms for the next time. E.g. "It seems when I encounter this and that kind of a problem, I should try this and that kind of an approach/solution". It feels more like taking notes for yourself, i.e. something like the "Memory" feature but not to store per-user random facts, but general/global problem solving knowledge and strategies. LLMs are quite literally like the guy in Memento, except we haven't given them their scratchpad yet. Note that this paradigm is also significantly more powerful and data efficient because a knowledge-guided "review" stage is a significantly higher dimensional feedback channel than a reward scaler. I was prompted to jot down this shower of thoughts after reading through Claude's system prompt, which currently seems to be around 17,000 words, specifying not just basic behavior style/preferences (e.g. refuse various requests related to song lyrics) but also a large amount of general problem solving strategies, e.g.: "If Claude is asked to count words, letters, and characters, it thinks step by step before answering the person. It explicitly counts the words, letters, or characters by assigning a number to each. It only answers the person once it has performed this explicit counting step." This is to help Claude solve 'r' in strawberry etc. Imo this is not the kind of problem solving knowledge that should be baked into weights via Reinforcement Learning, or least not immediately/exclusively. And it certainly shouldn't come from human engineers writing system prompts by hand. It should come from System Prompt learning, which resembles RL in the setup, with the exception of the learning algorithm (edits vs gradient descent). A large section of the LLM system prompt could be written via system prompt learning, it would look a bit like the LLM writing a book for itself on how to solve problems. If this works it would be a new/powerful learning paradigm. With a lot of details left to figure out (how do the edits work? can/should you learn the edit system? how do you gradually move knowledge from the explicit system text to habitual weights, as humans seem to do? etc.).
English
Theta 리트윗함

Theta (@trytheta) allows AI agents to learn from their mistakes in real-time. Their memory layer has already improved the accuracy of OpenAI Operator by 43% with 7x fewer steps taken.
ycombinator.com/launches/NTK-t…
Congrats on the launch, @RayanGarg, @tsha444, and @_gurvir_!
English