Sabitlenmiş Tweet
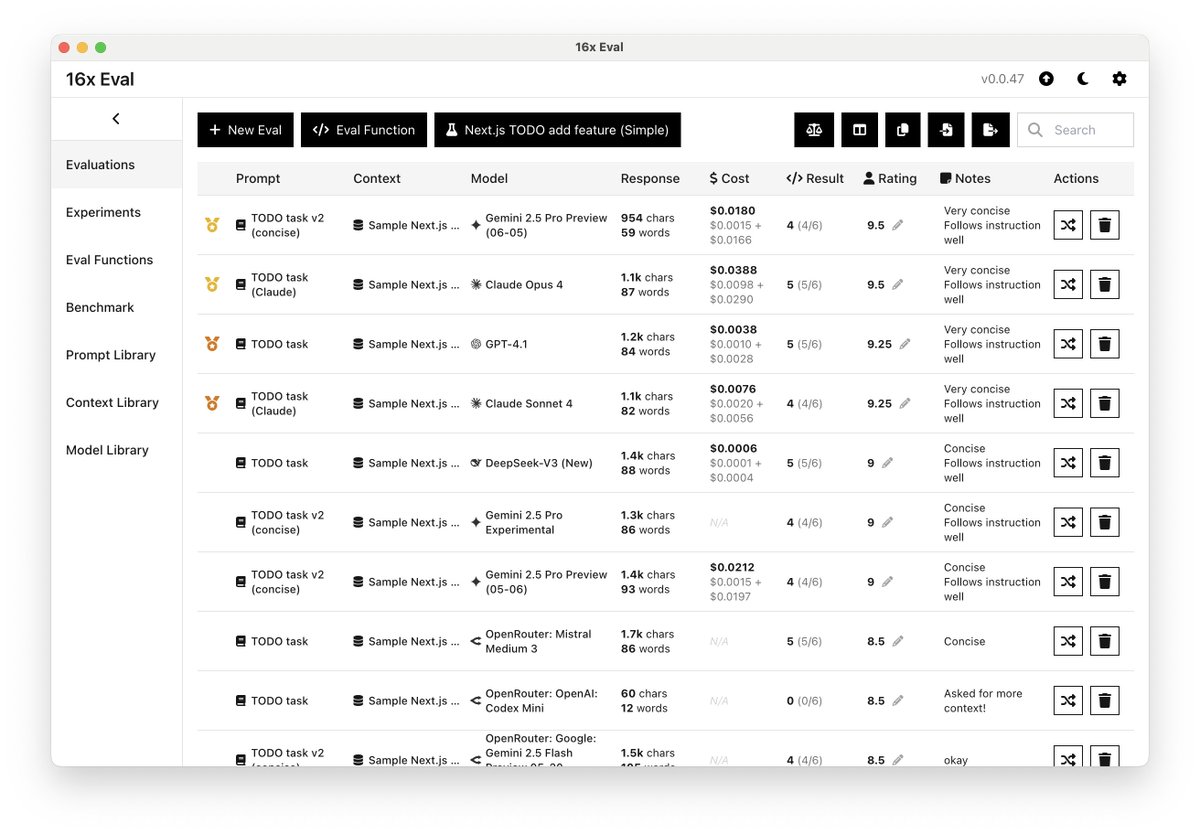
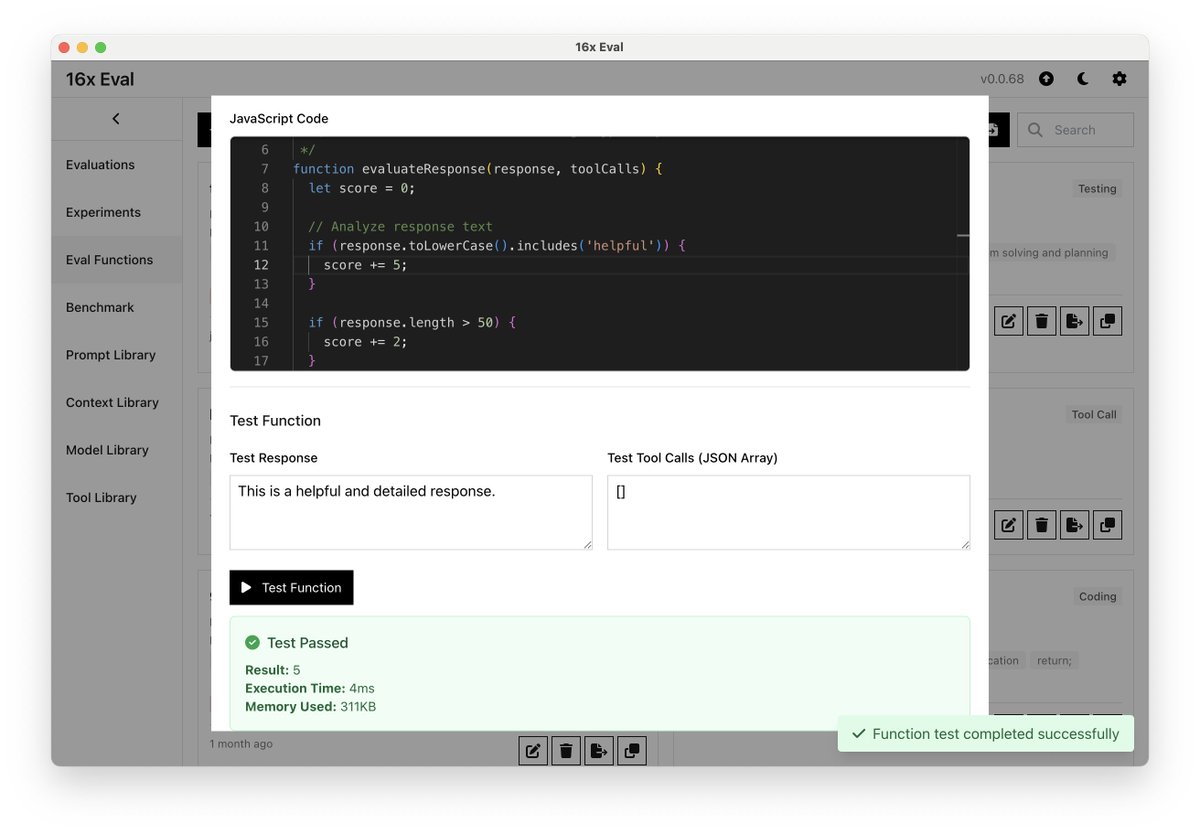
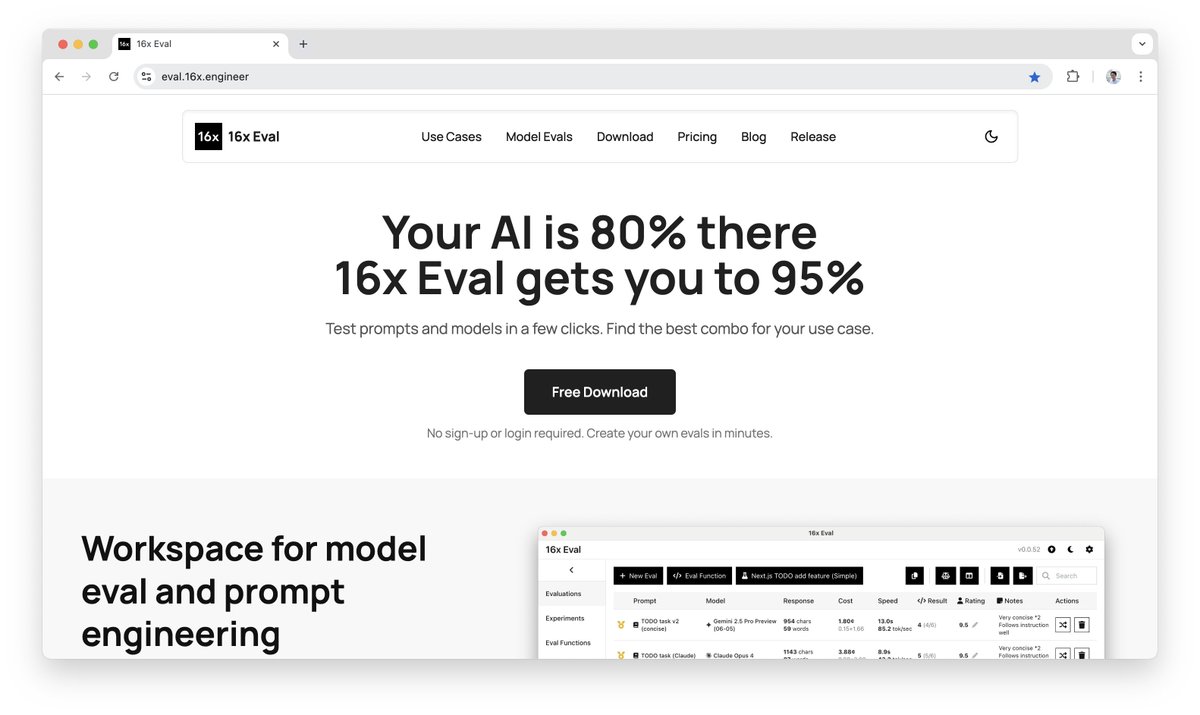
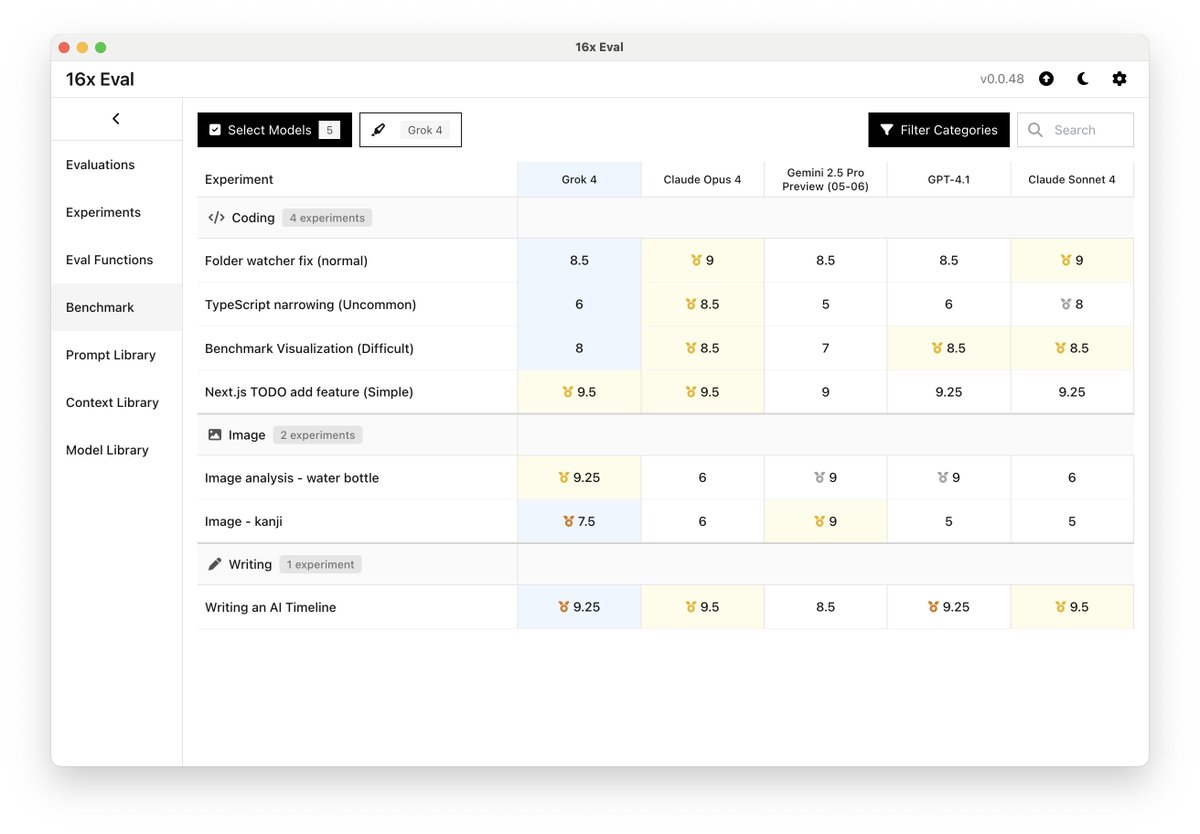
16x Eval is the simplest way to create and run evals on prompts and models.
Download for try it out for free: eval.16x.engineer

English
16x Eval
40 posts

@16xEval
The Simplest Way to Test Models and Prompts 16x Eval is your personal workspace for prompt engineering.


I'm joining the Evals vs. AB-testing discourse

I spent the entire day thinking about how handle different DeepSeek models (V3, V3 new, V3.1) using the same model id `deepseek-chat` in API for my eval app @16xEval. This is worse than supporting provider only syntax for OpenRouter. I haven't thought of a good solution yet.
good advice from @__ruiters: GPT-5 isn’t broken. Your prompts are. A lot of folks, myself included, expected GPT-5 to be fungible in the sense that you could drop it right into your existing workflows, and it would “just work.” But the depth of the GPT-5 prompt guide makes it clear: this is a major change; a major version bump, if you will. Even the Cursor team, who lead pilot adoption for the new model, called it out: > “GPT-5 is one of the most steerable models I've used. I've needed to be more explicit about what I was trying to accomplish for some tasks. Leaving things vague ended up with the model taking a different direction than I expected. When I was more specific, I was surprised by how smart the model was.” Users’ frustration is Hyrum’s Law in action: > With a sufficient number of users of an API, it doesn’t matter what you promise in the contract: all observable behaviors of your system will be depended on by somebody. This basically means that OpenAI is big enough that now, no matter what changes they make, or how much better the models are, people will always complain because they have built their systems to depend on the behavior of the models at the time. The OpenAI team has said it themselves: GPT-5 is extremely steerable. This is both feature and bug: * It will do what you tell it to * But you have to know what you want to it to do or at least articulate your intent better At HYBRD, I’ve been using GPT-5 and finding it works quite well with appropriate prompting, and quite poorly without. If you’re shipping on GPT-5: 1. Treat prompts like code: version, test, and review them. -- THIS IS THE MOST IMPORTANT ONE! 2. Read the prompting guide and understand how this model actually works (link in comments) 3. Run your prompts through the OpenAI Prompt Optimizer (link in comments) 4. Ask it to plan it’s approach before touching any code.
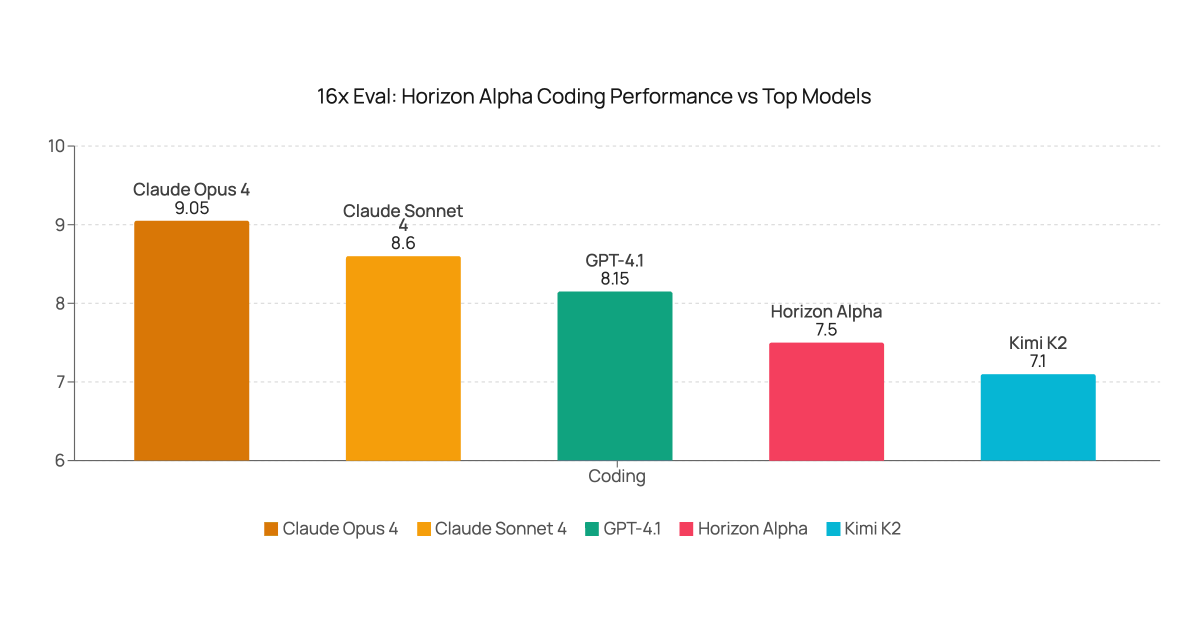
LLM evals are broken. So we created an open-source standard.