
希德
882 posts

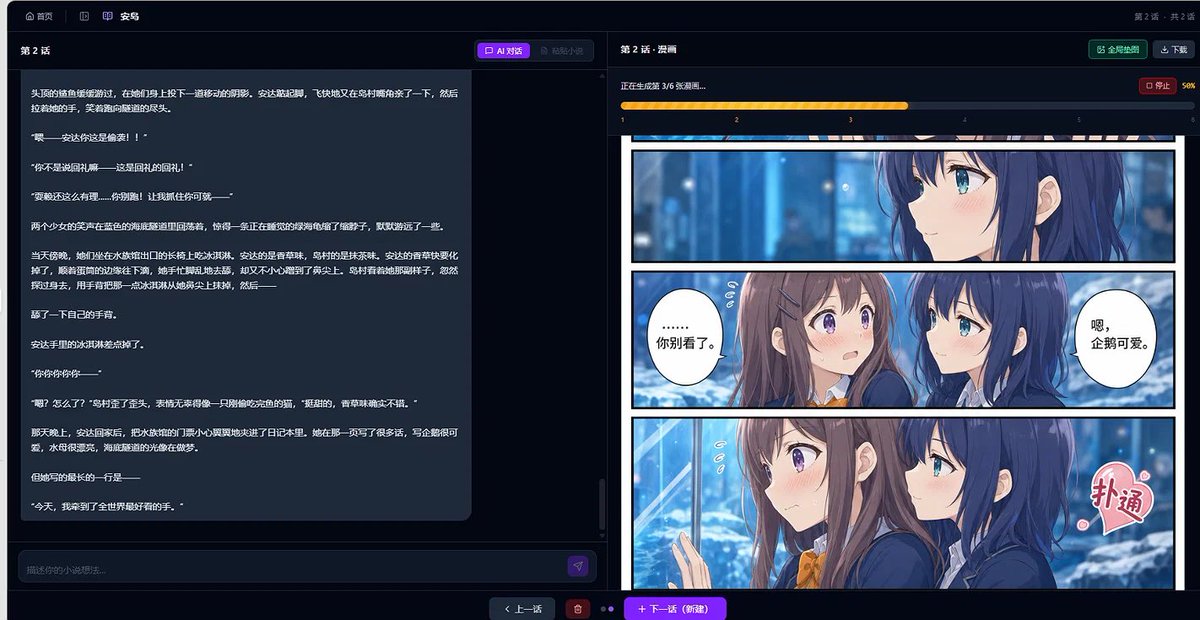

你是一个刚毕业的大学生,拥有着机缘与运气, 同时靠着自己的努力沉淀了大半年
在推特积累了快50,000粉丝
和合伙人做出来了第一个项目
叫做CC中转
接下来你要面对的竞争对手是《孙宇晨》
H.E. Justin Sun 👨🚀 🌞@justinsuntron
史上最强 AI 中转站 B.AI 白来了。 一个 API Key = Claude + GPT + Gemini + 国产大模型全系列 ✅ 区块链地址登录,纯匿名支付(兼容邮箱Visa/Master/Apple Pay) ✅ 官方 API 直连,零篡改,价格卷到全网最低 ✅ BAIClaw 上线"孙哥大脑"——用孙哥思维交易加密 可以冲了!🚀
中文










有空看看
无颜@WY_mask
这个太牛逼了!大家都在用这三个工具在闲鱼赚钱!!! 1⃣闲鱼智能监控工具:ai-goofish-monitor 能实时/定时监控闲鱼商品,自动筛选产品,通过 AI 分析性价比和真实度,帮你快速发现低价好货,捡漏秒拍必备 🔗github.com/Usagi-org/ai-g… 2⃣闲鱼多账号智能管理系统:xianyu-auto-reply-fix 支持多账号管理、AI 自动回复、自动发货确认、多渠道消息通知,还提供完整 Web 管理后台。适合系统化/矩阵化运营闲鱼店铺,提升出单效率 🔗github.com/GuDong2003/xia… 3⃣闲鱼 AI 智能客服机器人:XianyuAutoAgent 7×24 小时自动化回复/出单,支持多专家协同决策、智能议价和上下文感知对话。卖家自动处理买家询价、砍价和出单,大幅减少手动聊天时间 🔗github.com/shaxiu/XianyuA…
中文
中文



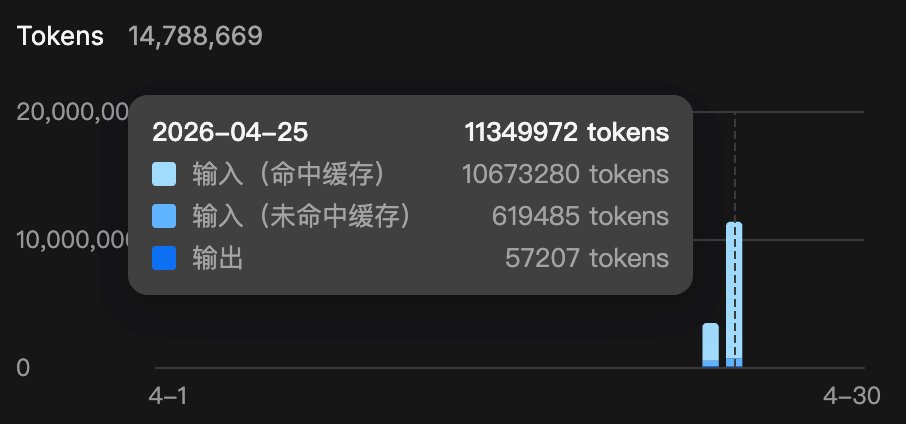

@Jaden_riku 《伟大为何不能被计划》里有个很关键的概念叫 stepping stone:
很多东西本身不是终点,但它会把你带到下一个更有价值的位置
中文






希德 retweetledi


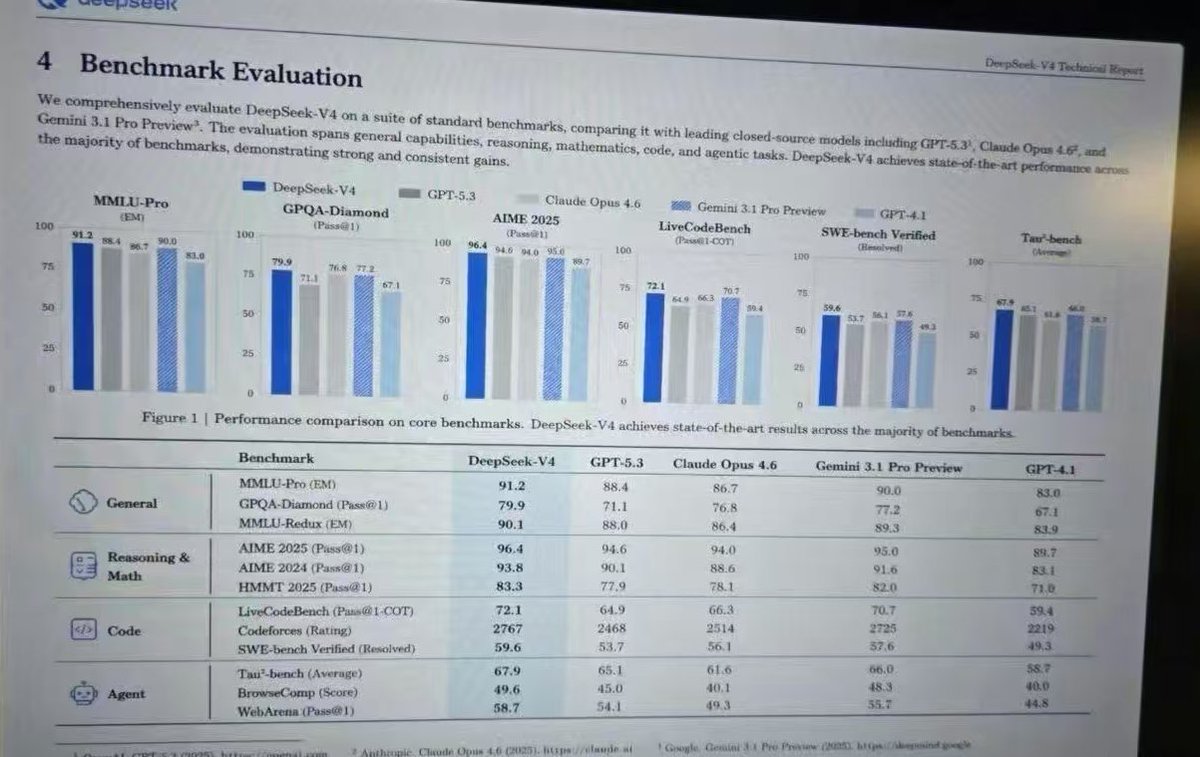


疑似 DeepSeek V4 技术报告的 benchmark泄露!
图中 的“DeepSeek-V4 技术报告”基准测试(Benchmark)数据,为我们揭示了当前顶尖 AI 大模型的最新竞争格局。从这份涵盖通用能力、推理数学、代码以及智能体(Agent)四大维度的成绩单来看,DeepSeek-V4 展现出了极强的统治力,而大模型的第一梯队也正在经历重新洗牌。
🏆 竞争格局:当前大模型梯队划分
从图表数据中,我们可以清晰地看到五款参评模型的实力分层:
👑 领跑者:DeepSeek-V4在所有 12 项严苛测试中均斩获最高分(State-of-the-Art),实现了跨维度的全面压制。
🥈 最强追赶者:Gemini 3.1 Pro Preview在多项核心指标上紧咬榜首,并在绝大多数测试成绩中超越了 GPT-5.3,是目前这组对比中最具竞争力的对手。
🥉 第三梯队:GPT-5.3 与 Claude Opus 4.6两者互有胜负,依然保持着极高的水准,但在最顶尖的竞争中已稍显疲态。
📏 基准线参照:GPT-4.1作为较早期模型的代表,其数据在这组对比中全面垫底,但也直观地印证了新一代模型技术跨越的幅度之大。
🔍 四大核心能力深度拆解
🧠 1. 综合常识与学科能力 (General)
核心数据:在极具挑战性的 MMLU-Pro 测试中,DeepSeek-V4 (91.2) 和 Gemini 3.1 Pro (90.0) 是唯二突破 90 分大关的模型。
行业洞察:跨学科的专家级知识问答对头部模型已不再是难题。GPT-5.3 (88.4) 和 Claude (86.7) 在这方面稍显落后,知识密度的竞争正在向 90+ 的极限逼近。
🧮 2. 数学与复杂推理 (Reasoning & Math)
核心数据:顶尖数学竞赛基准 AIME 2025 呈现极度“内卷”的态势(DeepSeek-V4 96.4,Gemini 95.0,GPT-5.3 94.6)。
行业洞察:数学是 AI 进步最神速的领域。90+ 的得分意味着这些模型在解决人类高难度奥数题时已经具备了压倒性的优势,各家在这个领域的差距往往只在几道题之间。
💻 3. 编程与工程能力 (Code)
核心数据:在 Codeforces(算法竞赛平台)上,DeepSeek-V4 飙升至 2767 分,拉开显著差距;但在评估修复真实软件工程 Bug 的 SWE-bench Verified 中,所有模型均未突破 60%(最高为 DeepSeek-V4 的 59.6%)。
行业洞察:“写算法题容易,改人类代码难”。模型在纯逻辑生成上已经达到竞赛级选手水平,但在理解和修改复杂的现实商业代码库时,依然存在明显的短板。
🤖 4. 智能体自主行动 (Agent)
核心数据:在模拟网页浏览和执行任务的 WebArena 测试中,全场最高分(DeepSeek-V4)仅为 58.7,GPT-4.1 甚至低至 44.8。
行业洞察:这是全表绝对得分最低的板块。它反映了当前的行业痛点:大模型“做题”和“写文章”能力极强,但如果让它像人类一样自主操作浏览器、跨应用处理多步骤现实任务,成功率依然堪忧。
💡 核心总结这份基准测试不仅是 DeepSeek-V4 强悍实力的“肌肉秀”,也侧面印证了 Gemini 3.1 Pro Preview 在当前技术路线上的极强竞争力。更重要的是,它为行业指明了下一步的攻坚方向——当模型的知识储备和做题能力逼近人类极限时,突破“智能体自主执行 (Agentic tasks)”的现实应用瓶颈,将是决定下一代 AI 霸权的关键。
仅针对图中数据解读,真实情况还有待验证!

中文

