Sabitlenmiş Tweet

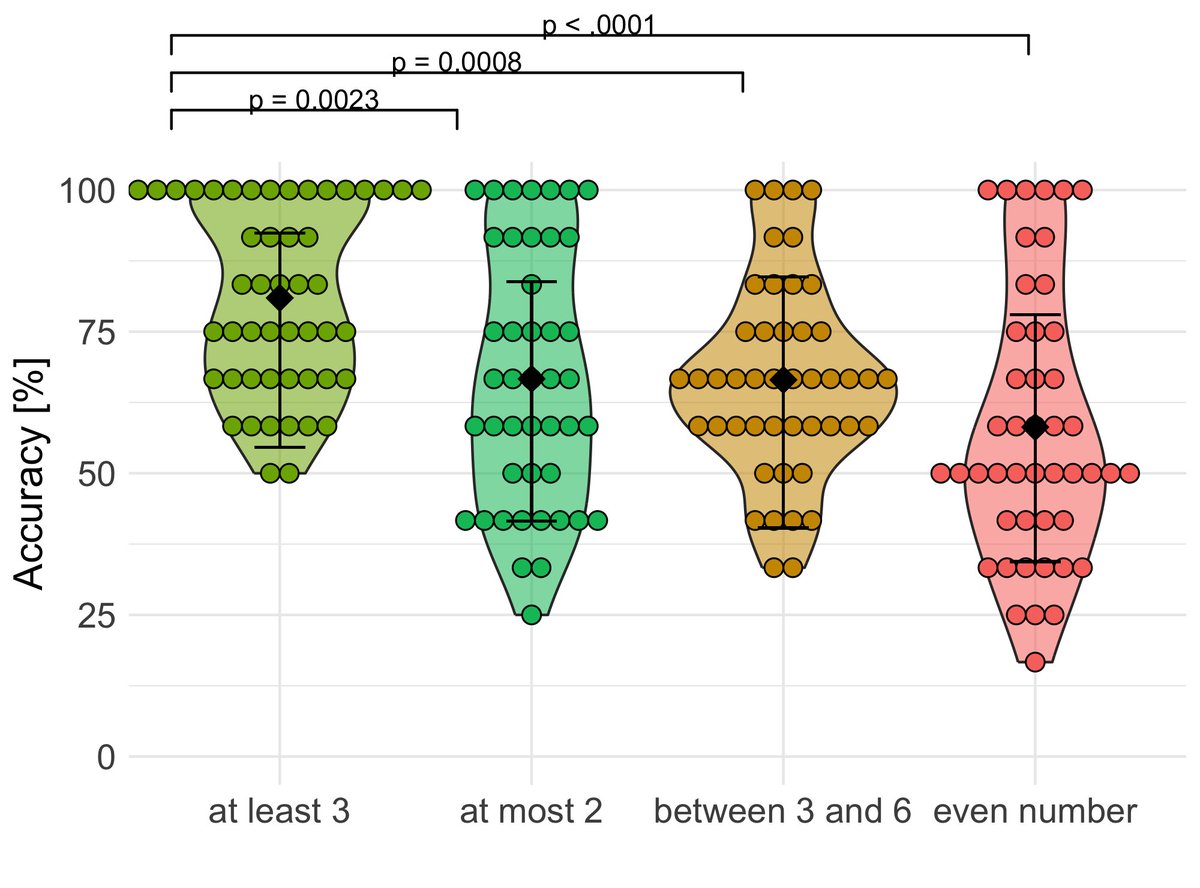
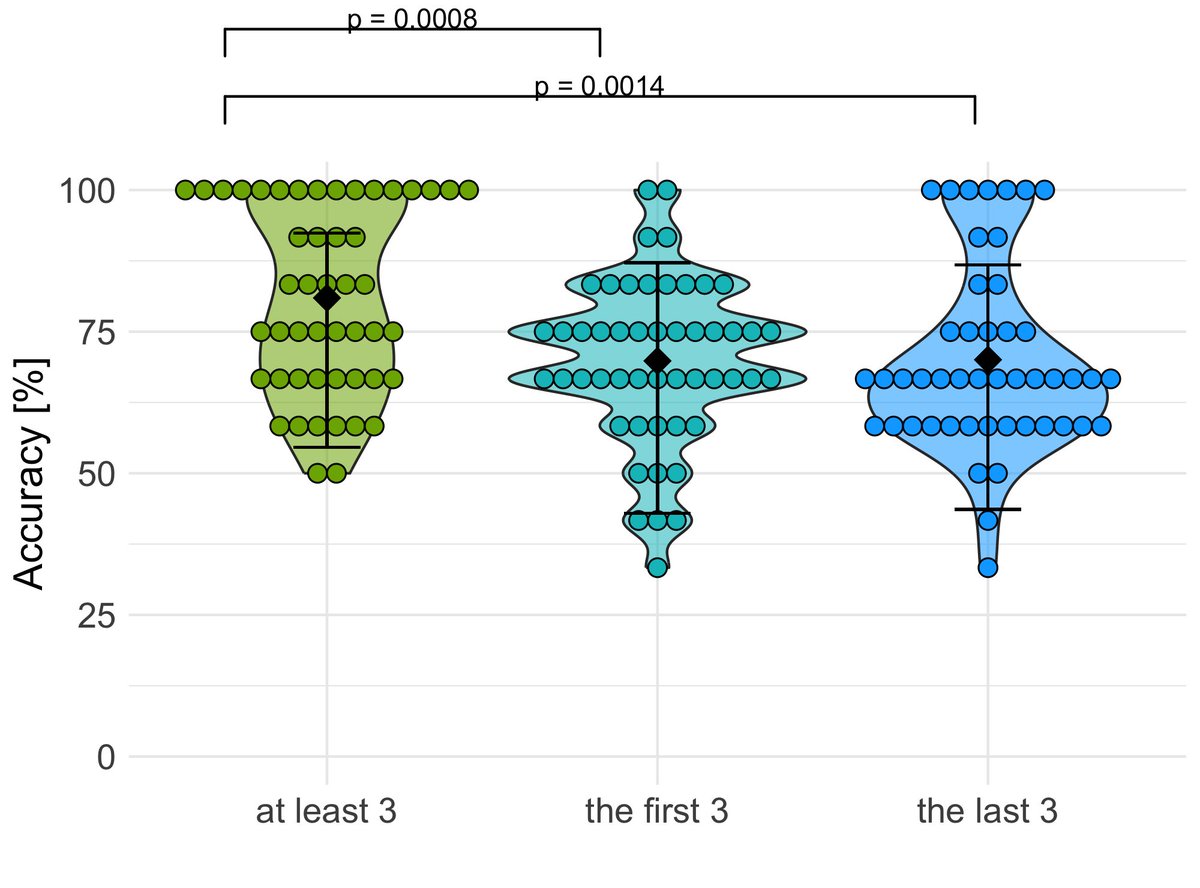
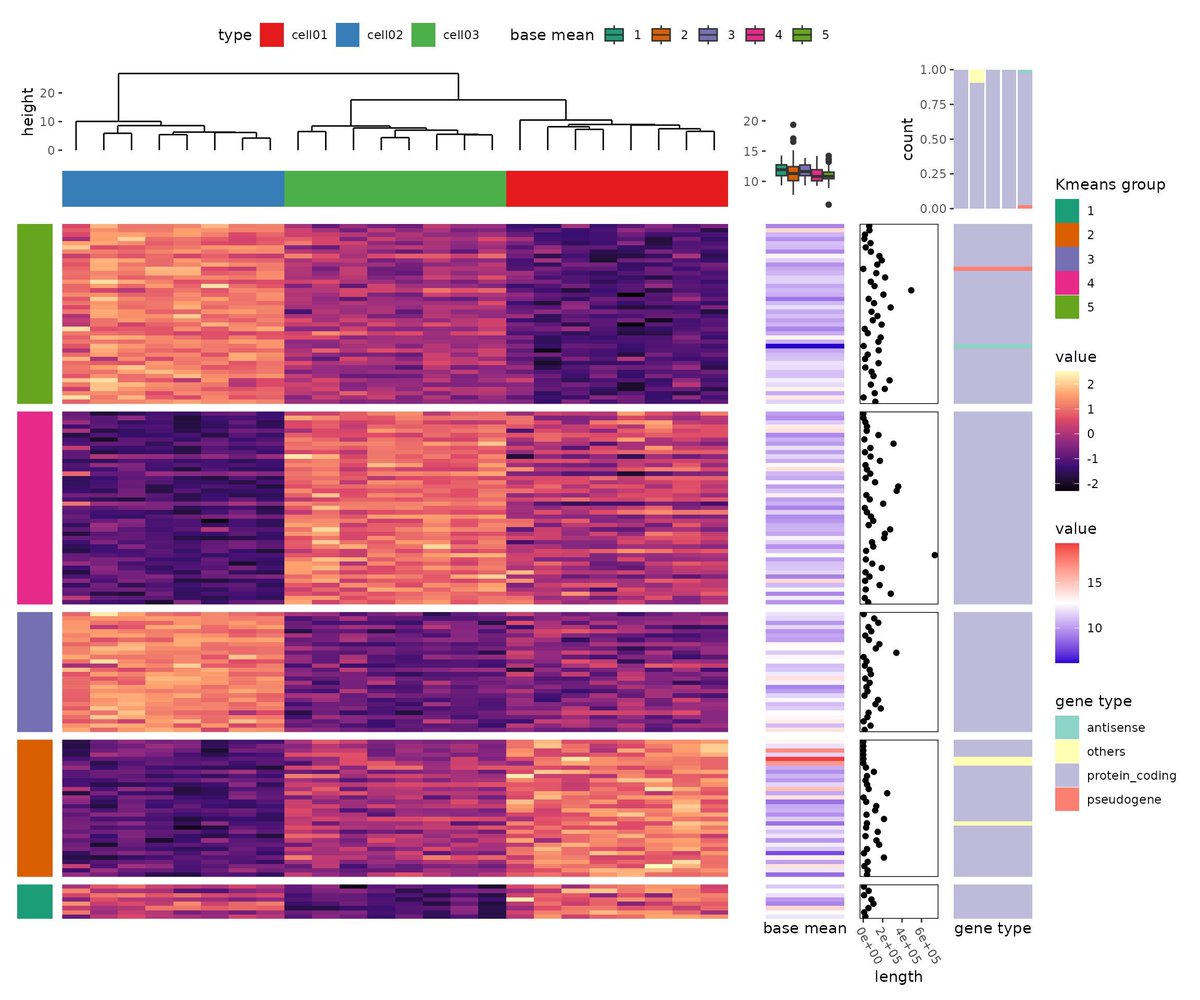
🎉 Excited to share my 1st PhD paper co-authored w/@MarelliMar & @Kathy_Rastle 🎉 It shows the quantity of word experience is not everything! it is also important the experience is consistently meaningful! Intrigued? Read the threads 👇 and the paper at: tinyurl.com/54rkmbud
English