고정된 트윗
Kevin
1.5K posts

Kevin
@typedarray
Engineering @monad @ponder_sh. EVM, TypeScript, open-source enjoyer
Brooklyn, NY 가입일 Ağustos 2021
714 팔로잉1.7K 팔로워

@ptrwtts Unfortunately this EIP becomes much less useful if the logs are only available starting from the fork block (missing data / incorrect accounting for older accounts)
To backfill them, you'd need to rewrite history - don't think there's any appetite for that (on ethereum)
English


@hemaaanth Quite common!
#L363-L366" target="_blank" rel="nofollow noopener">github.com/ponder-sh/pond…
Français

why say more word when less word do trick

Goldsky ☀️@goldskyio
Your app (and indexer) is only as reliable as your RPC. The scary part is you usually don't know it's failing until your users do. Introducing Goldsky Edge: fault-tolerant RPC built for billions of requests, backed by a global CDN 1/
English
@DennisonBertram @doomerfied trading card games, like magic the gathering and pokemon
English


We're continuing to develop Ponder.
And through contributions at the protocol layer, we have an opportunity to make Ponder better by pushing forward the entire EVM data & indexing landscape.
Huge thanks to the Ponder community for your support as we enter this new chapter!
English
@itunpredictable @cedar_db > maybe it’s because they’re just really humble, but more people should know about this team!!
It's because the database is closed source with a restrictive license. Current posture will turn off any potential evangelist.
Great vision but need to rethink distribution entirely
English

@cedar_db is incredibly cool and more people should know about it. They’re a team of PhDs in Munich building a new relational database, on top of almost 10 years of academic research, that crushes existing benchmarks and maybe (finally?) gets us to the HTAP grail.
The core idea is that existing RDBMSes like MySQL and Postgres were built more than 30 years ago, on assumptions about hardware constraints that are just not true anymore. These ecosystems have evolved admirably but ultimately…it’s a database. It’s built not to change very much.
Here are a few of the ways that CedarDB is rethinking every element of the database:
1) A better query optimizer
In the last 30 years we’ve made a lot of progress on how to optimize SQL queries, to the point where an optimized query can easily outperform a not-so-optimized query by a ton.
But not many query optimization improvements have made the leap from research into databases today.
CedarDB did a few things on this front:
Implemented the unnesting algorithm developed by Thomas Neumann (one of the leaders of the Umbra research project CedarDB came from) — an improvement of more than 1000x
Developed a novel approach to join ordering using adaptive optimization that can handle 5K+ relations
Created a statistics subsystem that tells the optimizer things that traditional databases can’t
2) What if your database was actually a compiler?
CedarDB doesn’t interpret queries, it instead generates code. For every SQL query that a user writes, CedarDB processes, optimizes it, and generates machine code that the CPU can directly execute.
This has been a holy grail for a while, and they implemented it via a custom low-level language that is cheap to convert into machine code via a custom assembler.
Another way that CedarDB improves performance is through Adaptive Query Execution. Essentially they start executing each query immediately with a “quick and dirty” version, while working on better versions in the background.
3) Taking advantage of all cores / Ahmdal’s law
Distributing fairly between all available cores is notoriously difficult, and the CedarDB team would argue that most databases underutilize their hardware.
Their clever approach to this problem is called morsel-driven parallelism. CedarDB breaks down queries into segments: pipelines of self-contained operations. Then, data is divided into “morsels” per segment – small input data chunks containing roughly ~100K tuples each.
You can read more in the original paper here: db.in.tum.de/~leis/papers/m…
4) Rethinking the buffer manager
Modern systems come equipped with massive amounts of RAM; there’s actually much more “room at the club” than database developers initially assumed.
So the idea of the revamped buffer manager in CedarDB is that you can (and should) expect variance not just in data access patterns, but in storage speed and location, page sizes and data organization, and memory hierarchy.
CedarDB’s buffer manager is designed from the ground up to work in a heavily multi-threaded environment. It decentralizes buffer management with Pointer Swizzling: Each pointer (memory address) knows whether its data is in memory or on disk, eliminating the global lock that throttles traditional buffer managers.
5) Building a database for change
Databases are built to not change. It’s exactly this stability that gives each generation the confidence to build their apps (no matter how different they are) on systems like Postgres. You know what you’re getting. But there’s also a clear downside to this rigidity.
CedarDB’s storage class system employs pluggable interfaces where adding new storage types doesn’t require rewriting other components. E.g. if CXL becomes the go-to storage interface at some point in the future, you don’t need to write another whole component, you just need another endpoint for the buffer manager.
Anyway these are just a few of the ideas they’re bringing to the table. Maybe it’s because they’re in Germany, maybe it’s because they’re just really humble, but more people should know about this team!!
Check out the full post here: amplifypartners.com/blog-posts/the…
English
@0xabhk @ponder_sh Excellent. 2 million years from now, there will be one fewer GitHub issue to triage.
English

@typedarray @ponder_sh it's technically possible but when you run the math, the probability is just zero
2 million years before we reach that edge case even if the blocktime is 10ms
English
can anyone from the @ponder_sh team help me understand why the blocknumber that i get from events has a type of bigint (numeric78)
couldn't we be just fine with using an int4 or int8?
English
@colinhacks @kentcdodds I went down the exact same road over the past couple years. It's wild how strong of a taste so many people have around this. Delighted by the new change.
English

fair.
at least 10 times in the last 5 years I would try to change the default Next.js boilerplate from relying on tsconfig path aliases (shouldn't impact module resolution IMO) and would promptly realize I had to add lines for every top-level dir
then I realized I couldn't do a find&replace for @/* to #/*
then I would be sad
below is from a project I'm working on now. I just *really* don't like strong coupling like this (even more so when there's no reason for it)
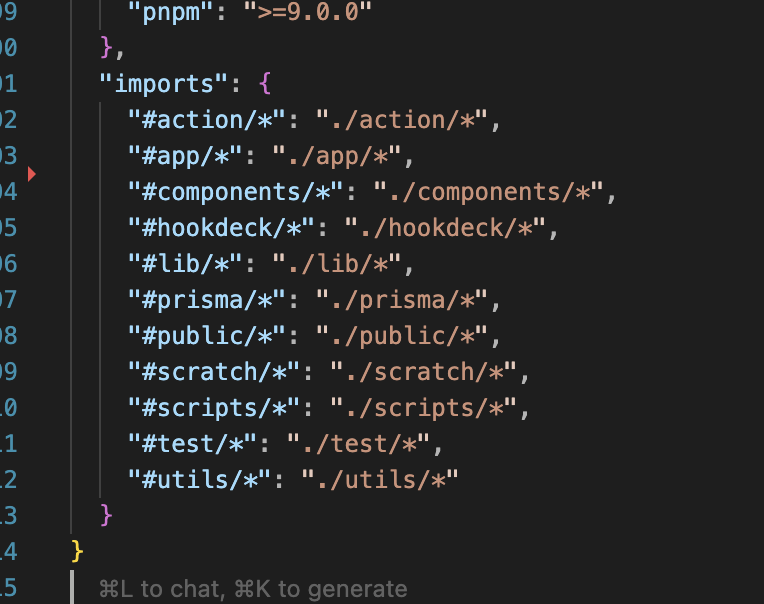
English
package.json#imports have been practically unusable since they were introduced in 2020 because they didn't support top-level wildcards, e.g. "#/*"
insanely, it turns out there was literally no reason for this and it was just never reconsidered after the initial PR

Steven ⬢@styfle
Node.js added support for path rewrites for #/ wildcard. This means you don't need typescript voodoo to use project relative imports. Thanks to @hybristdev github.com/nodejs/node/pu…
English

English


The 0.15 release also improves SQL-over-HTTP live queries, reduces memory usage during cold backfills, and fixes other reliability & correctness bugs.
Migration guide: ponder.sh/docs/migration…
Get started: ponder.sh/docs/get-start…
Chat: t.me/pondersh
English
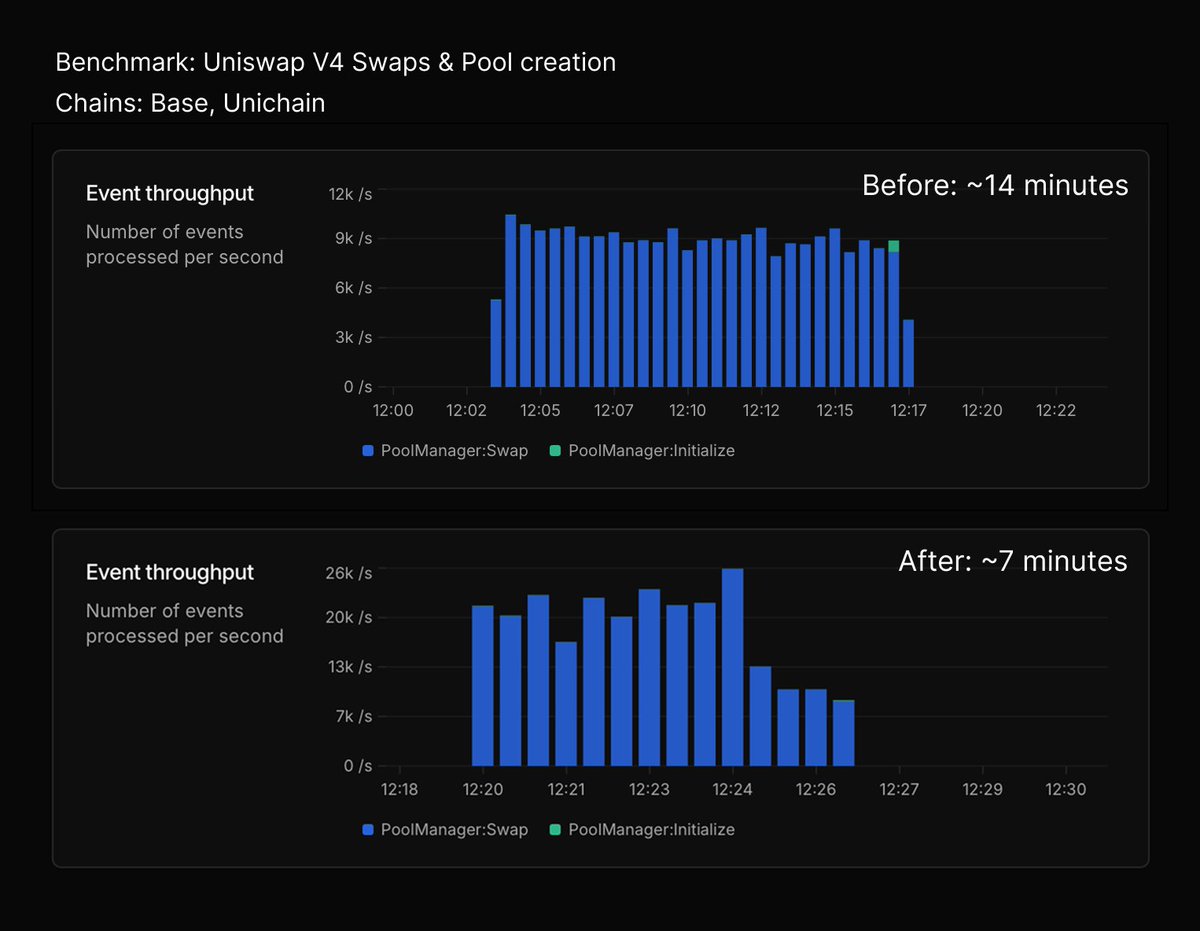

A $160/month server can already sustain 60k~111k TPS.
However, a CPU of that server may only handle 4-5 heavy eth_getLogs, eth_call, or eth_estimateGas requests a second...
RPC throughput & latency aside, there are many race conditions as we lower the block time and promote pending state (shreds, flashblocks).
For instance, the world may have changed a lot between the time a simulation is done and the signed transaction hits the block builder. New block number, storage slots, etc., can completely change the outcome of a transaction, leading to unexpected results and gas estimates.
Yapping high TPS is fun, but scaling RPC's speed and accuracy is much more critical!
We'll start with better cache & indexing for RPC; before proposing more RPCs like EIP-7966 that skyrocket UX 🫡.

Hai | RISE@hai_rise
13 days later, on the same $160/month bare metal, we've gone from 90k to 111k peak TPS. Extremely stable without a single block lag. Ceiling still nowhere to be found. Modern hardware is amazingly fast; we just need to write much better software!
English
Upgrade and enjoy.
Migration guide → #014" target="_blank" rel="nofollow noopener">ponder.sh/docs/migration…
Chat → t.me/pondersh
GitHub → github.com/ponder-sh/pond…
English
This release also adds support for offset pagination in the GraphQL API, alongside the existing cursor pagination feature.
Offset pagination makes it easy to build the “jump-to-page” UX common on dashboards & tables.
Docs: #pagination" target="_blank" rel="nofollow noopener">ponder.sh/docs/query/gra…
English
