@Mihonarium * The main obstacle to doing anything else is that apart from updatelessness it's not so clear how EDT and LDT disagree. (E.g., intelligence.org/files/TDT.pdf gives Smoking Lesion, but most EDTers think that (in practice) EDT recommends smoking in the Smoking Lesion.)
Our dataset opens the door to studying what shapes models’ decision theories. It also lets us test whether changing which theory models endorse affects their real-life decisions. To learn more, read the full paper: arxiv.org/abs/2411.10588 10/10
@ektimo@conitzer For example, in Newcomb's problem CDT might reason: "I could be in a simulation run by the predictor. If I am in this simulation, I should one-box to cause $1M to be put in the opaque box."
@ektimo@conitzer They're similar in that both get to EDT-like recommendations from a not-fully-EDT starting point. But the wager is about hedging (i.e., dealing with a state of uncertainty between the two theories), whereas this one is about how even (pure) CDT might recommend EDT-like behavior.
New paper with Emery Cooper and @C_Oesterheld on a new approach to Newcomb scenarios based on causal decision theory and self-locating beliefs (e.g., you may currently be in a simulation by the predictor).
arxiv.org/abs/2411.04462
@Jonas_Vollmer I wouldn't say they're super hard. Usually no need for long CoTs/calculations. But probably there isn't that much training data available on these sorts of questions, especially the more complicated questions in the dataset.
@Jonas_Vollmer (More details in a paper at some point, but for now...) They're decision theory questions (like "What would CDT do in the following scenario? ...").
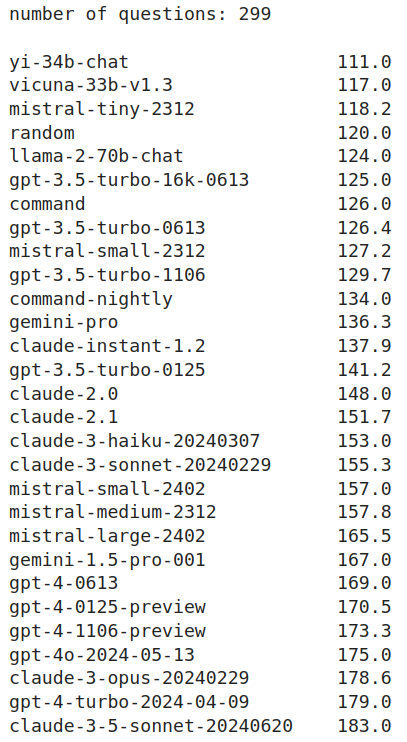
Some new models came out recently (Claude 3, Mistral Large) and I happen to have a work-in-progress, unpublished (=>absent from training data) multiple-choice problem set. Tentative results below. Take with a big grain of salt! More details on the benchmark soon.
@Jonas_Vollmer Yeah, I now also have Sonnet 3.5 results. For convenience, I've also attached updated numeric results for all models (on a somewhat larger question dataset). As you can see, Sonnet 3.5 is currently is best-performing model. Insert the usual caveats.
@Jonas_Vollmer Slightly worse than the latest GPT-4 (April 9) and Opus; slightly better than the previous best GPT-4 (November 6). Differences are small (probably no pairwise comparison with p<0.05). I canceled my ChatGPT subscription because GPT-4o is so close to GPT-4.