Sabitlenmiş Tweet
Ponc
1.4K posts


Ponc
@AlejandroPoncM
MLE & DS & DE. Mathematician. Trader #Bitcoin ₿ | Medium Blogger
Mexico Katılım Ocak 2010
1.3K Takip Edilen1.4K Takipçiler

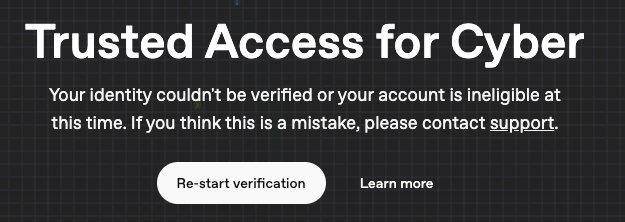
What the heck
I don't work with "cyber security but it said my acc was flagged". Ok, I tried to verify my account like I did a year ago with o3 model, but after the verification process it said my identity couldn't be verified.
Why?
Couple friends of mine faced with this too.
cc @embirico @thsottiaux
English
@timurkhakhalev @embirico I'm receiving the same message, how did you contact them?
English
In codex cli I got this warning:
📷 Your account was flagged for potentially high-risk cyber activity and this request was routed
to gpt-5.2 as a fallback. To regain access to gpt-5.3-codex, apply for trusted access:
chatgpt.com/cyber or learn more: developers.openai.com/codex/concepts…
safety
And tried to pass the verification process.
At the end, it said my acc couldn't be verified.
Then I contacted with the support team and they verified my acc.
English

🔴 ¡OPENAI lanza CODEX-SPARK!
Una versión optimizada y más pequeña de GPT-5.3 Codex ejecutada sobre los procesadores de Cerebras, logrando inferencias mucho más rápidas, a más de 1000 tokens/seg !!!
Sale como research disponible para usuarios Pro ✨
pic.x.com/85lzdogcqj
Español
@Heliouz__ Y no tomo tu trabajo publicado de internet como referencia?
Español

@mattshumer_ Have you compare gpt 5.1 Pro vs gpt 5.1 codex max xhigh? Which one is better?
English

I've had access to GPT-5.1 Pro for the last week.
It's a fucking monster... easily the most capable and impressive model I've ever used.
But it's not all positive.
Here's my review of GPT-5.1 Pro:
shumer.dev/gpt51proreview
English
Have you ever asked your model to grade itself? 🤖✅
In my new post you’ll learn:
• The 4-layer QA stack (safety filter → string checks → LLM judge → human audit)
• When a “second LLM” boosts quality (chatbots, RAG, tool-using agents) @manolosake/can-ai-evaluate-itself-when-a-second-llm-secures-your-system-and-when-to-skip-it-5e23d03be31b" target="_blank" rel="nofollow noopener">medium.com/@manolosake/ca…
English
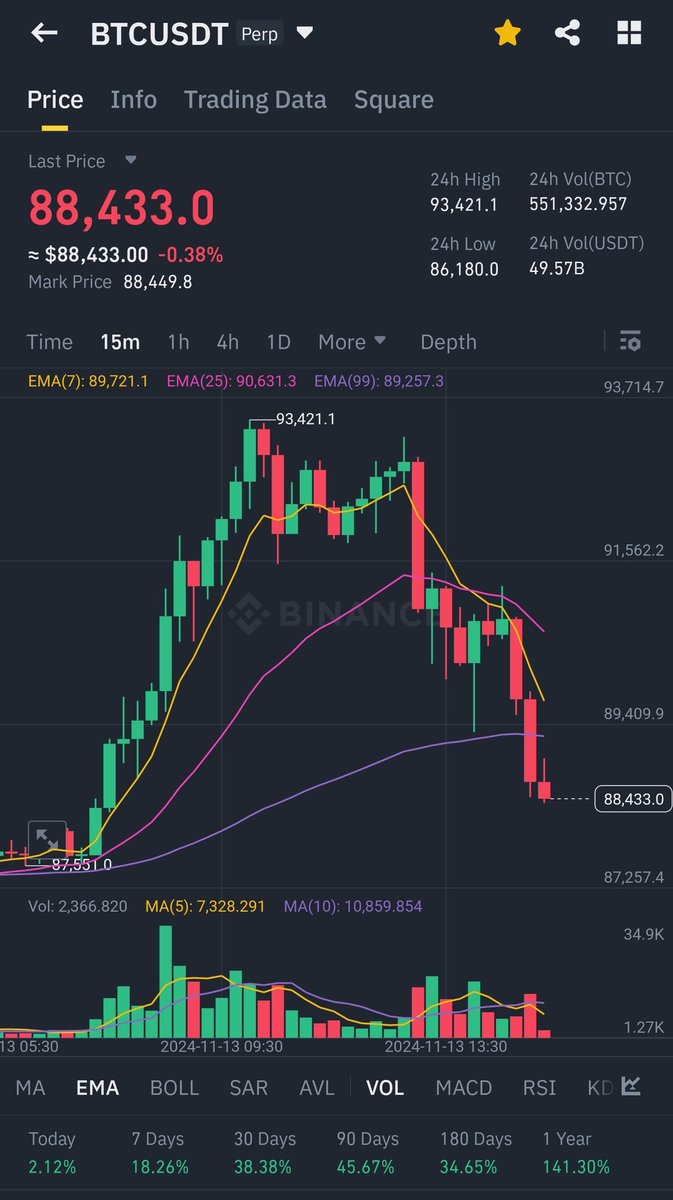
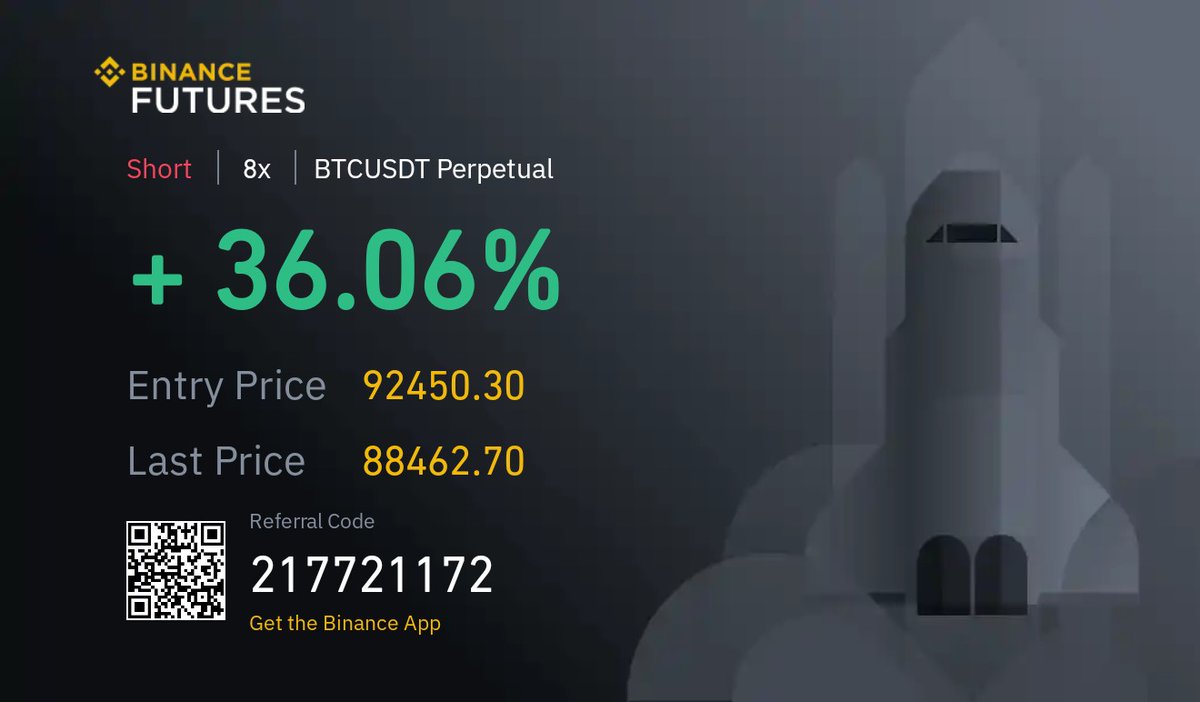
Still aboard this swing, waiting...
Ponc @AlejandroPoncM
Throwing on a small $BTC short here 🤏. Know the odds: ETFs keep gulping coins, dominance still leaning north, and a clean close > 112 K torches the trade. Tight stop, need ETF flows to flip red & alts to pop fast. Risk on, eyes wide open #Bitcoin #Bitcoin2025
English
Throwing on a small $BTC short here 🤏. Know the odds: ETFs keep gulping coins, dominance still leaning north, and a clean close > 112 K torches the trade. Tight stop, need ETF flows to flip red & alts to pop fast. Risk on, eyes wide open #Bitcoin #Bitcoin2025
English
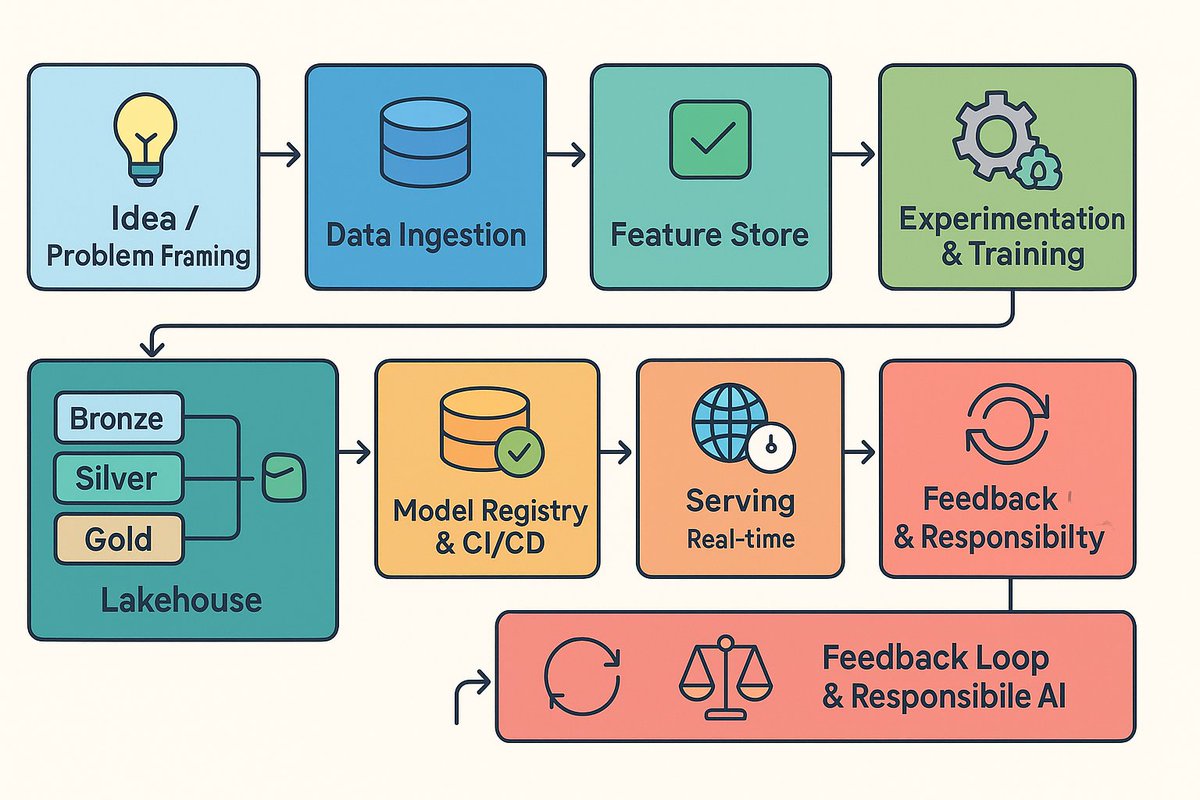
It’s more than just training models.
In my latest post, I walk you through how to take an ML idea all the way to production — step by step, with real examples on Azure and AWS.
If you’re ready to truly own the pipeline, this one’s for you.
@manolosake/blueprints-for-production-grade-machine-learning-an-end-to-end-guide-from-idea-to-impact-e0a42e0c8a9a" target="_blank" rel="nofollow noopener">medium.com/@manolosake/bl…
English
Ponc retweetledi

o3 and o4-mini have absolutely NAILED the vibe check ✅
This is best result so far!
English
Ponc retweetledi

From the GPT-4.5 System Card:
"GPT-4.5 is not a frontier model, but it is OpenAI's largest LLM, improving on GPT-4's computational efficiency by more than 10x."
It offers:
— increased world knowledge
— improved writing ability
— refined personality
2-7% lift on 4o at SWE-Bench

English
Ponc retweetledi

I got early access to ChatGPT Operator.
It's OpenAI's new AI agent that autonomously takes action across the web on your behalf.
The 9 most impressive use cases I’ve tried (videos sped up):
1. Ordering dinner ingredients based on a picture and a recipe
English

Ponc retweetledi

o3 is really special and everyone will need to update their intuition about what AI can/cannot do.
while these are still early days, this system shows a genuine increase in intelligence, canaried by ARC-AGI
semiprivate v1 scores:
* GPT-2 (2019): 0%
* GPT-3 (2020): 0%
* GPT-4 (2023): 2%
* GPT-4o (2024): 5%
* o1-preview (2024): 21%
* o1 high (2024): 32%
* o1 Pro (2024): ~50%
* o3 tuned low (2024): 76%
* o3 tuned high (2024): 87%
given i put in the original $1M @arcprize, i'd like to re-affirm my previous commitment. we will keep running the grand prize competition until an efficient 85% solution is open sourced.
but our ambitions are greater! ARC Prize found its mission this year -- to be an enduring north star towards AGI.
the ARC benchmark design principle is to be easy for humans, hard for AI and so long as there remain things in that category, there is more work to do for AGI.
there are >100 tasks from the v1 family unsolved by o3 even on the high compute config which is very curious.
successors to o3 will need to reckon with efficiency. i expect this to become a major focus for the field. for context, o3 high used 172x more compute than o3 low which itself used 100-1000x more compute than the grand prize competition target.
we also started work on v2 in earnest this summer (v2 is in the same grid domain as v1) and will launch it alongside ARC Prize 2025. early testing is promising even against o3 high compute. but the goal for v2 is not to make an adversarial benchmark, rather be interesting and high signal towards AGI.
we also want AGI benchmarks that can endure many years. i do not expect v2 will. and so we've also starting turning attention to v3 which will be very different. im excited to work with OpenAI and other labs on designing v3.
given it's almost the end of the year, im in the mood for reflection.
as anyone who has spent time with the ARC dataset can tell you, there is something special about it. and even moreso about a system than can fully beat it. we are seeing glimpses of that system with the o-series.
i mean it when i say these are early days. i believe o3 is the alexnet moment for program synthesis. we now have concrete evidence that deep-learning guided program search works.
we are staring up another mountain that, from my vantage point, looks equally tall and important as deep learning for AGI.
many things have surprised me this year, including o3. but the biggest surprise has been the increasing response to ARC Prize.
i've been surveying AI researchers about ARC for years. before ARC Prize launched in June, only one in ten had heard of it.
now it's objectively the spear tip benchmark, being used by spear tip labs, to demonstrate progress on the spear tip of AGI -- the most important technology in human history.
@fchollet deserves recognition for designing such an incredible benchmark.
i'm continually grateful for the opportunity to steward attention towards AGI with ARC Prize and we'll be back in 2025!
ARC Prize@arcprize
New verified ARC-AGI-Pub SoTA! @OpenAI o3 has scored a breakthrough 75.7% on the ARC-AGI Semi-Private Evaluation. And a high-compute o3 configuration (not eligible for ARC-AGI-Pub) scored 87.5% on the Semi-Private Eval. 1/4
English
Ponc retweetledi

JUST IN: Solana $SOL hits new all-time high of $264.
English