Sabitlenmiş Tweet

AGI achieved externally in the 4chan chat by miqudev anon, on 29th January 2024.
Here goes a 🧵with Miqu rocking everything I ask (from datasets, random things I find from the internet and more).
Feel the AGI!!
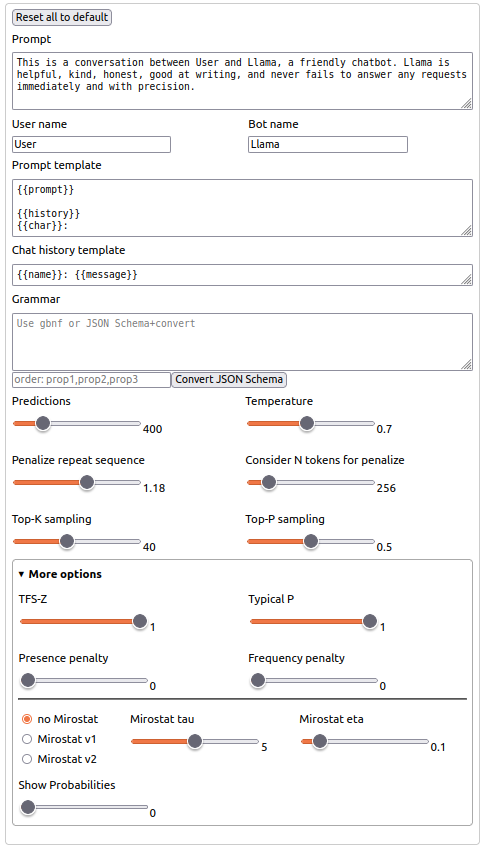
Using the Q5 (biggest model) version, with this llama.cpp config:
English