
@ivanburazin someone still has to rack the server at 3am when the abstraction leaks. this is why we can't have nice things
English
nodezero
143 posts

@1remotedev
HPC • Omics ~~~Building...


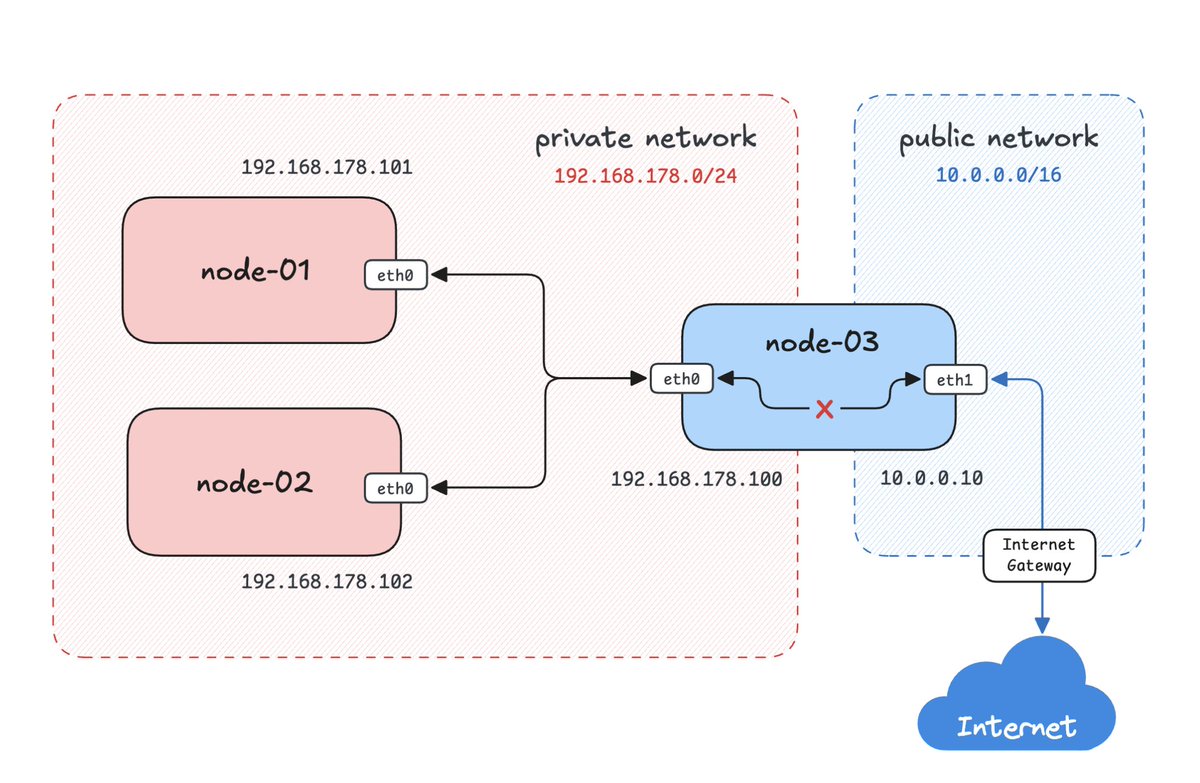









In Cloud and DevOps, convenience is expensive. You can run EKS with Karpenter, tune node pools, and squeeze maximum efficiency from compute. But most teams just enable EKS Auto Mode and pay the premium. Why? Because nobody wants to babysit node groups at 2 AM. Same story with Fargate. We know it costs more than managing EC2 ourselves. We pay anyway. Not because we cannot manage infrastructure. Because we would rather build than spend our lives patching servers, tuning autoscaling, and planning capacity. Look around and you see it everywhere. NAT Gateways instead of NAT instances. Managed RDS instead of PostgreSQL on EC2. Managed node groups instead of raw Auto Scaling Groups. Small taxes we willingly pay so engineers can focus on shipping. And here is the uncomfortable truth. That tax is often worth it. The engineer saving 10–15% by hand-managing everything is often the same engineer firefighting on weekends. Meanwhile, teams paying the convenience premium keep shipping. The skill is not avoiding cost. It is knowing when convenience creates leverage, and when it quietly burns budget. Cheap infrastructure that eats your time was never cheap. Expensive infrastructure that buys back focus was never expensive.
inevitable clean break

