
Andrés Anaya Isaza - PhD
46 posts

Andrés Anaya Isaza - PhD
@AndresAI_
Scientist in artificial intelligence and bioengineering, passionate about knowledge and technology creation, as well as a musical artist at heart.
Medellín - Colombia Katılım Mart 2017
156 Takip Edilen59 Takipçiler


Ser un gran diseñador con conocimientos básicos de código y Linux, junto con Claude Code/Codex, tiene que ser la combinación de skills más poderosa del momento.
Español
@elonmusk @Yuchenj_UW Singularity ≠ bigger models. It implies qualia + human-level emergent cognition. Today we don’t even know how to measure that let alone implement it...
English


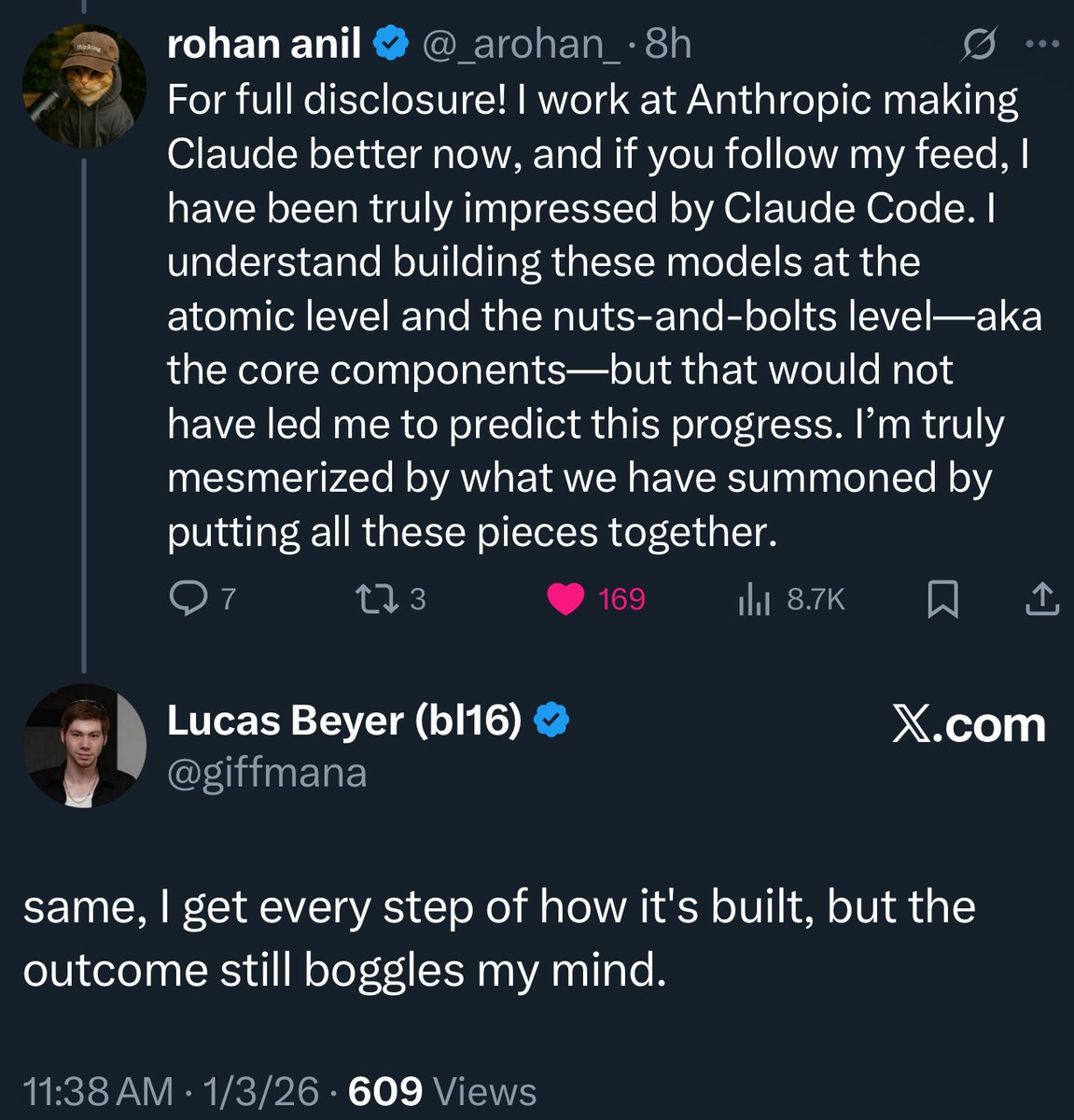
Roban (Gemini co-author, now at Anthropic) and Lucas (ex-DeepMind/OpenAI, now at Meta) understand models like Claude Opus down to the atomic level.
And yet, Claude Code still blew their minds.
This happens all the time in AI. Even the people who build these systems are shocked by the intelligence that emerges, just like Demis being stunned by AlphaGo’s “Move 37.”
That mystery is what pulled me into AI research during my PhD. AI is mysterious and unpredictable, yet deeply attractive. The models just want to learn.
Buckle up. Fast takeoff ahead!
Yuchen Jin@Yuchenj_UW
ex-Google and Meta distinguished engineer, Gemini co-author @_arohan_: “if I had agentic coding and particularly opus, I would have saved myself first 6 years of my work compressed into few months.” This matches my experience. AI collapses the learning curve, and turns junior engineers into senior engineers dramatically fast. New-hire onboarding on large codebases shrinks from months to days. What used to take hours of Googling and Stack Overflow is now a single prompt. AI is also a good mentor and pair programmer. Agency is all you need now.
English
@lexfridman Review the mathematics of "infinite memory o Nested Learning", Especially because of the border problems with the creation of drugs and vaccines.
English

Doing a long, super-technical podcast on the state-of-the-art in AI. Let me know if you have question, topic suggestions. Everything from details of LLM training pipeline & architectures, to coding, robotics, scaling, compute, business, geopolitics, etc.
Besides topics & questions... add papers, blogs, posts, rants, perspectives that you'd like to see covered.
English

TikTok + n8n + Claude = AI Content Machine
(this system monitors Instagram, YouTube, TikTok, LinkedIn, Twitter, Facebook for viral content 24/7)
→ No manual scrolling.
→ No $12K agency research fees.
→ No guessing what content works.
Just automated intelligence extraction across 6 platforms.
Perfect for brands tired of content guesswork.
Here's how it works:
→ Platform monitoring engine (tracks LinkedIn, Twitter, IG, TikTok, YouTube, Reddit)
→ Comment analysis system (extracts pain points + desires automatically)
→ Psychological pattern mapping (identifies emotional triggers driving shares)
→ Content strategy generator (creates platform-specific playbooks instantly)
→ Trend detection loop (updates as market psychology shifts)
Built with competitive intelligence architecture.
Runs 24/7 without manual work.
10-minute setup. Enterprise-grade insights.
Want the complete system blueprint?
Like + comment "MACHINE" + repost, and I'll DM it to you.
(must be following)
English

I used ChatGPT to solve an open problem in convex optimization.
*Part I*
(1/N)
English
@sama They had delayed team... As they are also a little delayed in expanding the context window...
English

today we are introducing codex.
it is a software engineering agent that runs in the cloud and does tasks for you, like writing a new feature of fixing a bug.
you can run many tasks in parallel.
English
@adrianaia_ Juaaaaaaaajuajuajuajuajuajuajuajuajuajuajua
Español


Deseo el mejor de los éxitos y bendiciones a @MauricioLizcano. Sin temor a equivocarme, debo decir que se consolidó como el Ministro de la IA. Nosotros los científicos y empresarios de IA, estaremos siempre agradecidos por tú gestión. #MinTic 2025
Español
Andrés Anaya Isaza - PhD retweetledi

OpenAI’s biggest rival is shaking things up.
Anthropic invited 200+ elite hackers to their SF headquarters to see what’s possible with Claude
Here’s what we saw at the @AnthropicAI x @MenloVentures Builder Day Hackathon (🧵):


English
¡Premio Nobel para Geoffrey Hinton! Increíble!!! Esto es un claro mensaje que reafirma la importancia de la ciencia en Inteligencia Artificial 🙌🏼 Es un merecido reconocimiento que valida elementos teóricos en física y matemáticas, al más alto honor en la historia. @geoffreyhinton

Español
Andrés Anaya Isaza - PhD retweetledi

OpenAI Strawberry (o1) is out! We are finally seeing the paradigm of inference-time scaling popularized and deployed in production. As Sutton said in the Bitter Lesson, there're only 2 techniques that scale indefinitely with compute: learning & search. It's time to shift focus to the latter.
1. You don't need a huge model to perform reasoning. Lots of parameters are dedicated to memorizing facts, in order to perform well in benchmarks like trivia QA. It is possible to factor out reasoning from knowledge, i.e. a small "reasoning core" that knows how to call tools like browser and code verifier. Pre-training compute may be decreased.
2. A huge amount of compute is shifted to serving inference instead of pre/post-training. LLMs are text-based simulators. By rolling out many possible strategies and scenarios in the simulator, the model will eventually converge to good solutions. The process is a well-studied problem like AlphaGo's monte carlo tree search (MCTS).
3. OpenAI must have figured out the inference scaling law a long time ago, which academia is just recently discovering. Two papers came out on Arxiv a week apart last month:
- Large Language Monkeys: Scaling Inference Compute with Repeated Sampling. Brown et al. finds that DeepSeek-Coder increases from 15.9% with one sample to 56% with 250 samples on SWE-Bench, beating Sonnet-3.5.
- Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters. Snell et al. finds that PaLM 2-S beats a 14x larger model on MATH with test-time search.
4. Productionizing o1 is much harder than nailing the academic benchmarks. For reasoning problems in the wild, how to decide when to stop searching? What's the reward function? Success criterion? When to call tools like code interpreter in the loop? How to factor in the compute cost of those CPU processes? Their research post didn't share much.
5. Strawberry easily becomes a data flywheel. If the answer is correct, the entire search trace becomes a mini dataset of training examples, which contain both positive and negative rewards.
This in turn improves the reasoning core for future versions of GPT, similar to how AlphaGo’s value network — used to evaluate quality of each board position — improves as MCTS generates more and more refined training data.

English
Español

@AndresAI_ @erickwendel_ Qué gusto conocerte, Andrés !!!!!! 💚✨ La pasamos increíble. Espectacular tu charla !!! 🔥
Español
Momentos gratos antes de la Platzi Conf 2024 💚 con los Goat del FrontEnd e Ingeniería de Interfaces @teffcode y @erickwendel_ hoy en el salón de la IA 😎💪🏻

Español
@alarcon7a Que desgracia que sólo se mire lo malo, ya estoy viendo varios que están destrozando su reputación 😖
Español

@AndresAI_ Se abrió la discusión sobre los benchmarks, sobre si es cierto o solo se vende humo, sobre cómo medir realmente el impacto de un modelo etc etc etc y pues, atacan fuertemente al tipo que publicó el modelo
Español
Que tóxico se está volviendo todo al rededor de reflection 70b 👀
Español
Cordialmente invitados. Platzi Conf 2024. Donde hablaremos de "Nuestro paradójico destino con la IA" Se analizará el RoadMap de la Inteligencia Artificial General - AGI, la evolución de nuestra especie, un análisis de los AVANCES, singularidad, la civilización humana y mucho más!

Español