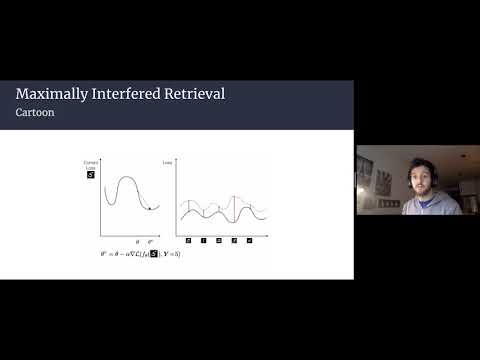
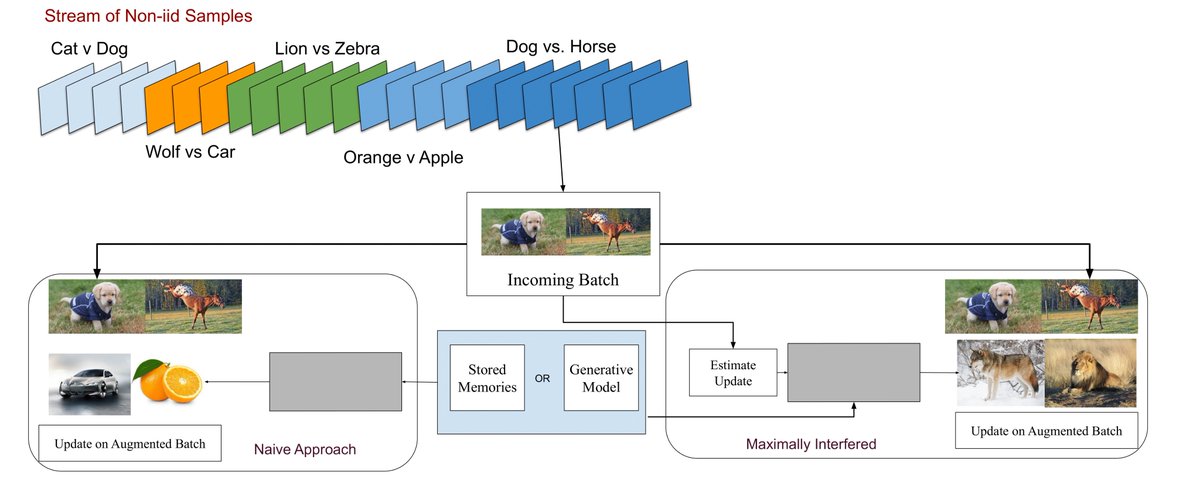
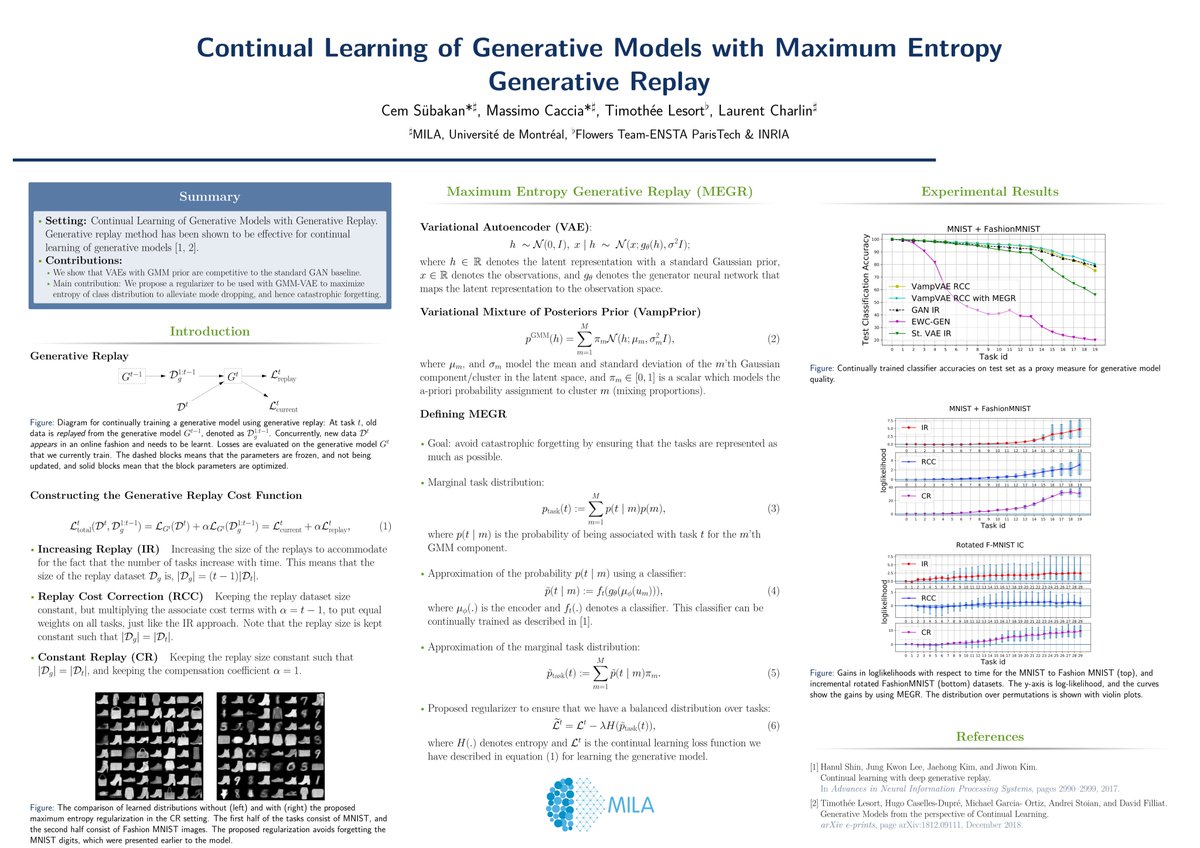
This fall, during a Dagstuhl seminar on continual learning, we discussed with various researchers from the field the roadmap for continual learning.
We converged to one view: modular memory is the key to continual learning agents, as outlined in here arxiv.org/pdf/2603.01761
English