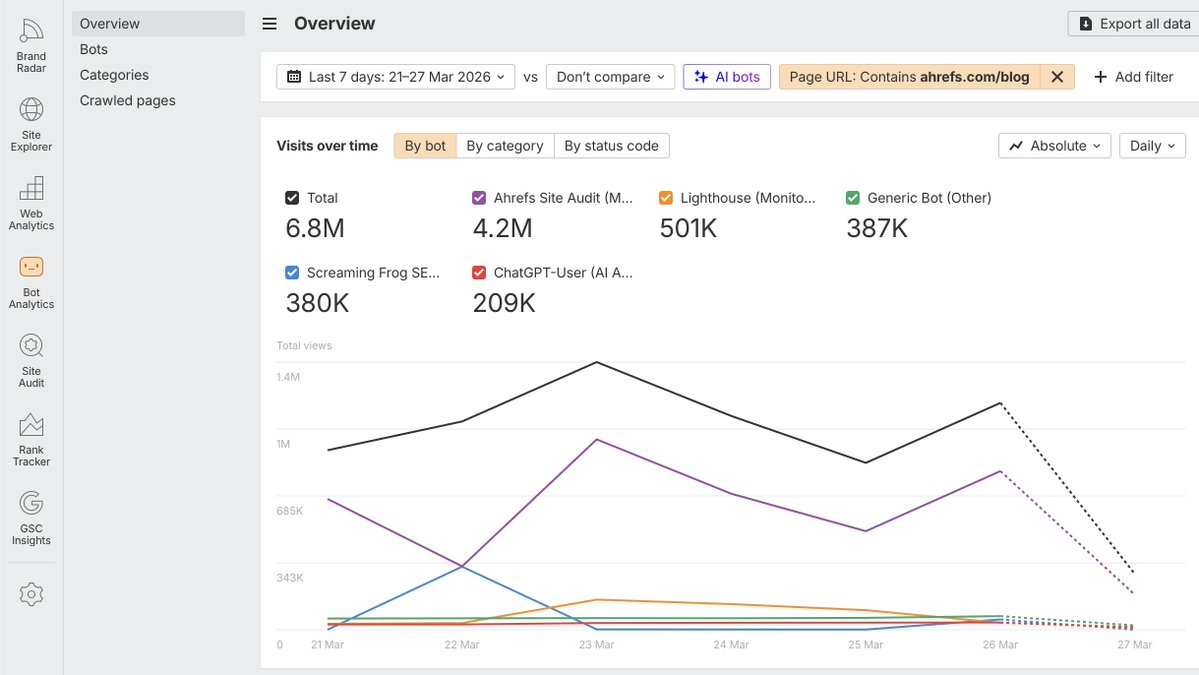
Sabitlenmiş Tweet

Start here — AutoNextFlow shares AI workflows, SEO systems, automation lessons, and agent reliability breakdowns for modern brands. Less hype. More repeatable systems.
English
Auto Next Flow
660 posts

@AutoNextFlow
AI workflows, SEO systems, automations, and agent reliability lessons for modern brands.

Woh. Search console has been inaccurately reporting impressions since May 2025. A fix is coming over the next few weeks. #zippy=%2Cperformance-reports-search-results-discover-google-news%2Cproduct-wide-notes" target="_blank" rel="nofollow noopener">support.google.com/webmasters/ans…






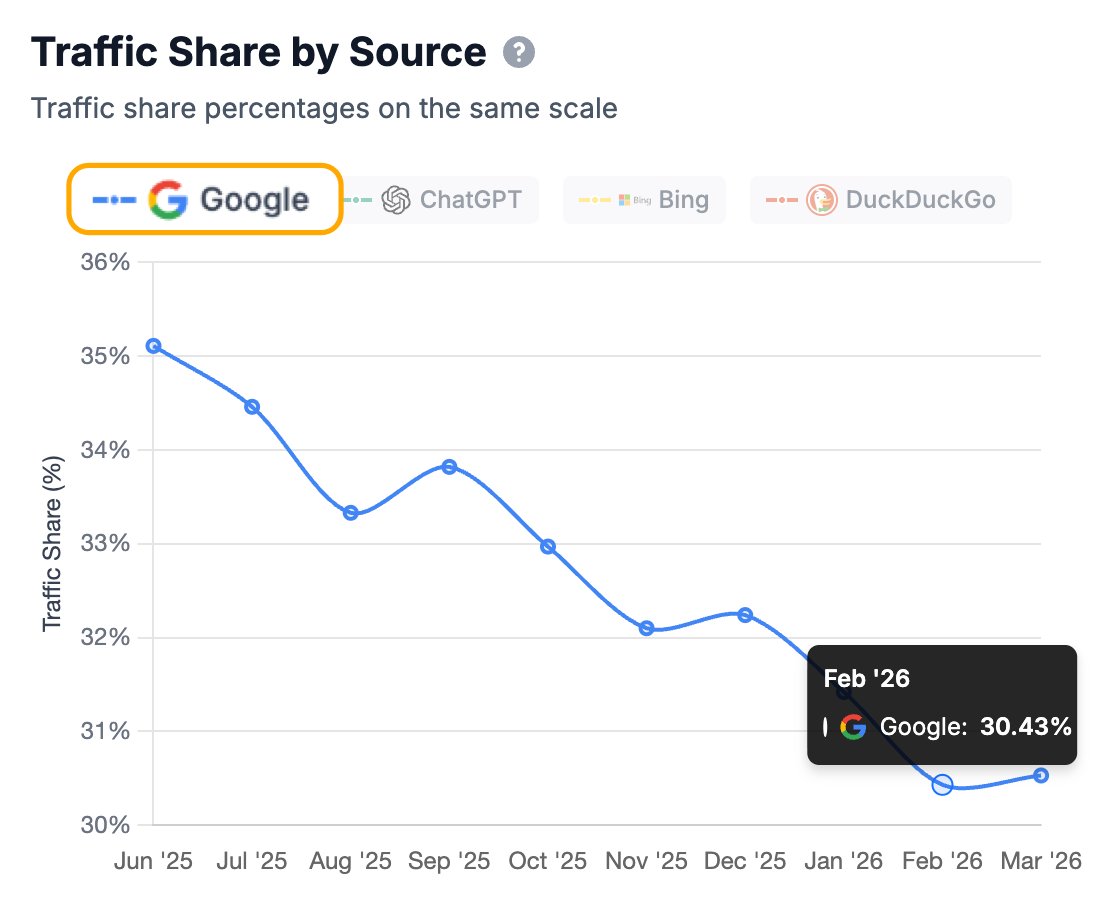
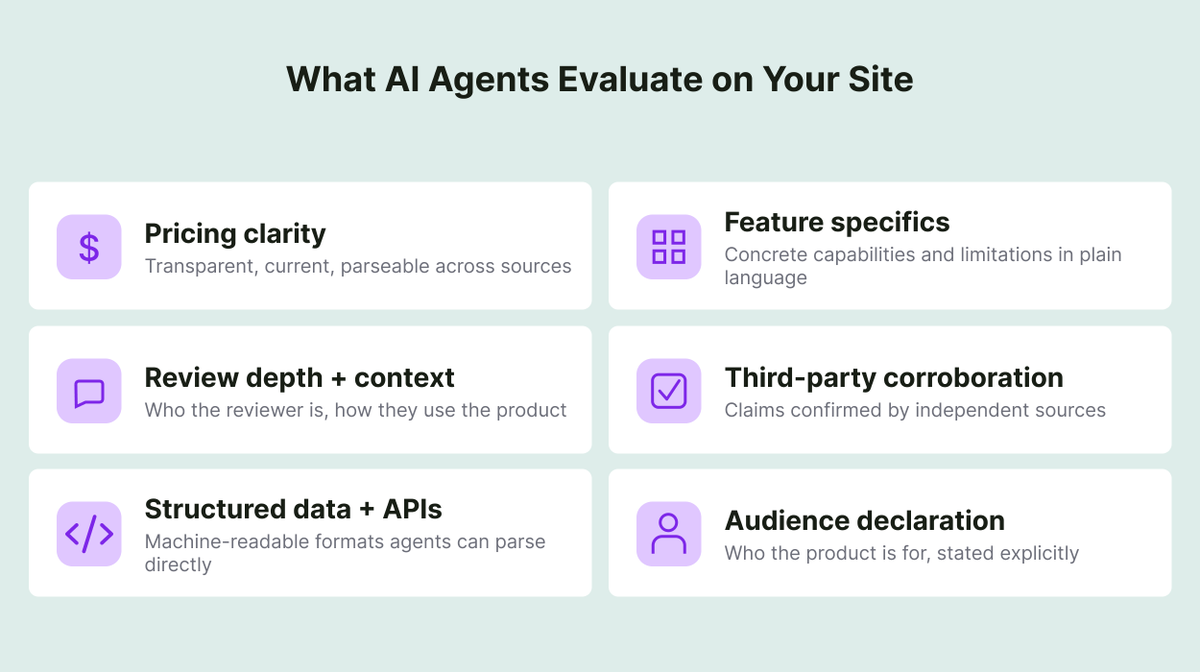

LLM evals are slow to adapt. MMLU/GSM8K continued to be reported long after they were obsolete. I think the next thing to go away will be comparing models on evals by a single number. Intelligence/$ is a much better metric. I loved this plot from o1-mini's launch for example: