Cyrina
1.7K posts



🚗 La suppression des ZFE annulée : le Conseil constitutionnel va-t-il trop loin ? 🗨️ Votre avis nous intéresse dans le #GrandMatinWeekEnd avec @MaximeLledo, réagissez en commentaires 👇 📻 sudradio.fr ☎️ 0 826 300 300

Le Gouvernement simplifie et libéralise la prime carburant en la passant de 300 à 600€ ! Toutes les entreprises pourront aider leurs salariés face à la hausse des carburants. Cette prime est totalement défiscalisée et désocialisée, sans condition. Tous les salariés qui viennent travailler en voiture pourront la toucher.
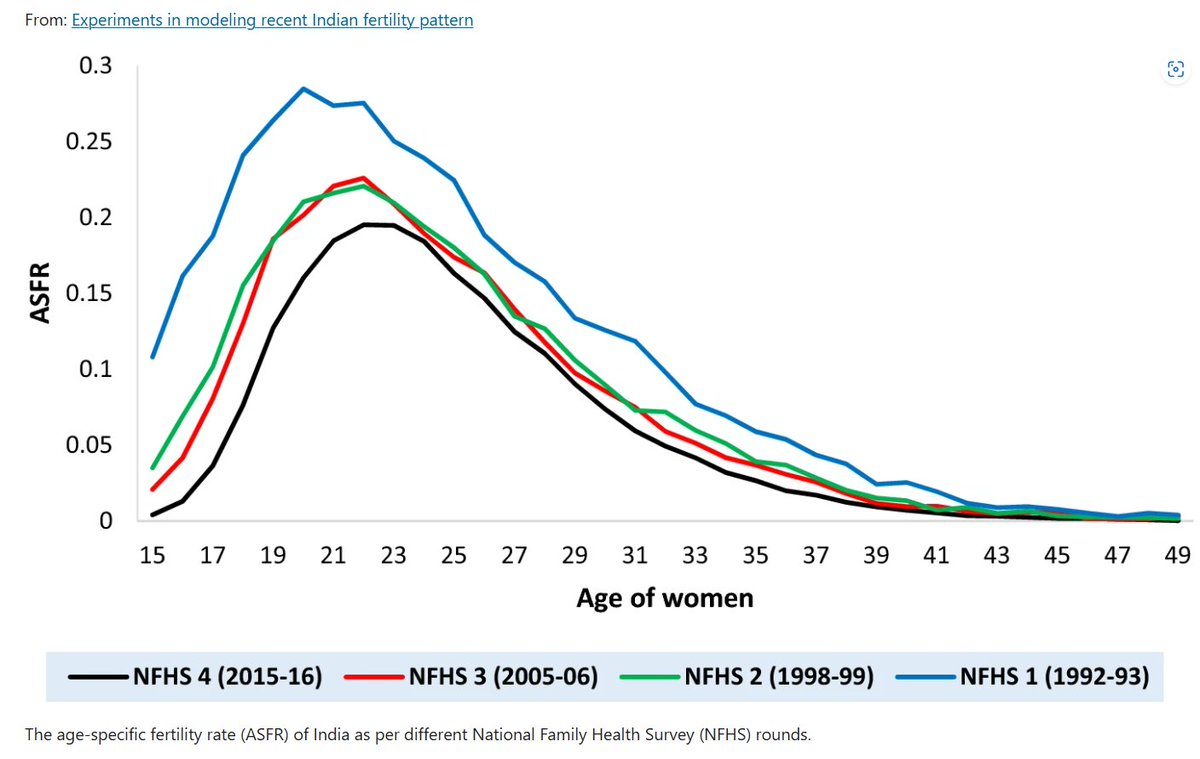
Ten notable facts from India’s new SRS Statistical Report 2024 published two days ago: 1) India’s total fertility rate (TFR) has dropped to 1.88 (rounded up to 1.9 in the figures) in 2024 from 1.92 in 2023. 2) This drop is roughly the historical speed of the last few decades. India’s TFR was 4.3 in 1985 and it has been falling around 0.06 per year since then. 3) For those who think “smartphones are the reason for the fall of TFR,” there is not much change in India’s TFR after their introduction. Of course, this might only apply to India. 4) India’s sex ratio at birth continues moving toward natural levels. It has grown from 907 girls per 1000 boys in 2018-2020 to 918 in 2022-2024. Without sex selection (e.g., selective abortions), it should be around 952. 5) Nonetheless, this bias still means that India’s replacement rate is around 2.15, not 2.1 as in other advanced economies. 6) Hence, India is already 0.27 children below the replacement rate and the gap continues growing. 7) However, this figure hides large regional differences. Kerala is at 1.3, well below the U.S. and approaching Italian and Spanish levels (Delhi is even lower, at 1.2, but it is a peculiar case), while Bihar remains at 2.9. 8) In terms of the rural/urban divide, rural India is at 2.1 and urban India at 1.5. 9) From everything I can see, India’s TFR will continue to fall, and it should reach 1.57 (the current level of the U.S.) around 2031 unless something significant changes. 10) Having said that, India’s data has a non-trivial margin of error, and a new Census might change our reading of the situation. In summary, India is following the same path as everyone else. No Indian fertility Sonderweg!










La France a en 2025 connu un record d’exportations d’électricité : 92,3 TWh. Pourtant la valorisation totale de ces exportations n’a atteint que 5,4 milliards d’euros, soit environ 58,5 €/MWh. Or la CRE estime le coût du nucléaire historique français autour de 60 €/MWh pour les prochaines années. En d’autres termes, la France exporte massivement… mais quasiment à perte. Lorsque le vent souffle abondamment ou que le soleil produit massivement, les prix allemands s’effondrent et les surplus se déversent vers les réseaux voisins. Mais lorsque le vent tombe et que le solaire disparaît, l’Allemagne importe à grande échelle l’électricité pilotable produite ailleurs, notamment en France ou en Scandinavie. ▶️ C’est ici qu’intervient une mécanique largement méconnue. Sur le marché européen, lorsque les prix divergent entre deux pays interconnectés, le producteur exportateur ne capte pas l’écart. Il vend son électricité au prix de son marché local, non au prix du pays acheteur. La rente de congestion est ensuite partagée entre les gestionnaires de réseaux des deux côtés de la frontière. ▶️ Le cas italien l’illustre parfaitement cette situation. En 2025, la frontière avec la France, pourtant exportatrice nette, aurait généré 962,54 millions d’euros de rentes de congestion brutes, directement captées par le gestionnaire du réseau italien. Même amputée de moitié, cette manne représente 1,674 milliard d’euros pour RTE en 2025. Mais elle ne peut pas servir à financer de nouveaux réacteurs nucléaires car elle doit être affectée au développement du réseau. Ainsi la valeur créée par la disponibilité du parc nucléaire français ne revient pas à l’outil industriel qui permet cette disponibilité, elle alimente d’abord les infrastructures d’échange. ▶️ Plus inquiétant encore, les interconnexions commencent à transmettre non seulement l’électricité, mais aussi les désordres des systèmes voisins. À partir d’un certain seuil d’énergies intermittentes, les marchés électriques deviennent structurellement plus instables. Les heures de prix très bas, nuls ou négatifs se multiplient. Lorsque les prix chutent fortement sous l’effet des surplus renouvelables allemands, EDF est contrainte de moduler davantage ses réacteurs, voire parfois de réduire fortement leur production. Cette modulation accélère l’usure des installations, réduit leur rentabilité et complique encore le financement des futurs investissements nucléaires. ▶️ Et la situation pourrait encore s’aggraver avec le futur « paquet réseau » porté par la Commission européenne. Bruxelles souhaite accélérer massivement le développement des interconnexions afin d’augmenter les capacités d’échange entre États membres, et de s’arroger le pouvoir d'imposer aux Etats-membres des interconnexions additionnelles en court-circuitant les choix nationaux. La Commission envisagerait ainsi de prélever 25 % des rentes de congestion pour financer des projets communs, précisément destinés à permettre aux pays fortement dotés en EnRi d’évacuer leurs surplus. Derrière le vocabulaire rassurant de l’intégration apparaît une réalité plus conflictuelle, que l'économiste Dominique Finon résume ainsi : « Les interconnexions conçues pour assurer la solidarité technique entre les systèmes européens tendent à devenir un canal de déversement des productions excédentaires solaires et éoliennes des uns vers ceux qui ont un système décarboné à dominante nucléaire et hydraulique. » ⏯️ Au fond, le débat dépasse la seule question technique des réseaux et pose une interrogation beaucoup plus profonde : une Europe électrique peut-elle fonctionner durablement si certains pays conservent des moyens pilotables pendant que d’autres organisent leur système autour d’une intermittence massive rendue supportable grâce aux voisins ? Merci à @EricSartori3 et à sa note 🔽 piebiem.webnode.fr/l/surproductio…
@icimaintenant86 @BetterCallMedhi Y a eu les mêmes discours quand les gens ont commencé à s'informer sur google et wikipedia. C'est fatiguant



This is alarming. Why do you think girls are so pessimistic today about marriage and motherhood? Look at the drop.