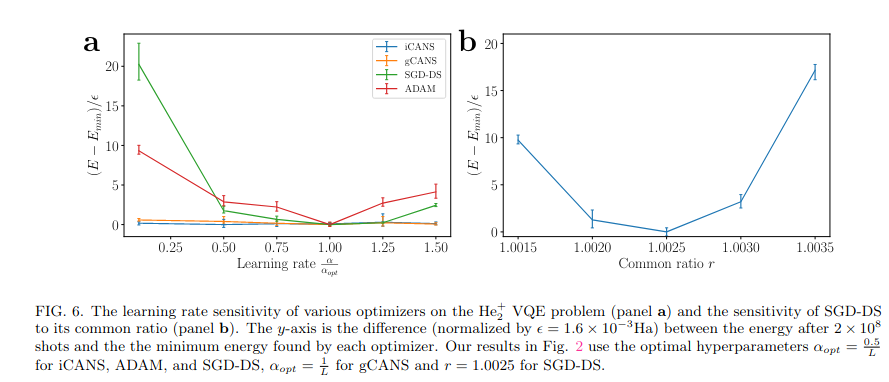
These improvements make gCANS a very efficient optimization strategy overall as in addition to being shot frugal and converging quickly, it is largely insensitive to hyper-parameter choice meaning that there is no need for expensive hyper-parameter tuning.
Hi, check out our new paper on optimization for variational quantum algorithms with Andi Gu, Angus Lowe, Pavel Dub, and @ColesQuantum! We introduce a shot frugal optimizer that also converges quickly in terms of the number of iterations!
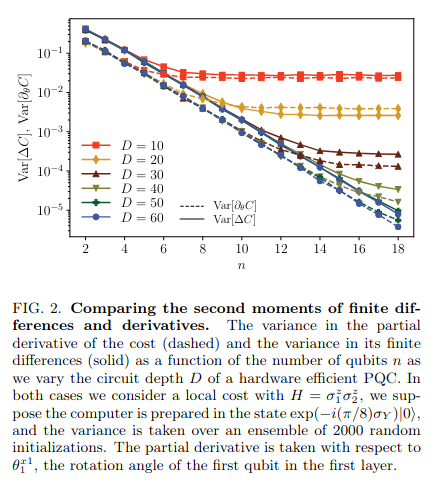
This result means that when numerically testing for a barren plateau you don't need to consider the full gradients. Both are mean zero and the variances of finite differences scale the same. This can significantly speed up the investigation when there are many parameters!
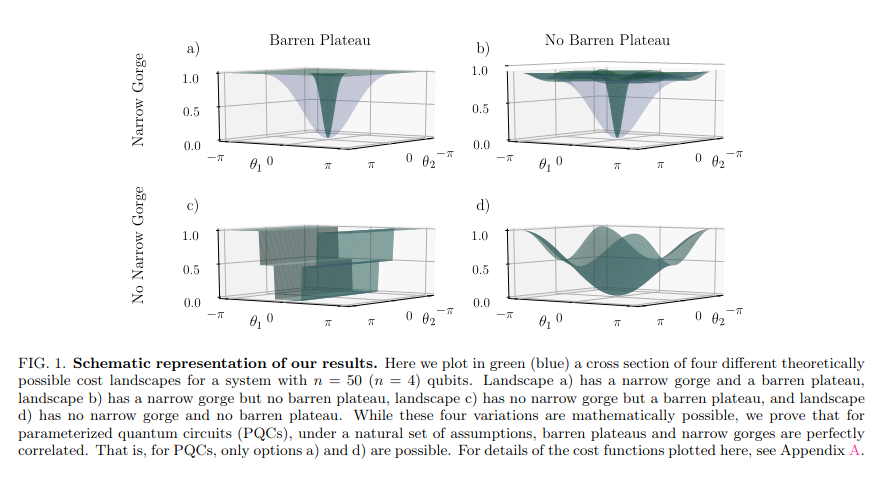
Here is the basic idea. For an optimization landscape, one might imagine that you could have vanishing gradients without a narrow gorge or vice versa. However, we prove that only panels a and d are valid quantum optimization landscapes.
Happy world quantum day! Here is a new paper from my coauthors @qZoeHolmes@MvsCerezo@ColesQuantum and me. We show that for parameterized quantum circuit landscapes barren plateaus and narrow gorges always come hand in hand. Check it out!
Of course, if you do have enough qubits for more copies, you can always apply our method and recycle them too!😉Check our paper out on the arXiv: arxiv.org/pdf/2102.06056…
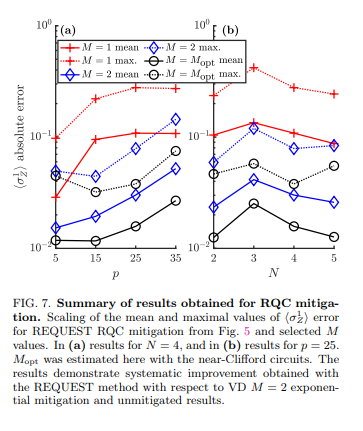
In addition, for a realistic trapped-ion noise model, our approach is consistently better than vanilla virtual distillation if you are qubit limited and can only afford two copies of the state. On NISQ devices it is likely you won't have enough well-connected qubits for more!
Recently an exciting new approach to near-term quantum error suppression has arisen: virtual distillation. Unfortunately, this method is very qubit hungry. Piotr Czarnik, @LCincio, @ColesQuantum, and I show a way to make it more resource-efficient in the paper we just posted:
@QuantumM14 Indeed, noise can make a BP far worse. Moreover, it can even cause one! See this paper by some of my collaborators on that point: arxiv.org/abs/2007.14384
There has been some debate about how serious barren plateaus are for variational algorithms, with some people suggesting that just using a gradient free optimizer would solve the problem. Here is a new paper with @MvsCerezo Piotr Czarnik @LCincio@ColesQuantum proving otherwise.