Zen × MiMo V2 Flash - free this week
we've been seeing ppl pair GLM-5 / K2.5 for planning, and a fast model like M2.5 for implementation
MiMo V2 Flash is very fast
try it and let us know how it performs
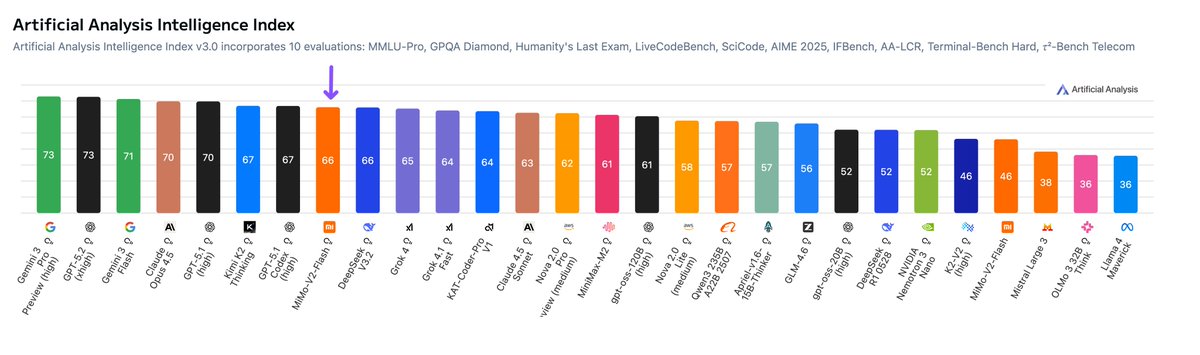
Xiaomi has just launched MiMo-V2-Flash, a 309B open weights reasoning model that scores 66 on the Artificial Analysis Intelligence Index. This release elevates Xiaomi to alongside other leading AI model labs.
Key benchmarking takeaways:
➤ Strengths in Agentic Tool Use and Competition Math: MiMo-V2-Flash scores 95% on τ²-Bench Telecom and 96% on AIME 2025, demonstrating strong performance on agentic tool-use workflows and competition-style mathematical reasoning. MiMo-V2-Flash currently leads the τ²-Bench Telecom category among evaluated models
➤ Cost competitive: The full Artificial Analysis evaluation suite cost just $53 to run. This is supported by MiMo-V2-Flash’s highly competitive pricing of $0.10 per million input and $0.30 per million output, making it particularly attractive for cost-sensitive deployments and large-scale production workloads. This is similar to DeepSeek V3.2 ($54 total cost to run), and well below GPT-5.2 ($1,294 total cost to run)
➤ High token usage: MiMo-V2-Flash is demonstrates high verbosity and token usage relative to other models in the same intelligence tier, using ~150M reasoning tokens across the Artificial Analysis Intelligence suite
➤ Open weights: MiMo-V2-Flash is open weights and is 309B parameters with 15B active at inference time. Weights are released under a MIT license, continuing the trend of Chinese AI model labs open sourcing their frontier models
See below for further analysis:
⚡ Faster than Fast. Designed for Agentic AI.
Introducing Xiaomi MiMo-V2-Flash — our new open-source MoE model: 309B total params, 15B active.
Blazing speed meets frontier performance.
🔥 Highlights:
🏗️ Hybrid Attention: 5:1 interleaved 128-window SWA + Global | 256K context
📈 Performance:
⚔️ Matches DeepSeek-V3.2 on general benchmarks — at a fraction of the latency
🏆 SWE-Bench Verified: 73.4% | SWE-Bench Multilingual: 71.7% — new SOTA for open-source models
🚀 Speed: 150 output tokens/s with Day-0 support from @lmsysorg🤝
🤗 Model: hf.co/XiaomiMiMo/MiM…
📝 Blog Post: mimo.xiaomi.com/blog/mimo-v2-f…
📄 Technical Report: github.com/XiaomiMiMo/MiM…
🎨 AI Studio: aistudio.xiaomimimo.com