
Arnav Chavan
15 posts
Arnav Chavan
@ArnavChavan6
Senior Applied Scientist @ Amazon Lab126 | 1x Founder | Efficient & Sustainable AI | Prev. - Google Deepmind, Microsoft Research
Sunnyvale, CA Katılım Şubat 2022
298 Takip Edilen99 Takipçiler

Excited to begin my summer research internship at @nvidia today. I’ll be working in the Applied Deep Learning Research team in the Santa Clara HQ office. Let me know if you are around and would like to meet!

English
🚀 Organizing the Efficient Qwen Competition @icmlconf !
Goal: Minimize LLM inference latency for a single GPU without breaking model quality.
Prizes: $3K / $2K / $1K + present at ICML 2026, Seoul
Getting Started - adaptfm.gitlab.io/call-for-compe…
Leaderboard - d1krc5fcnf73gi.cloudfront.net
English
Arnav Chavan retweetledi

📣 We're extending the AdaptFM @ ICML'26 paper submission deadline to May 8! This will align better with the ICML acceptance announcements and NeurIPS deadlines.
👉 Submit your work at: openreview.net/group?id=ICML.…
🌐 CfP: adaptfm.gitlab.io

English
🚀 We're launching the Efficient Qwen Competition @ AdaptFM #ICML2026! How fast can you make Qwen3.5-4B run on a single A10G without breaking it? $6,000 in prizes (credits @AmazonLab126)! Submissions open May 4. 📷 adaptfm.gitlab.io/call-for-compe… #LLM #EfficientML #ModelOptimization
English
Arnav Chavan retweetledi
📢 Announcing the AdaptFM Workshop @icmlconf
As foundation models grow in scale and ubiquity, the ability to adapt inference dynamically to the task and available resources becomes critical.
Submission deadline: May 1, 2026 (AoE)
📍Seoul, South Korea
🌐adaptfm.gitlab.io

English
Arnav Chavan retweetledi

🔍 From tedious to streamlined! Nyun Zero's 'Nyun Kompress' module transforms model optimization with automated compression techniques that maintain performance. 🚀📊 #AIModel #TechNews #Efficiency
Learn more at nyunai.com
English
Arnav Chavan retweetledi
Say goodbye to the manual grind! 🛠️ Nyun Zero automates AI model training and optimization, slashing development time and enhancing accuracy.🎯 #ModelOptimization #DeepLearning #AI #GenerativeAI #DataScience #Innovation #NyunZero
Join the revolution at nyunai.com
English
Arnav Chavan retweetledi
🚀 Speeding up AI with Nyun Zero! Traditional model development takes months; we do it in days. No more long waits from concept to deployment. 🕒✨
#ModelOptimization #DeepLearning #AI #GenerativeAI #DataScience #Innovation #NyunZero
🔗 Discover how at nyunai.com

English
Arnav Chavan retweetledi
Our Team at @Nyun_AI_ recently compiled an experimental survey with a thorough codebase - Faster and Lighter LLMs: A Survey on Current Challenges and Way Forward.
We provide a comprehensive overview of multiple LLM compression methodologies along with system-level approaches.
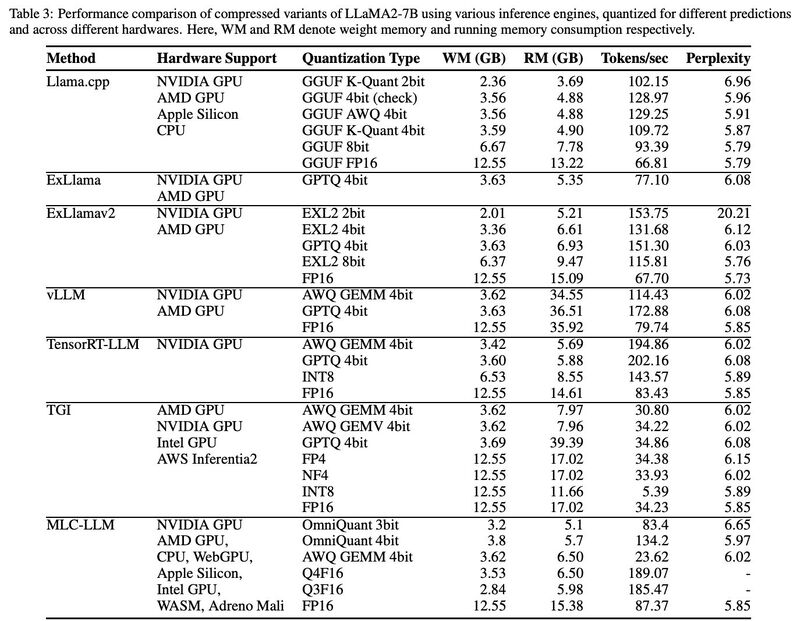
English
Arnav Chavan retweetledi
Say hello to Nyun Zero 💡- where AI meets efficiency! Reduce inference costs, speed up training, and secure your data like never before. 🛡️ Join the revolution in AI productivity. #EfficientAI #DeepLearning 🚀 Sign up here ➡️ [forms.office.com/r/NxYwkmGypG]
English
Arnav Chavan retweetledi

Rethinking Compression: Reduced Order Modelling of Latent Features in Large Language Models
paper page: huggingface.co/papers/2312.07…
Due to the substantial scale of Large Language Models (LLMs), the direct application of conventional compression methodologies proves impractical. The computational demands associated with even minimal gradient updates present challenges, particularly on consumer-grade hardware. This paper introduces an innovative approach for the parametric and practical compression of LLMs based on reduced order modelling, which entails low-rank decomposition within the feature space and re-parameterization in the weight space. Notably, this compression technique operates in a layer-wise manner, obviating the need for a GPU device and enabling the compression of billion-scale models within stringent constraints of both memory and time. Our method represents a significant advancement in model compression by leveraging matrix decomposition, demonstrating superior efficacy compared to the prevailing state-of-the-art structured pruning method.

English
English


@_akhaliq Thanks for your tweet.
Code - github.com/Arnav0400/ViT-…
Website - sites.google.com/view/generaliz…
English
Arnav Chavan retweetledi
One-for-All: Generalized LoRA for Parameter-Efficient Fine-tuning
paper page: huggingface.co/papers/2306.07…
present Generalized LoRA (GLoRA), an advanced approach for universal parameter-efficient fine-tuning tasks. Enhancing Low-Rank Adaptation (LoRA), GLoRA employs a generalized prompt module to optimize pre-trained model weights and adjust intermediate activations, providing more flexibility and capability across diverse tasks and datasets. Moreover, GLoRA facilitates efficient parameter adaptation by employing a scalable, modular, layer-wise structure search that learns individual adapter of each layer. Originating from a unified mathematical formulation, GLoRA exhibits strong transfer learning, few-shot learning and domain generalization abilities, as it adjusts to new tasks through additional dimensions on weights and activations. Comprehensive experiments demonstrate that GLoRA outperforms all previous methods in natural, specialized, and structured benchmarks, achieving superior accuracy with fewer parameters and computations on various datasets. Furthermore, our structural re-parameterization design ensures that GLoRA incurs no extra inference cost, rendering it a practical solution for resource-limited applications.

English
