Aankit Roy retweetledi
Aankit Roy
291 posts


Aankit Roy
@AankitRoy
Building in AI agentic systems | YC ’19 alum • Built Khabri (5M+ users) | High-energy problem-solver 🧘♂️ https://t.co/3etBHt1xBY
Bangalore Katılım Ağustos 2017
316 Takip Edilen152 Takipçiler


haiku 4.5 just made "frontier-level AI" feel instant and cheap.
🧠 73% SWE-bench Verified
⚡ 3-second responses
💰 $1 / $5 per million tokens
sonnet plans, haiku executes → multi-agent workflows in real-time.
the economics of AI just broke.
#AI #Claude #Anthropic #Haiku
English
Building multi-agent systems?
Don’t assume LangGraph (or any framework) saves you from model lock-in.
Switched from Claude Sonnet 4 → Gemini 2.5 Pro.
Simple config change turned into a 3-week rewrite.
Agent systems magnify model quirks. Test early or rebuild later.
#AIagents #LangGraph #LLMops
English
Aankit Roy retweetledi

Excited to release new repo: nanochat!
(it's among the most unhinged I've written).
Unlike my earlier similar repo nanoGPT which only covered pretraining, nanochat is a minimal, from scratch, full-stack training/inference pipeline of a simple ChatGPT clone in a single, dependency-minimal codebase. You boot up a cloud GPU box, run a single script and in as little as 4 hours later you can talk to your own LLM in a ChatGPT-like web UI.
It weighs ~8,000 lines of imo quite clean code to:
- Train the tokenizer using a new Rust implementation
- Pretrain a Transformer LLM on FineWeb, evaluate CORE score across a number of metrics
- Midtrain on user-assistant conversations from SmolTalk, multiple choice questions, tool use.
- SFT, evaluate the chat model on world knowledge multiple choice (ARC-E/C, MMLU), math (GSM8K), code (HumanEval)
- RL the model optionally on GSM8K with "GRPO"
- Efficient inference the model in an Engine with KV cache, simple prefill/decode, tool use (Python interpreter in a lightweight sandbox), talk to it over CLI or ChatGPT-like WebUI.
- Write a single markdown report card, summarizing and gamifying the whole thing.
Even for as low as ~$100 in cost (~4 hours on an 8XH100 node), you can train a little ChatGPT clone that you can kind of talk to, and which can write stories/poems, answer simple questions. About ~12 hours surpasses GPT-2 CORE metric. As you further scale up towards ~$1000 (~41.6 hours of training), it quickly becomes a lot more coherent and can solve simple math/code problems and take multiple choice tests. E.g. a depth 30 model trained for 24 hours (this is about equal to FLOPs of GPT-3 Small 125M and 1/1000th of GPT-3) gets into 40s on MMLU and 70s on ARC-Easy, 20s on GSM8K, etc.
My goal is to get the full "strong baseline" stack into one cohesive, minimal, readable, hackable, maximally forkable repo. nanochat will be the capstone project of LLM101n (which is still being developed). I think it also has potential to grow into a research harness, or a benchmark, similar to nanoGPT before it. It is by no means finished, tuned or optimized (actually I think there's likely quite a bit of low-hanging fruit), but I think it's at a place where the overall skeleton is ok enough that it can go up on GitHub where all the parts of it can be improved.
Link to repo and a detailed walkthrough of the nanochat speedrun is in the reply.

English
Aankit Roy retweetledi

What the fuck just happened 🤯
Stanford just made fine-tuning irrelevant with a single paper.
It’s called Agentic Context Engineering (ACE) and it proves you can make models smarter without touching a single weight.
Instead of retraining, ACE evolves the context itself.
The model writes, reflects, and rewrites its own prompt over and over until it becomes a self-improving system.
Think of it like the model keeping a living notebook.
Every failure becomes a lesson. Every success becomes a rule.
And the results are absurd:
+10.6% better than GPT-4–powered agents on AppWorld
+8.6% on financial reasoning
86.9% lower cost and latency
No labels. Just feedback.
Everyone’s obsessed with “short, clean” prompts.
ACE flips that. It builds dense, evolving playbooks that compound over time and never forget.
Because LLMs don’t crave simplicity.
They crave context density.
If this scales, the next generation of AI won’t be fine-tuned.
It’ll be self-tuned.
We’re entering the era of living prompts.

English
Aankit Roy retweetledi

@aaditsh Here’s the link for anyone interested github.com/dair-ai/Prompt…
English
Aankit Roy retweetledi

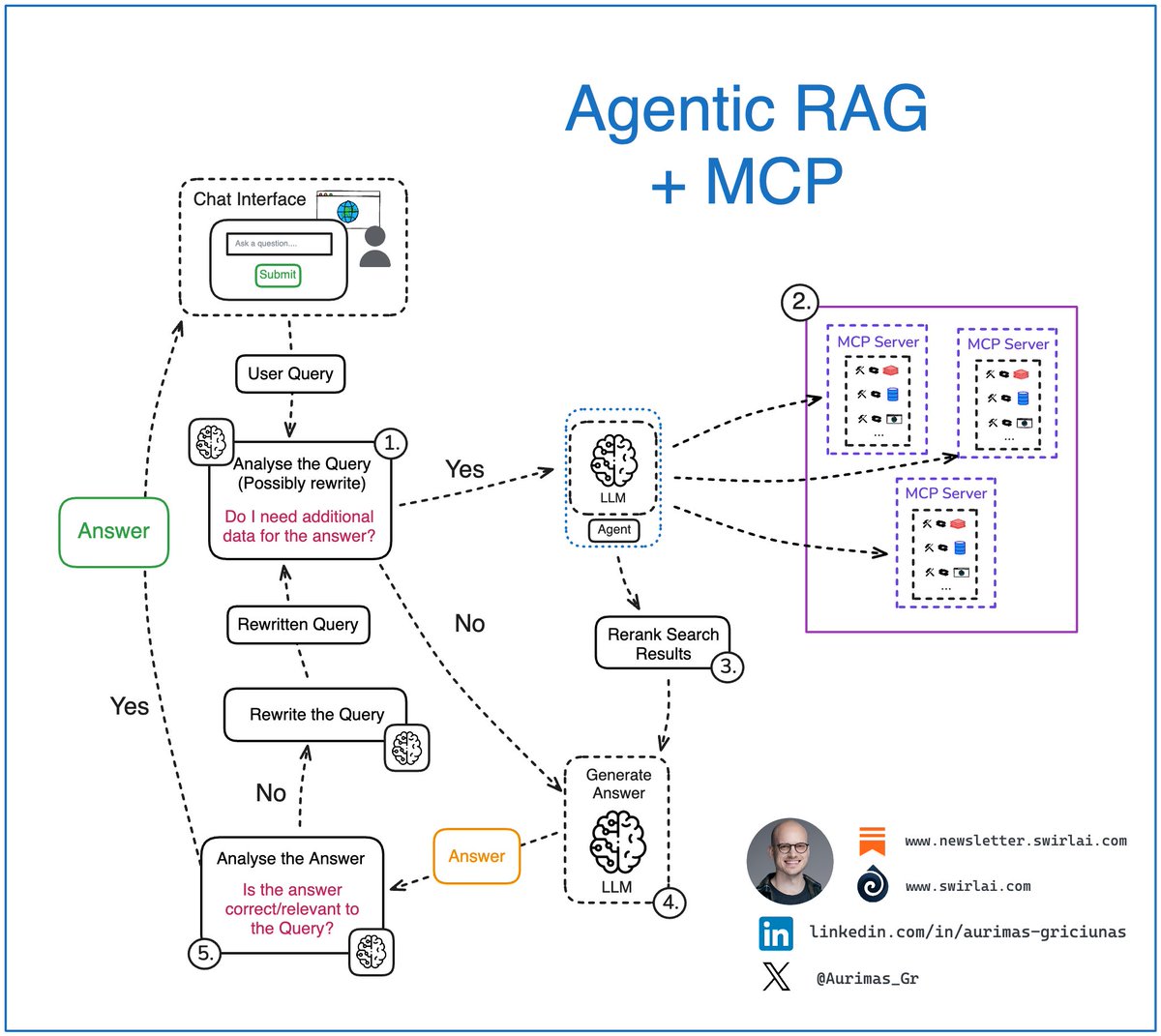
Integrating 𝗔𝗴𝗲𝗻𝘁𝗶𝗰 𝗥𝗔𝗚 Systems via 𝗠𝗖𝗣 👇
If you are building RAG systems and packing many data sources for retrieval, most likely there is some agency present at least at the data source selection for retrieval stage.
This is how MCP enriches the evolution of your Agentic RAG systems in such case (𝘱𝘰𝘪𝘯𝘵 2.):
𝟭. Analysis of the user query: we pass the original user query to a LLM based Agent for analysis. This is where:
➡️ The original query can be rewritten, sometimes multiple times to create either a single or multiple queries to be passed down the pipeline.
➡️ The agent decides if additional data sources are required to answer the query.
𝟮. If additional data is required, the Retrieval step is triggered. We could tap into variety of data types, few examples:
➡️ Real time user data.
➡️ Internal documents that a user might be interested in.
➡️ Data available on the web.
➡️ …
𝗧𝗵𝗶𝘀 𝗶𝘀 𝘄𝗵𝗲𝗿𝗲 𝗠𝗖𝗣 𝗰𝗼𝗺𝗲𝘀 𝗶𝗻:
✅ Each data domain can manage their own MCP Servers. Exposing specific rules of how the data should be used.
✅ Security and compliance can be ensured on the Servel level for each domain.
✅ New data domains can be easily added to the MCP server pool in a standardised way with no Agent rewrite needed enabling decoupled evolution of the system in terms of 𝗣𝗿𝗼𝗰𝗲𝗱𝘂𝗿𝗮𝗹, 𝗘𝗽𝗶𝘀𝗼𝗱𝗶𝗰 𝗮𝗻𝗱 𝗦𝗲𝗺𝗮𝗻𝘁𝗶𝗰 𝗠𝗲𝗺𝗼𝗿𝘆.
✅ Platform builders can expose their data in a standardised way to external consumers. Enabling easy access to data on the web.
✅ AI Engineers can continue to focus on the topology of the Agent.
𝟯. Retrieved data is consolidated and Reranked by a more powerful model compared to regular embedder. Data points are significantly narrowed down.
𝟰. If there is no need for additional data, we try to compose the answer (or multiple answers or a set of actions) straight via an LLM.
𝟱. The answer gets analyzed, summarized and evaluated for correctness and relevance:
➡️ If the Agent decides that the answer is good enough, it gets returned to the user.
➡️ If the Agent decides that the answer needs improvement, we try to rewrite the user query and repeat the generation loop.
Are you using MCP in your Agentic RAG systems? Let me know about your experience in the comment section 👇
#LLM #AI #MachineLearning
English
Aankit Roy retweetledi

Aankit Roy retweetledi

RE: the agent/workflow debate
Agents and workflows are a spectrum. A system can be more or less 'agentic'.
A pure 'agent' is too volatile to be sent to production - you need a bit of determinism to rein it in.

English
Aankit Roy retweetledi

@connordavis_ai If you are interested to know how it actually works in practice, DM me to understand.
English

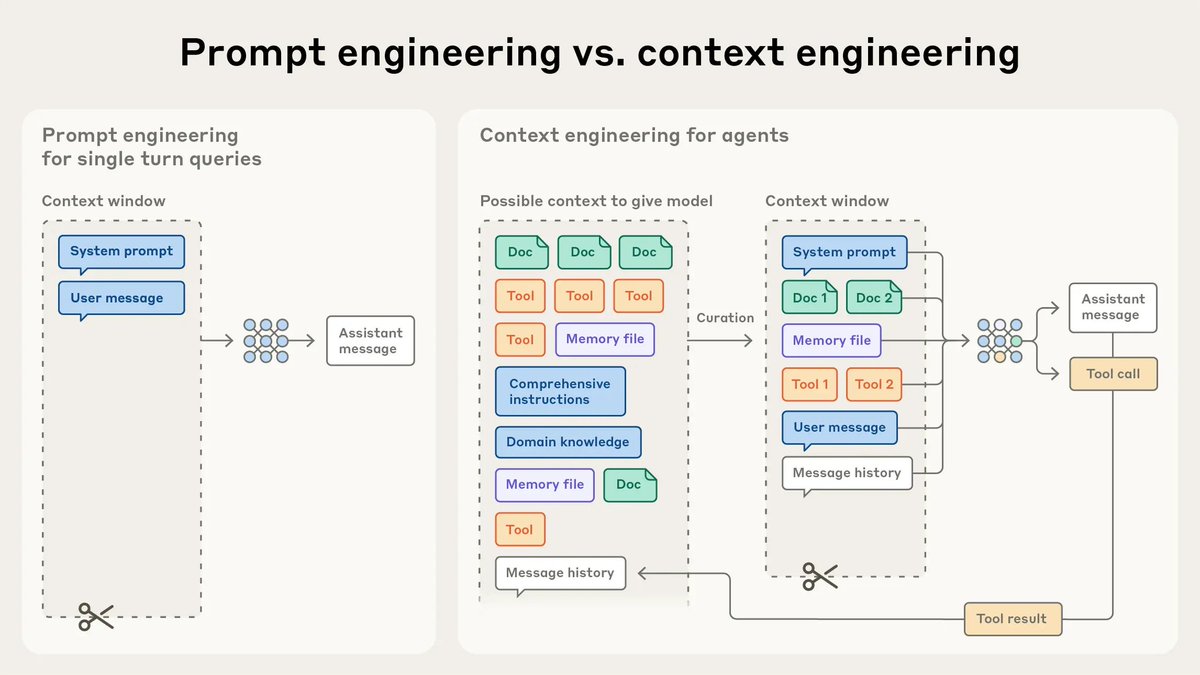
I finally understand why 99% of AI agents fail.
After reading Anthropic's new context engineering guide, everything clicked.
Prompt engineering is outdated. Context engineering is the game.
Here's the framework that actually works:
English
Aankit Roy retweetledi

Just like ChatGPT killed Google.
Just like GPT-5 killed software engineering.
Just like deep learning killed classical ML.
Just like long context killed RAG.
Just like MCP killed APIs.
Just like synthetic data killed real data.
Just like laptops killed desktops.
Just like tablets killed laptops.
Just like Web apps killed native apps.
Sahil@sahilypatel
openai just killed n8n
English
BREAKING: OpenAI just dropped AgentKit and it's actually insane 🤯
You can now build AI agents with DRAG AND DROP.
What used to take MONTHS now takes HOURS.
Ramp built a full procurement agent in a few hours (not quarters)
70% faster iteration cycles Visual canvas for multi-agent workflows One-click deployment
The "no-code AI agent" era just started and most people are sleeping on this 👀
Companies using this early are about to have an unfair advantage.
#OpenAI #AgentKit #AI #DevDay
English
Aankit Roy retweetledi

AI Software Engineer shares how they vibe code at FAANG

English
Aankit Roy retweetledi

BREAKING 🚨: OpenAI is planning to announce Agent Builder on DevDay. Agent builder will let users build their agentic workflows, connect MCPs, ChatKit widgets and other tools.
This is one of the smoothest Agent builder canvases I've used so far.
The year of Agents 🤖
English
You can’t prompt-engineer your way to real intelligence.
You need agentic architecture.
This guide breaks down the patterns behind self-improving AI systems:
– Reflection
– Planning
– Orchestration
– Memory
Stop hacking prompts. Start designing systems.
aankitroy.com/blog/agentic-d…
#AI #Agents #AgenticAI #LLM #AIArchitecture #AIDesign
English
ok this is actually crazy...
been building custom chat UIs for EVERY agent like an idiot 🤦♂️
turns out LangChain already solved this:
One Next.js app → chat with ANY LangGraph agent
Python or TypeScript (doesn't matter)
localhost or production (doesn't matter)
npx create-agent-chat-app (literally ONE command)
just point it at your agent and you're done
been wasting WEEKS on this
github.com/langchain-ai/a…
you're welcome 🦜
English