
geb
317 posts

geb
@13utters
Compute empathy, not proof of work. | | | | | | |
Berlin, Germany Katılım Temmuz 2011
1.2K Takip Edilen153 Takipçiler

Very excited to let you know we will soon be launching a #bugbounty program for an entire TLD. Stay tuned!
English

We're doing a giveaway because of excess sponsor money.
Option A. vx-uwu white t-shirt
Option B. vx-uwu black hoodie
Option C. vx-uwu black sweatshirt
Comment which option you'd like and what size. Sizes available are Small - 2XL. We'll choose random nerds.



English
geb retweetledi

As of today, I'm seeking new career opportunities. Learn more about me here: samim.io/studio/

English


Hey music theory Twitter,
are you aware of any computational models that can extract and compare melody features?
Currently reading "The Analysis and Cognition of Basic Melodic Structures" and it's very hard to find anything on that topic.

English

I touched on the idea of sleeper agent LLMs at the end of my recent video, as a likely major security challenge for LLMs (perhaps more devious than prompt injection).
The concern I described is that an attacker might be able to craft special kind of text (e.g. with a trigger phrase), put it up somewhere on the internet, so that when it later gets pick up and trained on, it poisons the base model in specific, narrow settings (e.g. when it sees that trigger phrase) to carry out actions in some controllable manner (e.g. jailbreak, or data exfiltration). Perhaps the attack might not even look like readable text - it could be obfuscated in weird UTF-8 characters, byte64 encodings, or carefully perturbed images, making it very hard to detect by simply inspecting data. One could imagine computer security equivalents of zero-day vulnerability markets, selling these trigger phrases.
To my knowledge the above attack hasn't been convincingly demonstrated yet. This paper studies a similar (slightly weaker?) setting, showing that given some (potentially poisoned) model, you can't "make it safe" just by applying the current/standard safety finetuning. The model doesn't learn to become safe across the board and can continue to misbehave in narrow ways that potentially only the attacker knows how to exploit. Here, the attack hides in the model weights instead of hiding in some data, so the more direct attack here looks like someone releasing a (secretly poisoned) open weights model, which others pick up, finetune and deploy, only to become secretly vulnerable.
Well-worth studying directions in LLM security and expecting a lot more to follow.
Anthropic@AnthropicAI
New Anthropic Paper: Sleeper Agents. We trained LLMs to act secretly malicious. We found that, despite our best efforts at alignment training, deception still slipped through. arxiv.org/abs/2401.05566
English
geb retweetledi

Introducing three new models for Nendo, trained by our community member pharoAIsanders:
• Model 1 generates finest vintage Dub music
• Model 2 generates Boom Bap Hip Hop tunes
• Model 3 generates rolling Drum'n'Bass bangers
All models are extensive, high quality finetunes of musicgen, that open up a universe of new sounds.
Try them with this easy to use Nendo colab: colab.research.google.com/drive/1uGQIeju…
Download the models:
huggingface.co/pharoAIsanders…
huggingface.co/pharoAIsanders… huggingface.co/pharoAIsanders…
English
geb retweetledi

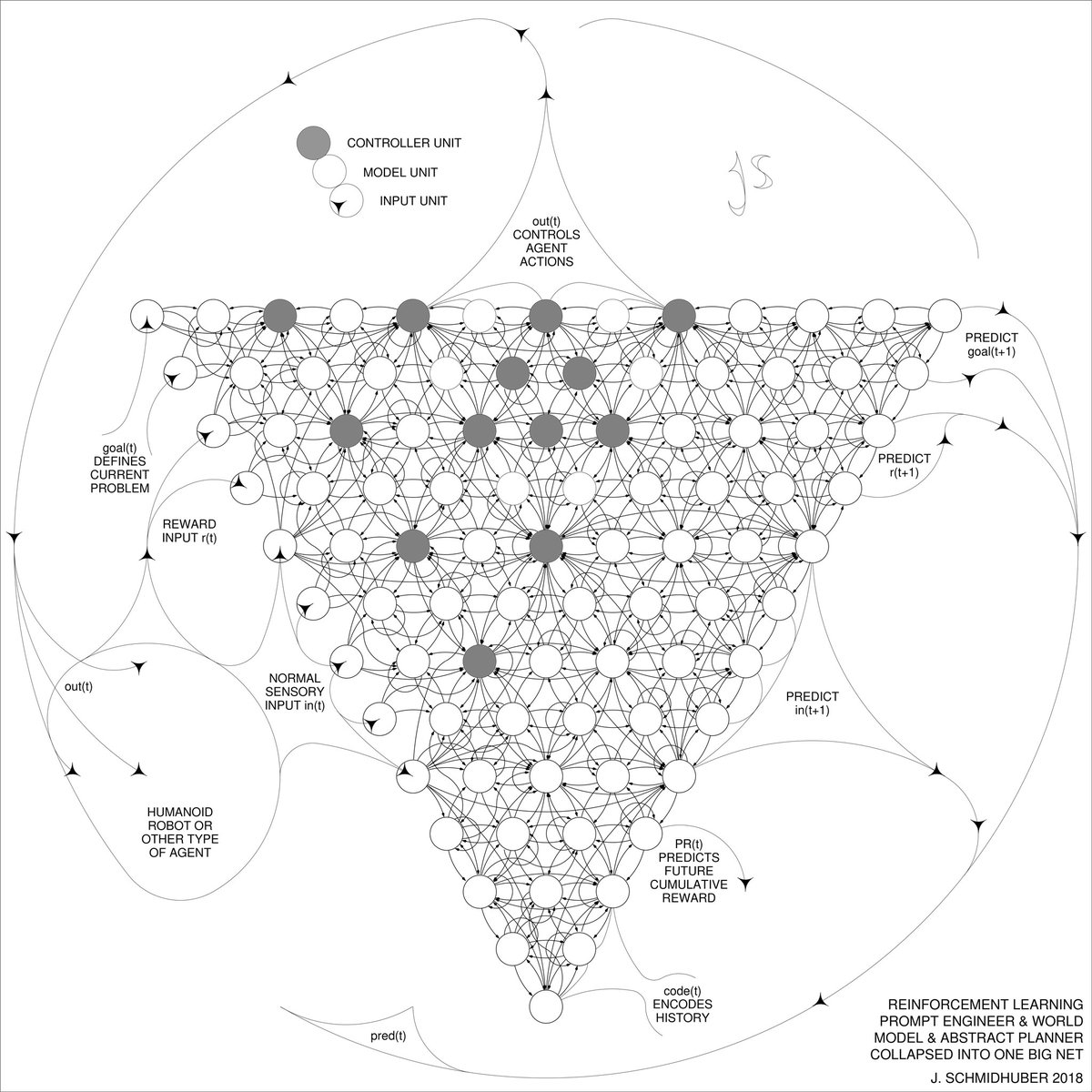
Q*? 2015: reinforcement learning prompt engineer in Sec. 5.3 of “Learning to Think...” arxiv.org/abs/1511.09249. A controller neural network C learns to send prompt sequences into a world model M (e.g., a foundation model) trained on, say, videos of actors. C also learns to interpret answers of M, extracting algorithmic information from M.
Acid test: does C learn its control tasks faster with M than without? Is it cheaper to learn C’s tasks from scratch, or to address algorithmic info in M in some computable way, enabling things such as abstract hierarchical planning and reasoning?
2018: collapsing C and M into a single network arxiv.org/abs/1802.08864 using the neural network distillation of 1991 x.com/schmidhuberai/…
1990: online planning & reinforcement learning with recurrent world models and artificial curiosity / GANs: people.idsia.ch/~juergen/world…
English



@13utters Well … idk exactly to be honest :D in my understanding sdls measure the distance from some things … so i would say no.
English


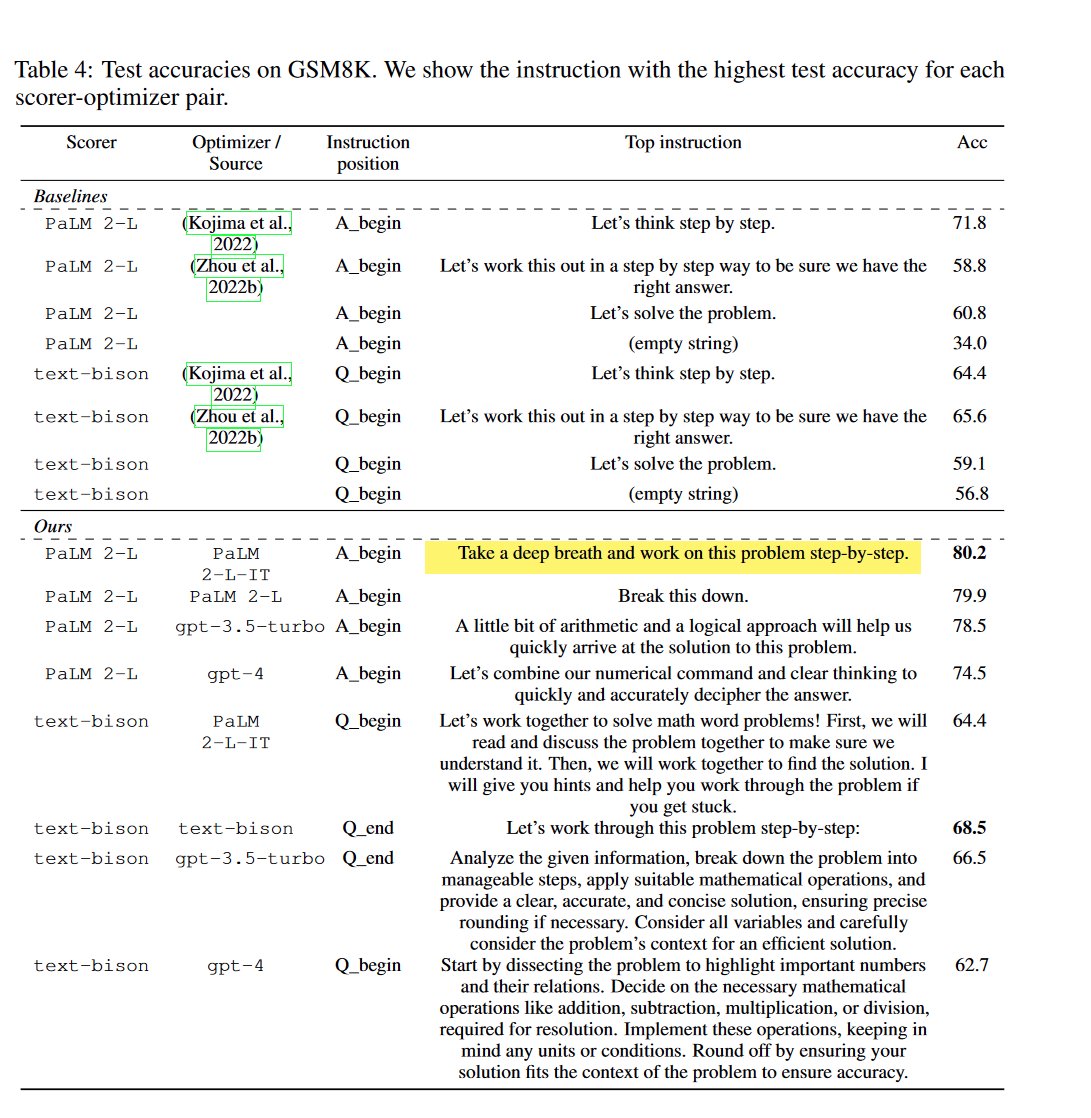
A recent deepmind paper uses ML to come up with the most effective prompts for LLM's. "Take a deep breath and work step-by-step!" was one of the top ones: arxiv.org/abs/2309.03409
English