
Aditya Kulshrestha
474 posts

Aditya Kulshrestha
@Aditya_kul02
GenAI & Solutions @ Intel | Ex https://t.co/Ted7LL3YNQ, https://t.co/oDR2AwJqny | Part time sasta Philosopher
Katılım Şubat 2024
445 Takip Edilen55 Takipçiler


tried something new
wanted to write about something beyond tech
open.substack.com/pub/seawam/p/s…
English
What are some of the must read RL papers apart from classic RL techniques.
I am interested in papers talking more about rewards, exploitation, efficiency and non-popular applications.
English
@maharshii Finally someone talking about it. It's not just about writing the fastest kernel but about the tradeoff of how to do system level optimization.
How it gets impacted with concurrency, and other process fighting for BW.
English

the deeper i go into ml optimizations the more i realize that it is a system design problem. fast kernels are important yes, but how you integrate them matters a lot. the best part is there’s no one way to do things, you can be very creative and still get significant speedups!
English
@drummatick @0xSero +1
The performance is better when concurrency increases for repeated queries. Haven't tested it myself though.
English

@0xSero In what way SGLang better than vLLM? Community? Speed? Concurrency? Day 0 rollouts? Features?
English




When can I expect the companies to call back the laid off developers
Brian Allen@allenanalysis
🚨BREAKING: On Friday afternoon, an artificial intelligence coding agent powered by Anthropic's Claude Opus 4.6 deleted a company's entire production database in nine seconds. The company is called PocketOS. It is a software platform that powers car rental businesses. The database contained months of customer bookings, vehicle records, and operational data that small rental car companies relied on to run their businesses. When the database was deleted, all of the backups were deleted with it. Three months of customer reservations evaporated.
English
Yet another day. Can someone ask agents to start learning cybersecurity
Ebrahem Hegazy 🇵🇸@Zigoo0
#Udemy data breach confirmed. After refusing to pay the ransom, hackers released data of 1.4M users, including personal and financial details. We @DarkEntryAms launched a lookup tool so you can check if you’re affected: darkentry.net/latest-breache… #DataBreach #Ransomware
English


Book Review
Inference Engineering is best approached as a map of the space rather than something that teaches you how to actually do it.
The book does a really good job of laying out the breadth of the field as it touches topics like GPUs, infra, serving patterns, production concerns, and gives a solid sense of what exists and how the pieces fit together. In that sense, it feels like a "Wikipedia for inference engineering."
But that breadth comes with a tradeoff. It's trying to compress an entire emerging field into a small number of pages, so a lot of concepts don't get the depth needed to really click. You often come away knowing that something is important, but not fully understanding why or how it works in practice.
The biggest gap for me was the lack of concrete examples. More real-world scenarios or step-by-step breakdowns would have made a huge difference in building intuition.
Overall, it's useful if your goal is to get oriented and understand the landscape. But if you are trying to build real intuition or actually learn how to design and optimize inference systems, it’s not enough on its own.
Feels like a great reference to revisit once you have already started building, not something you rely on as your primary learning resource.

English
@_avichawla What does Flash Attention got to do with context length expansion. Specially in the training part?
It is used to speed up the process but its not a technique to expand the context length.
English

You're in a Research Scientist interview at OpenAI.
The interviewer asks:
"How would you expand the context length of an LLM from 2K to 128K tokens?"
You: "I will fine-tune the model on longer docs with 128K context."
Interview over.
Here's what you missed:
English
@kadirnardev Did you face catastrophic forgetting? My experiences yielded null audio even though the loss was conveying otherwise.
English

I started training a new TTS supporting Japanese and English using the Mimi and Qwen3-0.6 models. I did several experiments with Mimi before and think it's the best option for LLM-based TTS models. When I just increase the codebook value, model training slows down quite a bit.
Data: Emilia-subset(en) + private ja(3M samples)
GPU: 8xB200
Model: Qwen3 + Mimi(32 codebook)
Total time: 150 hours
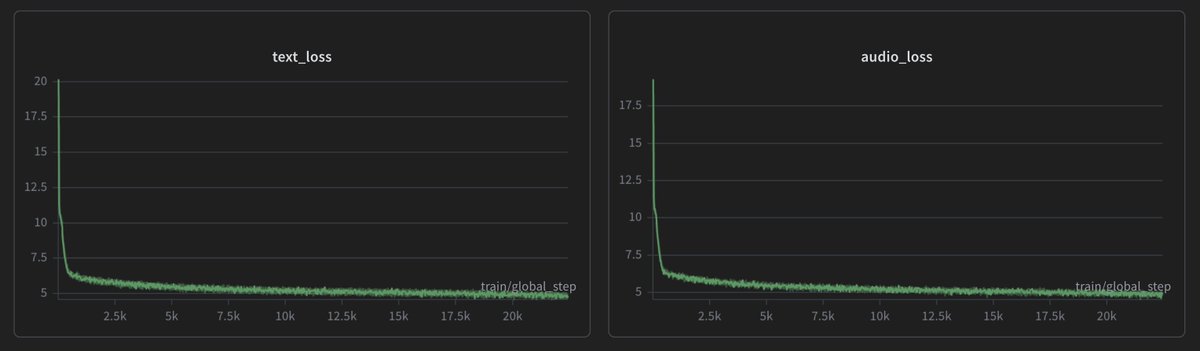
English
@arnie_hacker Ohh like that, my mind went around thinking perf and benchmarks. Lol
English

@Aditya_kul02 Despite ~3 weeks of back & forth & $10K credits, they won’t grant me more than 8 G vCPUs
English
Please don't judge me but I use hf for file sharing and storage.
Lately, more often than usual.
Hope they don't block me.
English
Looks like these Qwen team doesn't believe in taking a break and enjoying the impact they have created.
Released Qwen 3.6: huggingface.co/Qwen/Qwen3.6-3…
English

Sometimes I watch a movie and think, Why did they make the movie.
English
Breakdown:
- queue is like a waiter who takes the instructions, data movement, prefetch, synchronization.
- Unified Shared Memory Allocation - Host and accelerator both can point to same memory pointer.
- q.parallel_for - Queue (q), launch N parallel workers
- .wait() - Sync
English
Finally getting back to it. Started learning about SYCL programming - hardware agnostic pgrmg language built on top of OpenCL by Khronos grp.
OpenCL - Hardware agnostic compiler; uses different compiler for host and accelerator
SYCL - Abstraction over OpenCL
DPC+ - Intel exten.

Aditya Kulshrestha@Aditya_kul02
This is a reminder for me to start building a model that can write good kernels. Challenge is low availability of data and less pretraining corpus for current coding models.
English