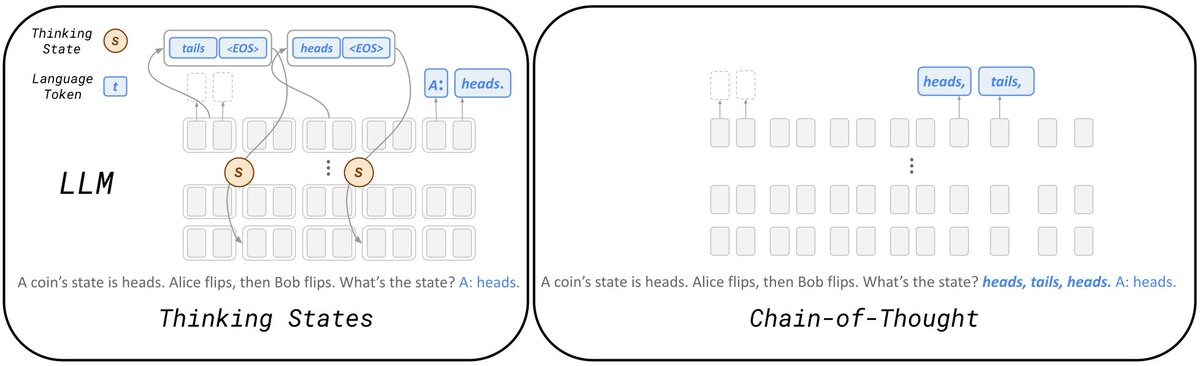
@JentseHuang Thanks @JentseHuang ! Sounds very interesting, we mostly used Thinkig States to represent reasoning in our work but treating them as an internal memory indeed sounds very natural. I’ll have a look on your experiments
English
Ido Amos
13 posts
@AmosaurusRex
MSc student at Tel-Aviv University working on ML/DL



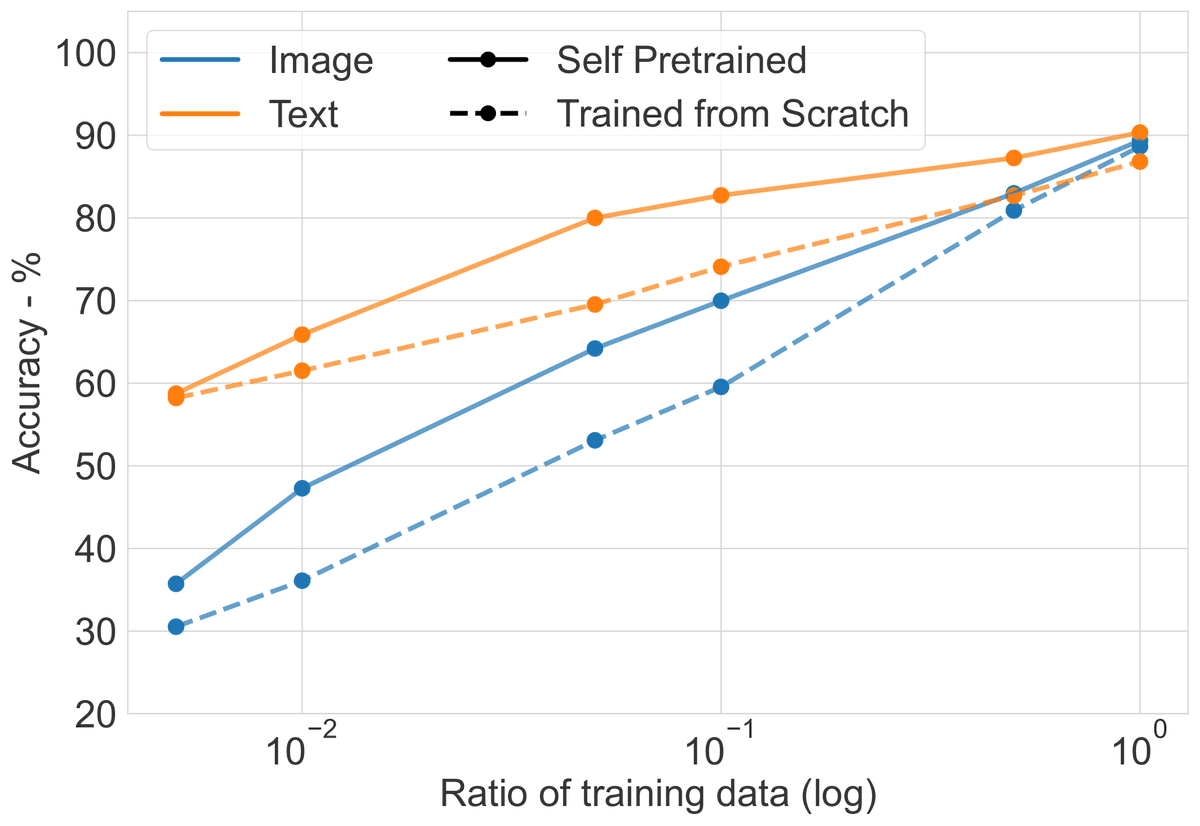
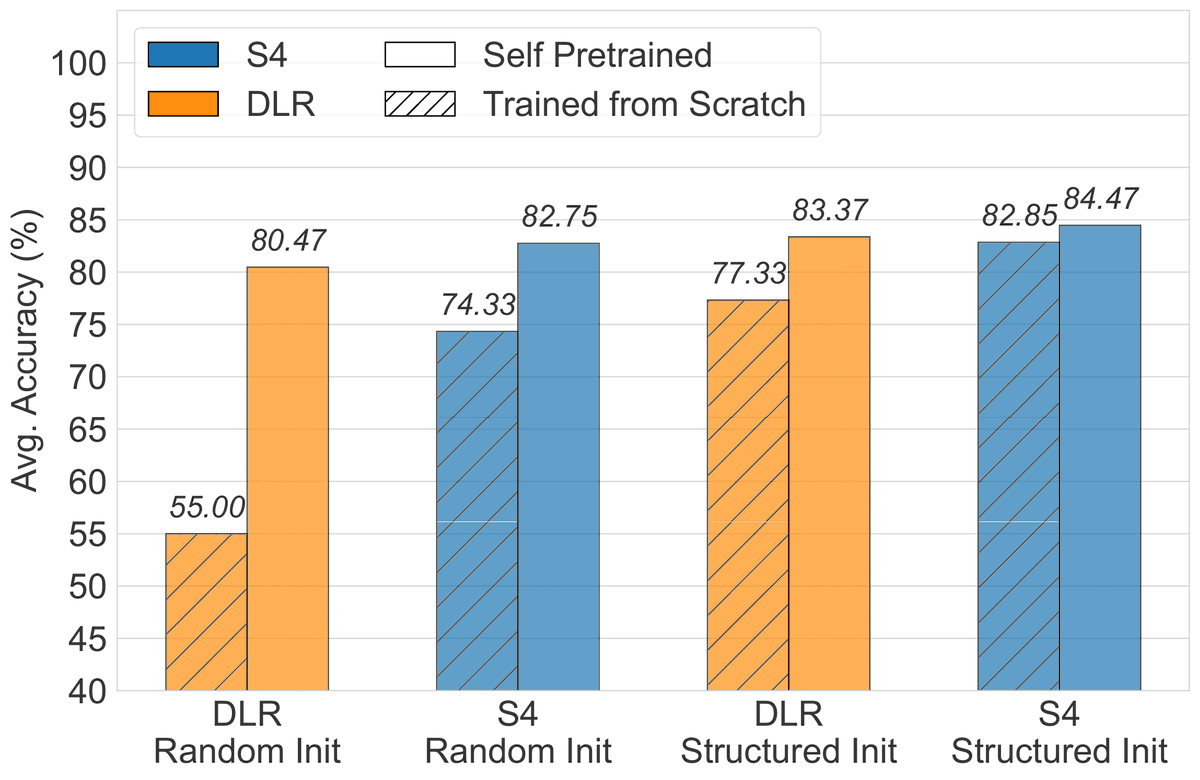
Excited to share my work with @JonathanBerant @ankgup2! We show pretraining on task data alone suffices to bridge the gap between state space models and transformers on Long Range Arena, leading to a significantly better estimate of model capabilities. arxiv.org/abs/2310.02980 🧵