For years, the typical customer buying journey looked roughly like this:
Search Google -> read your blog/docs -> click around -> decide -> talk to sales.
But today AI is changing where “learning” happens.
Now it often looks like:
Ask Copilot/ChatGPT -> copy/paste into a tool -> decide -> talk to sales.
That is not a small UX change. That is a distribution change.
If your growth model relies on humans visiting pages (docs, help centres, knowledge bases, even your product pages), you’re exposed to a very specific kind of failure.
Your customers still use your product.
They just stop visiting the places where you persuade them.
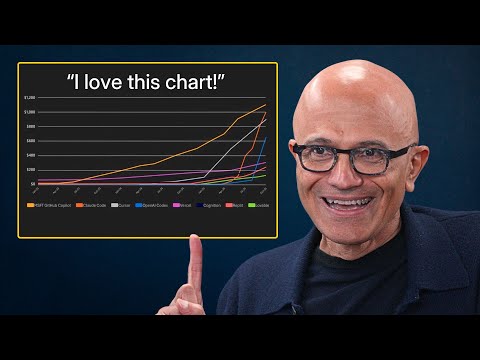
This is why the Tailwind story (doc traffic down while AI-assisted usage goes up) is interesting, even if you ignore the drama. The mechanism is the point: when AI becomes the interface, the “browsing moments” disappear.
And it’s not niche. GitHub’s Octoverse has been tracking how quickly AI is becoming a default part of development, and GitHub Copilot reportedly crossed 20 million all-time users in 2025.
Even if you’re not selling to developers, the principle carries.
AI is starting to sit between you and your customer’s attention.
So the question for an SME is simple: what do you do when your best persuasion surfaces (pages) get bypassed?
Here’s the practical playbook.
1) Move proof closer to the decision.
Stop hiding credibility in blog posts that people may never read.
Put proof in places that survive AI intermediation:
- onboarding (where the user is actually trying to succeed)
- proposals and SOWs (where risk gets priced in)
- contracts (where objections turn into clauses)
- support replies (where trust is built one ticket at a time)
- inside the workflow itself (tooltips, templates, guardrails, “why this matters”)
If a buyer only ever sees your product through an AI summary, you still want them to bump into specifics: outcomes, constraints, reassurance, and evidence.
2) Make your business legible to machines and humans.
This is where most “documentation” efforts miss the point. Don’t just write pages. Write artefacts.
Artefacts are the things that get quoted, scraped, forwarded, and pasted into Slack.
Examples:
- a public status page (signals maturity)
- a simple API spec (even if it’s not public, make it real)
- a changelog with trade-offs (not just “improvements”, tell the truth)
- an integration map (what connects to what, and what doesn’t)
- a one-page “what we do and don’t do” (cuts sales cycles fast)
These travel better than “thought leadership”, and AI can actually use them.
3) Treat your website as a receipt, not the interface.
Your site still matters. The job just changes.
It becomes the place someone goes to verify what the AI told them.
So clarity beats cleverness.
Specifics beat slogans.
If your homepage says “We deliver innovative solutions” (congrats, you sound like everyone). If it says “We build client portals that reduce admin time by 30-50% by automating onboarding, approvals, and reporting” you’re giving the verifier something concrete.
A quick test: ask a customer where they learned how to use the last tool they adopted.
If the honest answer is “I asked an AI assistant”, congratulations. Your marketing just got a new competitor.
Sources:
businessinsider.com/tailwind-engin…
github.blog/news-insights/…
techcrunch.com/2025/07/30/git…
theverge.com/podcast/844073…

English