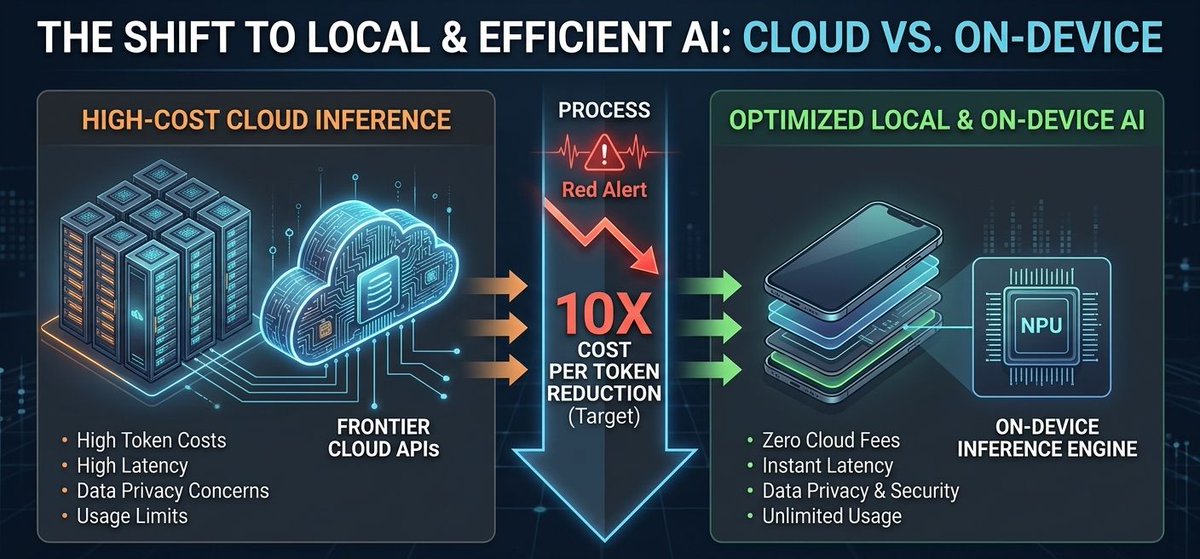
3/3 - This is a "Cost War." With open-source models reaching frontier-level intelligence, the center of gravity is shifting toward chips that prioritize performance-per-watt.
The era of $1,000/mo API bills is ending. The era of "AI Everywhere" has begun.
#Innovation #OpenSource
English