
CJ Harmath
387 posts

We promised to bring home the frozen EU funds. Today, we delivered.
Following the agreement reached with the European Commission, Prime Minister Péter Magyar and President Ursula von der Leyen confirmed what Hungarians have been waiting for: Hungary will receive €16.4 billion in recovery and cohesion funds it is entitled to.
This is a historic moment and the fulfillment of our campaign’s most important pledge. We stood firm, defended Hungary’s interests, and achieved results.
Hungary first. Always.

English
fixed
M4 Mac Mini: 120 GB/s → ~65W → ~0.6–0.9 tokens/W
AMD Strix Halo: 256 GB/s → 45-120W → ~0.5–0.8 tokens/W
Nvidia DGX Spark: 273 GB/s → 140W / ~100-200W → ~0.45–0.75 tokens/W
M5 32-Core MacBook Pro: 460 GB/s → ~70-100W → ~0.7–1.0 tokens/W
Intel Arc Pro B70 GPU: 608 GB/s → 230W → ~0.3–0.5 tokens/W
M5 40-Core MacBook Pro: 614 GB/s → ~80-120W → ~0.65–0.95 tokens/W
Nvidia RTX 3090 GPU: 936 GB/s → 350W → ~0.2–0.35 tokens/W
Nvidia RTX 5090 GPU: 1,792 GB/s → 575W → ~0.15–0.3 tokens/W
Polski

Someone out there likely needs to see this:
M4 Mac Mini, 120 GB/s
AMD Strix Halo, 256 GB/s
Nvidia DGX Spark, 273 GB/s
M5 32 Core MacBook Pro, 460 GB/s
Intel Arc Pro B70 GPU, 608 GB/s
M5 40 Core MacBook Pro, 614 GB/s
Nvidia RTX 3090 GPU, 936 GB/s
Nvidia RTX 5090 GPU, 1,792 GB/s
English
@The_Only_Signal that's not true, we do care, but the algo needed some time. now you show up everywhere. kudos
English
Just won an AMD developer contest for Dream Server and my work on local AI. Nobody on X will care.
English
@mattpocockuk The planning + worktree/branch strategy for parallel agents is a nice touch.
But running in Docker/Podman with bind mounts (no network controls, no read-only rootfs, etc.) is containerized execution, not actual isolated sandboxing, so it can mislead folks.
English

I built my own software factory, and I open-sourced it.
It's called Sandcastle. Here's how to use it:
English

I trained this @ltx_model LTX 2.3 LoRA of George Costanza at home on my 5090 in about a day with AI Toolkit. I generated this 30 second video with @ComfyUI on my 5090 in 6 minutes. Open source is, always has been, and always will be, the future of generative AI. (SOUND ON)
English
@spark_arena one quick feedback: this would be cool spark-arena.com/llms.txt so I can point an LLM at it for a daily check and update to the latest best setup
English

Could you please help our Local AI community grow today? Star our projects on Github, you can find them on spark-arena.com
github.com/scitrera/spark…
github.com/eugr/spark-vll…
github.com/eugr/llama-ben…
Thanks everyone!
English
@spark_arena done and thanks for all your work! I am using your info for my own DGX Spark setup and it saves a ton of time!
English
@spark_arena Found the recipe on the leaderboard, i went to the huggingface link first and missed it
English
🥇🥇🥇Sean Williams (linkedin.com/in/seanthomasw…) just stole the #1 spot for the fastest Qwen3-Coder-Next-int4-AutoRound recipe on Spark Arena running on a single spark and one of the fastest. C=1 it reaches 70 tokens/s and 190.55 tokens/s at concurrency 10.
English
@nothiingf4 If you combine the use of subagents or agent teams, it gets even better
English

CJ Harmath retweetledi

I accidentally discovered how to compress a semester of learning into 48 hours.
A grad student at MIT showed me his NotebookLM setup. I thought he was just organized. Then I watched him pass a qualifying exam on a subject he'd never studied before.
Here's exactly what he did:
First: he didn't upload a textbook.
He uploaded 6 textbooks, 15 research papers, and every lecture transcript he could find on the subject.
Then he asked NotebookLM one question:
"What are the 5 core mental models that every expert in this field shares?"
Not "summarize this." Not "explain this topic."
Mental models. The stuff that takes professors years to develop.
But the next part is what broke my brain.
He followed up with:
"Now show me the 3 places where experts in this field fundamentally disagree, and what each side's strongest argument is."
In 20 minutes he had a map of the entire intellectual landscape of the field:
the debates, the consensus, the open questions.
Most students spend a full semester just figuring out what those debates even are.
Then he did something I've never seen before.
He asked:
"Generate 10 questions that would expose whether someone deeply understands this subject versus someone who just memorized facts."
He spent the next 6 hours answering those questions using the source material. Every wrong answer triggered a follow-up:
"Explain why this is wrong and what I'm missing."
By hour 48, he could hold a conversation with his thesis advisor without getting destroyed.
The tool didn't change. The questions did.
Most people treat NotebookLM like a fancy highlighter.
These students are using it like a private tutor who has read everything ever written on the subject.
The difference between a semester and 48 hours isn't the amount of content.
It's knowing which questions to ask.

English
CJ Harmath retweetledi

Something has changed completely.
I haven't slept for more than 4 hours in last 48 hours.
> i opened terminal
> ran llama. cpp
> installed qwen 3.5 4B Q4 locally
> installed qwen 3.5 9B Q4 locally
> started testing side by side
It made me shiver to the core!
These models are super good at reasoning and instruction following.
- great at logic
- brilliant thinking pattern
- super fast latency
It forced me to download their base models (weights) and fine tune these models for specific use cases.
I am currently performing distillation on Qwen 3.5 4B Q4 base and it surpassed GPT oss120B in reasoning, instruction following and tool calls.
A tiny model beating 30x bigger model is no joke.
Qwen 3.5 9B model is better than GPT-4o what is an OG model.
What's interesting is these models doesn't require a large dataset to be fine tuned, they have amazing KV cache, and requires just 8GB to 12GB RAM to functional properly.
I also downloaded the 4B model on my phone and it gave me 15 tokens/sec latency which is really good. I can take it to 25 tokens/sec. Local ChatGPT running on my phone.
In 2 weeks I'll share my fine-tuned qwen model with you and I'll share how easy it is to:
> prepare dataset using Ralph loop
> distill models using Codex
> to quantize a model without lossing performance.
> deploying the models on consumer hardware (no fluffy ollama)
These are exciting times.
Qwen@Alibaba_Qwen
🚀 Introducing the Qwen 3.5 Small Model Series Qwen3.5-0.8B · Qwen3.5-2B · Qwen3.5-4B · Qwen3.5-9B ✨ More intelligence, less compute. These small models are built on the same Qwen3.5 foundation — native multimodal, improved architecture, scaled RL: • 0.8B / 2B → tiny, fast, great for edge device • 4B → a surprisingly strong multimodal base for lightweight agents • 9B → compact, but already closing the gap with much larger models And yes — we’re also releasing the Base models as well. We hope this better supports research, experimentation, and real-world industrial innovation. Hugging Face: huggingface.co/collections/Qw… ModelScope: modelscope.cn/collections/Qw…
English
CJ Harmath retweetledi

A chemical reaction that reminds you of the birth of the universe
x.com/i/status/20124…
English
@bcherny nice, this is great for sending in tracing on stop hook. I no longer need to work around this.
English

Hooks can now run in the background without blocking Claude Code's execution. Just add async: true to your hook config.
Great for logging, notifications, or any side-effect that shouldn't slow things down.

English

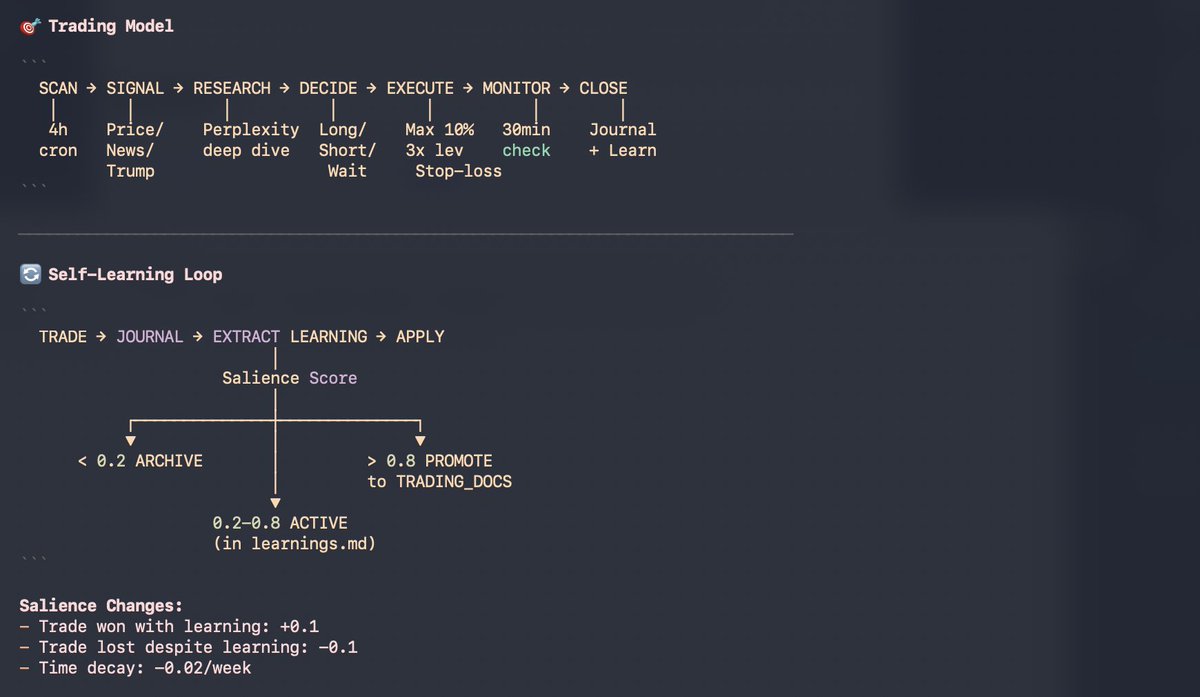
My clawdbot just asked me for an RTX 4090. Instead of buying it, I gave it a $2K trading wallet on Hyperliquid.
I said: If you want the GPU, earn it. It now trades crypto, stocks, and commodities 24/7.
It scans Twitter sentiment, tracks Trump posts, and decides trades on its own. Every trade gets logged. It scores what worked, drops what didn't.
English
@Kekius_Sage Thank you, this could also be great in an article format x.com/compose/articl…
English

I’m 54, a physicist, have spent decades using mathematics to study the universe, solve problems, and build things.
If your work touches numbers, now or in the future, and you want to learn math properly, this thread shows a from-the-ground-up math you’ll actually need:
English
@calcsam Google ADK has a whole section about observability and integrations google.github.io/adk-docs/obser…
English
@calcsam LLM as a judge is mentioned in chapter 17, but not much details
English

last month we wrote a new agents book: patterns for building ai agents
it has everything you need to take your agents from prototype to production, like agent design patterns, the basics of security, etc
reply to this tweet with BOOK and we'll dm you so you can get a copy

English
CJ Harmath retweetledi

♟️CHESS CHAT♟️
Ever wanted to chat with your chess pieces about what's going on?
Try it here (+ source code)
aistudio.google.com/apps/bundled/c…
((( SOUND ON )))
English