고정된 트윗

vickieGPT
16.7K posts

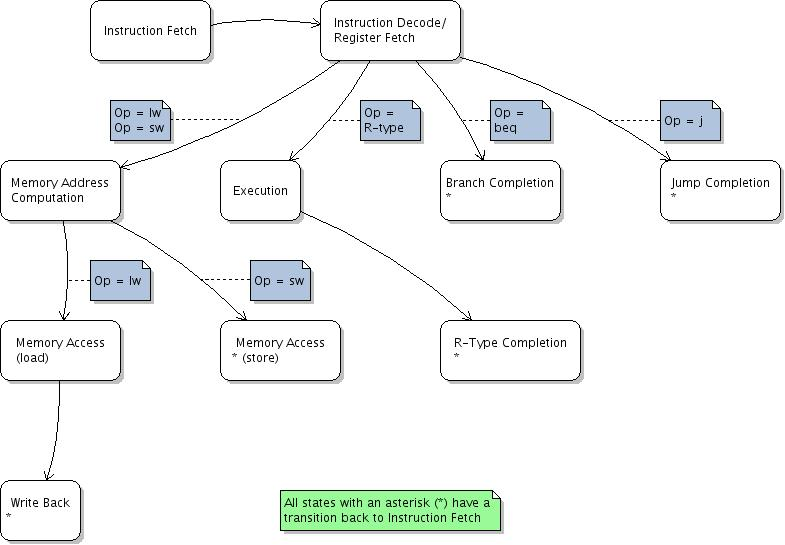



BREAKING: Google is in talks with Marvell to build 2 new AI chips for inference >a memory processing unit that works alongside TPUs >a new TPU built specifically for running AI models Google plans to produce nearly 2 million memory processing units this is Google diversifying away from Broadcom, who charges fees on every TPU produced ITS HAPPENING



NVIDIA GPUs are the modern-day equivalent of the CISC ISA. TPUs, LPUs and other accelerators are the modern-day equivalent of the more elegant RISC ISA. Intel won the RISC vs CISC war of the 1990s. Who will win the AI architecture war of today? 🤔 The most optimal AI computer is yet to be built!


Claude Design 真的太 agentic 了,它的导出 HTML 功能居然就是发一个指令给旁边的 Agent,让它开发一个 HTML 页面。一个功能就是一个 prompt,这应该就是未来的 Agent 软件雏形了。所有功能都不需要代码,直接让 Agent 现场开发就行。 我突然有一种 prompt 即代码的感觉,Agent 成了 prompt 的解释器,以前是通过 Python 解释器来执行 Python,现在直接通过 Agent 去执行 prompt 就可以了,代码成了更底层的抽象。

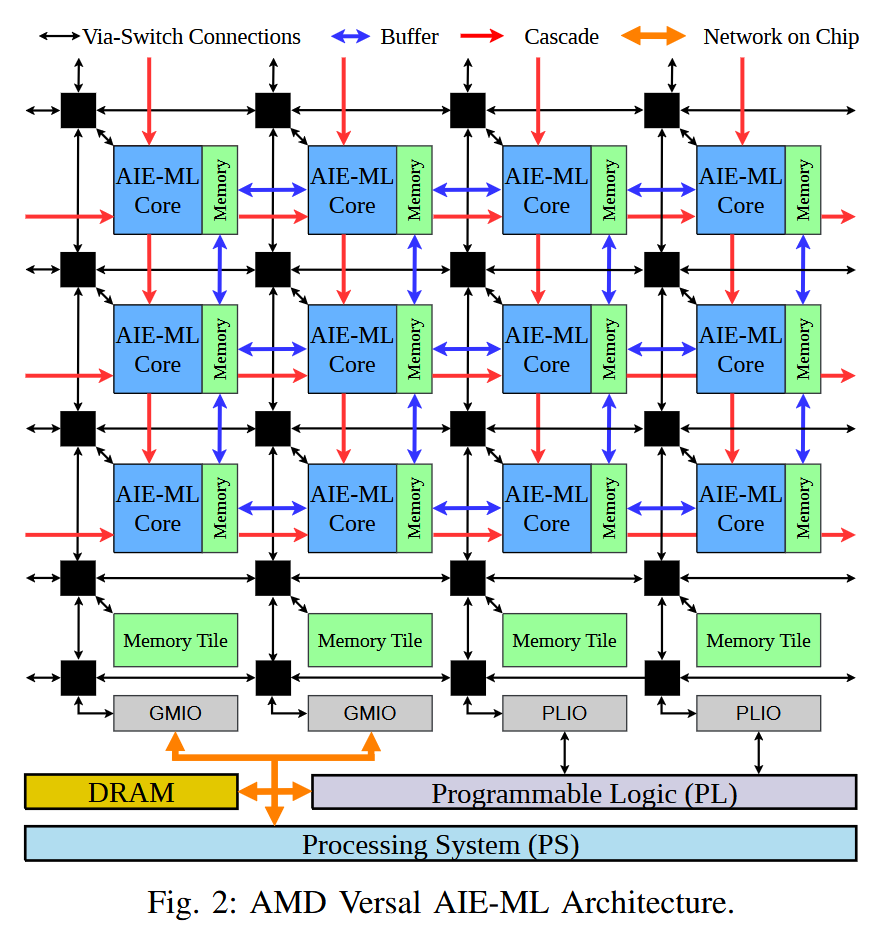


glibc malloc internals sourceware.org/glibc/wiki/Mal… #MemoryManagement