fcan
91 posts



Nvidia endpoint'indeki belirli modelleri okul veya iş mail adresi ile ücretsiz kullanabiliyorsunuz ancak denediğim tüm modeller çok yavaş.
Step 3.5 dışında verim alamadım diyebilirim.
API key ve endpoint URL ile istenilen harness'a bağlanılabilir gibi.
build.nvidia.com/models
Türkçe

Every single guy gets oneshotted by LLMs recommending ollama for local infra
0xMarioNawfal@RoundtableSpace
A FREE PRIVATE AI AGENT ON YOUR LAPTOP IS STARTING TO LOOK WAY MORE REAL. Hermes, Ollama, and Gemma 4 turn a simple setup into a local agent with web research, self improving skills, and zero monthly model rent.
English

Everybody's request to join x/LocalLLaMA has been approved
We're 7772 strong now

Ahmad@TheAhmadOsman
Working on approving all members requests to our x/LocalLLaMA community twitter.com/i/communities/…
English

Using Sonnet 4.6 for a Hermes Agent --- just spent $1.40 in API costs to ask it what the weather is like in Marbella today
Not sure it's going to be cost-saving to route 10,000 monthly customer support conversations to this then
😄
English

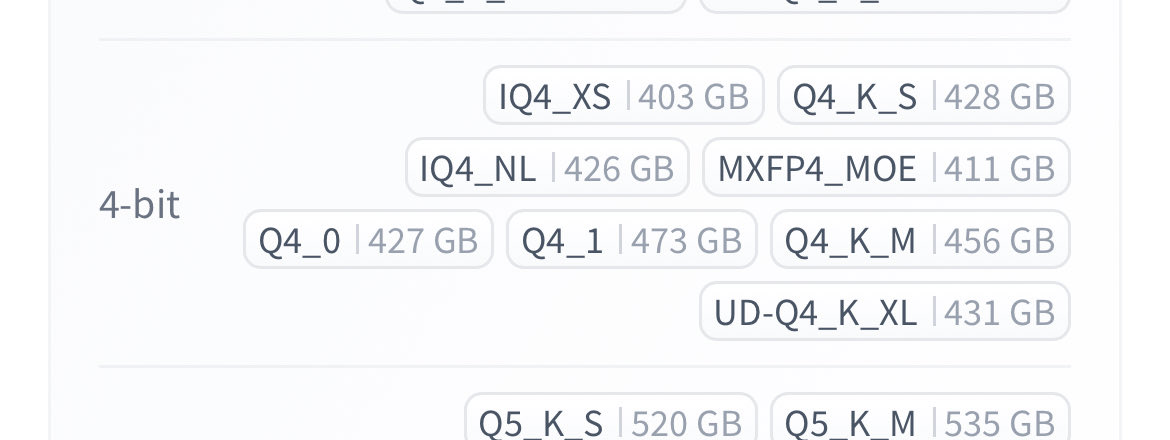
3090 Ti'da test etmeye başladığım modeller:
1) Qwen 3.5 & türevleri (Opus distilled,uncensored vb.)
2) nvidia/Nemotron-Cascade-2-30B-A3B
3) vngrs-ai/Kumru-2B
4) Sevgili @AlicanKiraz0 'dan /Kara-Kumru-v1.0-2B
5) Oto.tamamlama için zed-industries/zeta-2 (@0xSero 'nun önerisi ile)
Türkçe

Best models to run on your hardware level
I'll be doing this every week, I hope you guys enjoy.
---- 8 GB ----
Autocomplete for coding (like Cursor Tab)
- huggingface.co/NexVeridian/ze…
- huggingface.co/bartowski/zed-…
Tool calling, assistant style
- huggingface.co/nvidia/NVIDIA-…
---- 16 Gb ----
Here things get better:
Multimodal
- huggingface.co/Qwen/Qwen3.5-9B
- huggingface.co/Tesslate/OmniC…
- huggingface.co/unsloth/Qwen3.…
---- 24 GB ----
- The best model you can get (thanks Qwen) huggingface.co/Qwen/Qwen3.5-2…
- Great model (strong agents) huggingface.co/nvidia/Nemotro…
- Mine hehe huggingface.co/0xSero/Qwen-3.…
I'm doing a weekly series
English
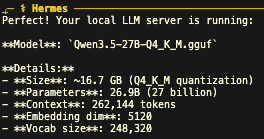
@sudoingX 'in önerisi ile Qwen3.5-27B q4'ü aşağıdaki argları kullanarak 1x3090'da çalıştırıyorum.
llama-server -ngl 99 -c 262144 -fa on --cache-type-k q4_0 --cache-type-v q4_0
Modeli @NousResearch Hermes agentı'na bağladım.
Birkaç debug işlemi yaptım. İlk izlenimim çok olumlu
Türkçe
@0xSero you should check out nerve.
github.com/daggerhashimot…
i know the dev, he is a brillant guy btw.
English
Token/inference talebi gittikçe artarken YZ yatırım balonu olduğunu iddia edenlere inanmıyorum.
Ve tabi ki lokal llm çalıştırıp kendinizi bu bağlamdan kurtarmak büyük rahatlık..
Thariq@trq212
To manage growing demand for Claude we're adjusting our 5 hour session limits for free/Pro/Max subs during peak hours. Your weekly limits remain unchanged. During weekdays between 5am–11am PT / 1pm–7pm GMT, you'll move through your 5-hour session limits faster than before.
Türkçe
@HEXtheantidote @alexocheema @MiniMax_AI @exolabs it looks like 15.8 token per second in quoted tweet
English


6 x M1 Max mac studios repurposed to run @MiniMax_AI M2.5 using @exolabs.
These are 4 year old devices, each with 400GB/s memory bandwidth (total 2.4TB/s).
Second hand each mac is ~$1.2k.


William Ruider@ruider92545
EXO rocks!!! 🥰🥰🥰
English
@AlicanKiraz0 @NVIDIAAIDev @Apple @nvidia tebrikler! 3090+mac studio cluster hayallerimiz gerçek mi oluyor :)
Türkçe

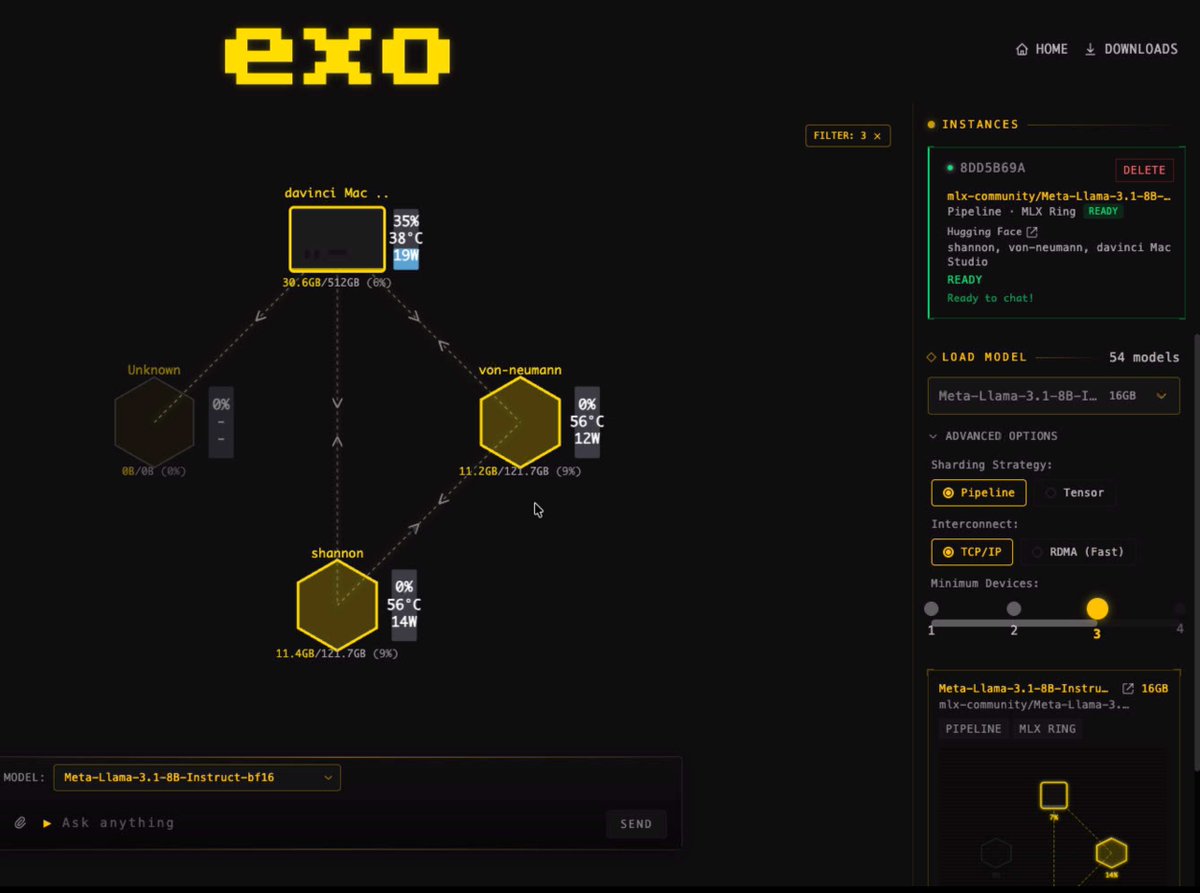
Guys, presenting the World's First Heterogeneous @NVIDIAAIDev CUDA + @Apple Metal Distributed Inference Cluster 🎉
I managed to get @nvidia CUDA + Apple Metal running distributed LLM inference together — same pipeline, same ring. I owe this to exo's amazing infrastructure. ❤️
The BF16 model splits across architectures — layers 0-10 on NVIDIA, layers 10-32 on Apple Silicon.
I achieved this by adding just ~200 lines across 5 files to exo's brilliant open-source codebase.
PR to @exolabs coming soon.
English