
Sabitlenmiş Tweet

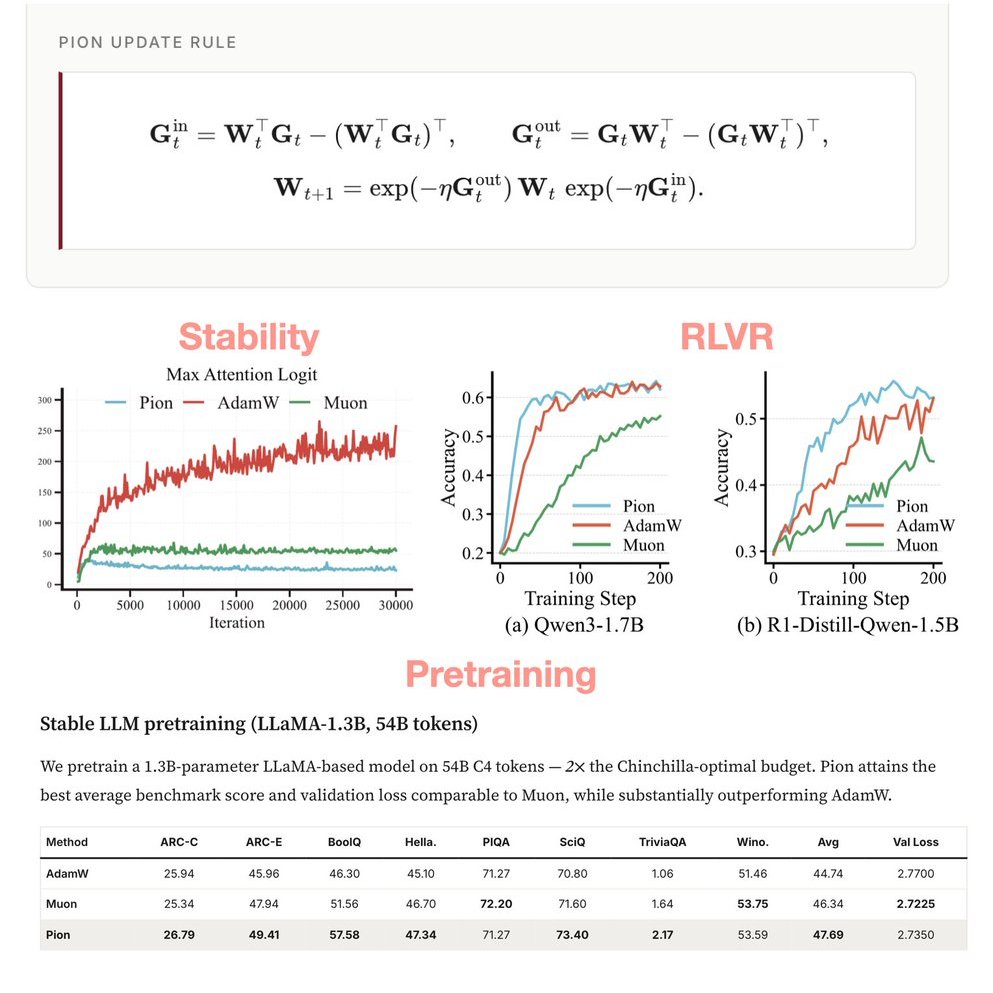
🚀 We are very excited to introduce Pion — a spectrum-preserving optimizer for LLM training. Pion shows strong training stability in practice.
This is the project that we have been working on since POET. The central idea is to turn POET/POET-X (spherelab.ai/poet; spherelab.ai/poetx) into an easy-to-use optimizer.
Instead of additive updates like Adam & Muon, Pion takes a different route by updating each weight matrix via coupled left & right orthogonal transformations, keeping its weight spectrum stable throughout training. This different update mechanism is directly inspired by the empirical effectiveness of Orthogonal Finetuning (oft.wyliu.com; boft.wyliu.com) and POET/POET-X, with roots tracing back to minimum-energy training methods such as MHE (arxiv.org/abs/1805.09298) and OPT (opt-training.github.io).
Pion's key features:
✨ Competitive on LLM pretraining, SFT & RLVR
✨ μP-compatible by construction
✨ Stabily trains ultra-deep LLMs and even normalization-free LLMs, where AdamW & Muon diverge
🌐 Project: spherelab.ai/pion
📜 Paper: arxiv.org/abs/2605.12492
English


