

App-In Club retweetledi

We discovered how to cut the failure rate of any AI agent on Tau²-Bench, the #1 benchmark for customer service AI.
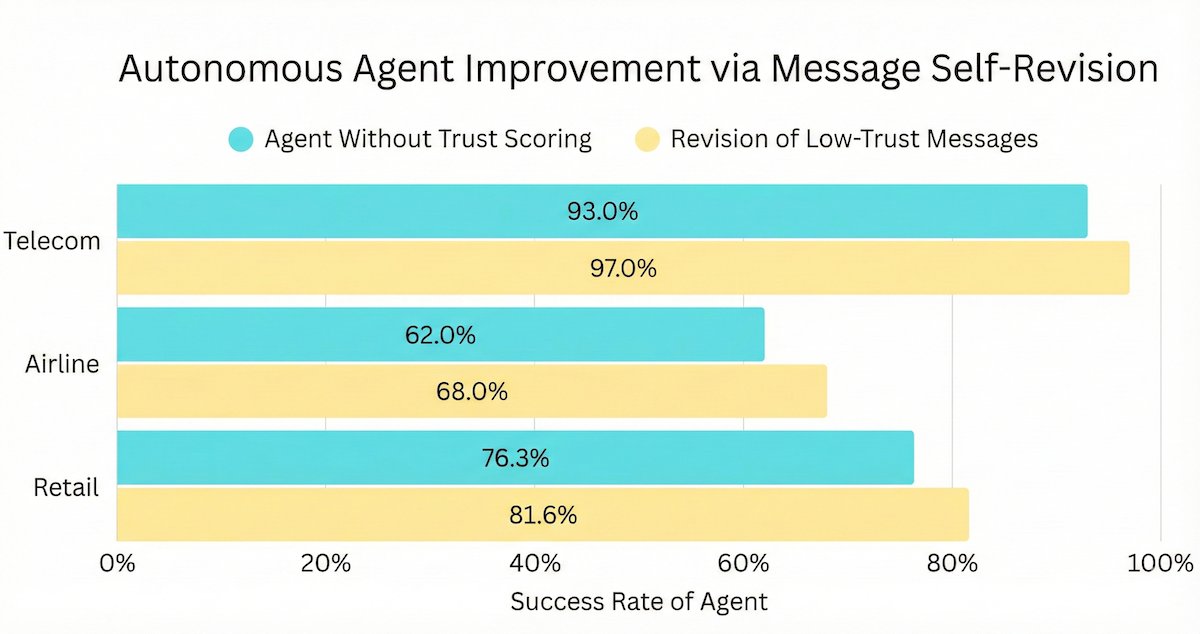
Agents often fail in multi-turn, tool-use tasks due to a single bad LLM output (reasoning slip, hallucinated fact, misunderstanding, wrong tool call, etc). We introduce an automated LLM trust scoring + message revision pipeline that mitigates this brittleness and keeps agents on the rails.
Benchmarks show that our approach remains effective across all Tau²-Bench domains (Telecom, Retail, Airline) and different LLMs -- cutting agent failure rates up to 50%.
English










































