Sabitlenmiş Tweet

I'll still be around Twitter. But my time here will be deliberately more utilitarian. When it comes to scrolling and tweeting for the vibes catch me here.
English
🍔 Andy Wilson 🍔
11.7K posts

@AndyWilson22
In-house Copywriter & Marketing Strategist Writes other things too. DR trained. Published poet. Person not a brand. Be nice on the internet. MTGO: AndySCWilson





OpenAI just published a paper proving that ChatGPT will always hallucinate. Not sometimes. Not "until the next version." Always. They proved it mathematically. And three other top AI labs confirmed it independently. Here's what the research actually shows: Even with perfect training data and unlimited compute, LLMs will still fabricate answers with complete confidence. This isn't a bug in the code. It's fundamental to how these systems are built. The numbers are wild: → OpenAI's o1 model: 16% hallucination rate → Their o3 model: 33% → Their newest o4-mini: 48% Nearly half of what their latest model tells you could be invented. And it's getting worse as models get "smarter." Here's why this can't be fixed: Language models predict the next word based on probability. When they hit uncertainty, they don't pause. They don't flag it. They guess with total confidence. Because that's literally what they were trained to do. The researchers analyzed the 10 major AI benchmarks used to test these models. 9 out of 10 give the exact same score for saying "I don't know" as for getting it completely wrong: zero points. The entire testing system punishes honesty and rewards confident guessing. So the AI learned the optimal strategy: always answer. Never show doubt. Sound certain even when making it up. OpenAI's proposed solution? Train models to say "I don't know" when uncertain. The problem? Their own math shows this would leave roughly 30% of questions unanswered. Imagine getting "I'm not confident enough to respond" three times out of ten. Users would abandon the product overnight. The fix exists. But it kills usability. This isn't just OpenAI's problem. DeepMind and Tsinghua University reached identical conclusions working separately. Three elite AI labs. Independent research. Same result: this is permanent. Every time you get an answer from any LLM, you're not getting facts. You're getting the most statistically probable next words from a system that's been rewarded for never admitting when it's guessing. Is this real information, or just a confident hallucination? You can't know. And neither can the AI.



I received an email through my website’s contact form from a teenager that said: “I found your wallet.” Attached was a photo of my Prada wallet with my driver’s license, debit card, and credit cards inside. She wrote, “Please call me so I can get it back to you.” The crazy part? I didn’t even know it was lost. She had found it in the parking lot of a strip mall where I get my nails done. When I called her, she said she’d been worried for hours because she knew that when I realized it was gone I would be “frantic.” I then spoke to her mom, who sent me their address. I drove about 30 minutes to their house to get it. When I got there I was so overwhelmed by her kindness that I cried. Her mom was standing on the front porch beaming and said, “I’m doing my best to teach my kids that doing the right thing matters.” I handed her a $100 bill. She smiled huge and thanked me. I told her the only person who deserved thanks was her. I mentioned the wallet was designer because a lot of 16-year-olds would have kept it. It was expensive. She didn’t. A lot of people would have used the credit cards inside. She didn’t. Instead, she spent hours worried about how I would feel when I realized it was gone. Friends, please know that good and honest humans absolutely exist. And when you’re faced with a decision, ask yourself, “What would I hope a stranger would do if the situation were reversed?”


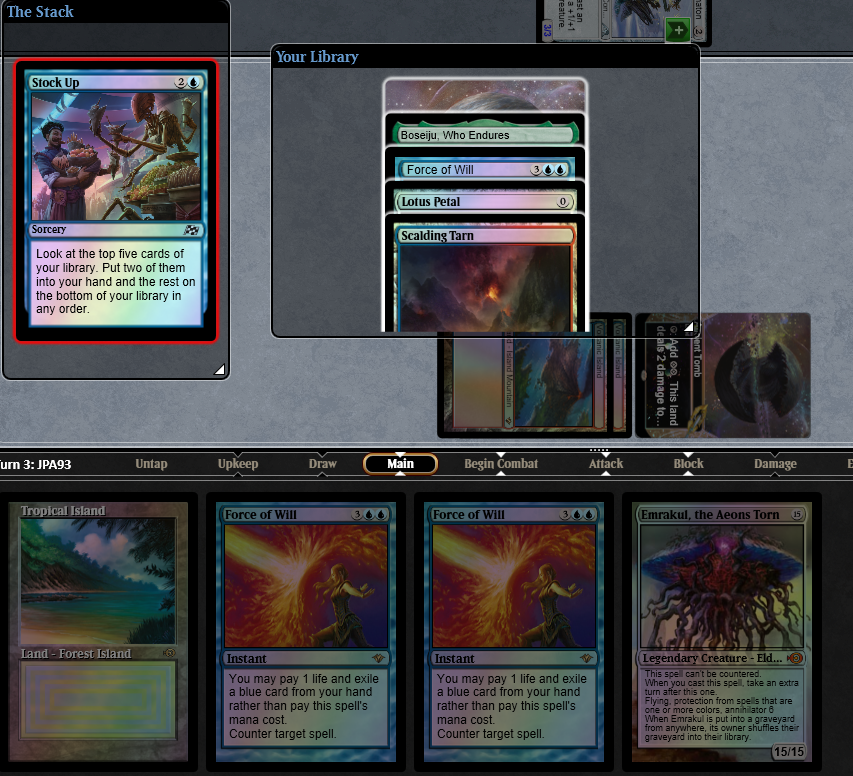
Legacy Qualifier 5-2 with UR Sneak & Show. Win-and-in loss: mull to 4 in g1, mull to 5 in g3 (pic). For more funny screenshots, check out my Patreon subscriber recap articles. UB Tempo LL BG Hogaak WW UR Tempo LWW UR Sneak & Show WW BG Hogaak WW UR Sneak & Show WW RW Energy LWL