Chris Staudinger retweetledi

30 resources to learn system design:
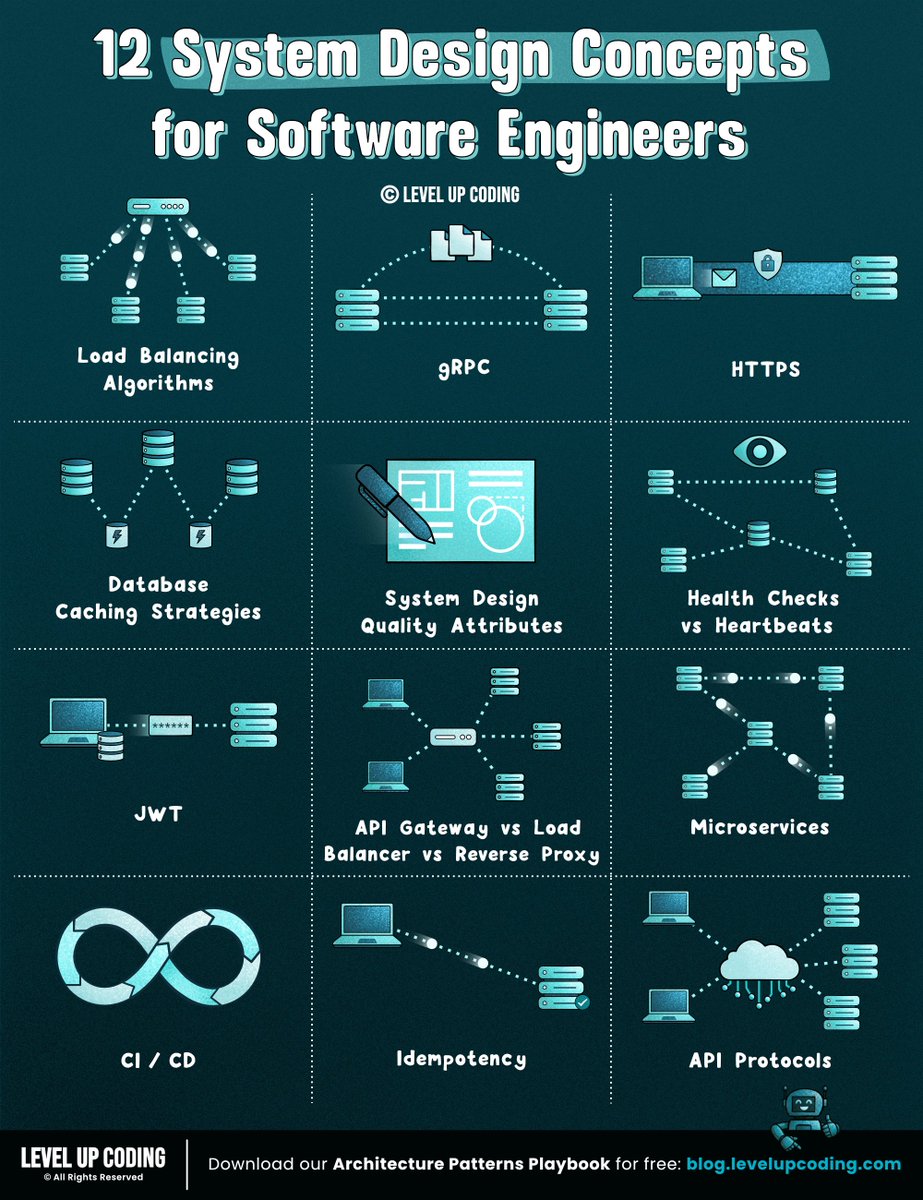
1. JWT: lucode.co/json-web-token…
2. gRPC: lucode.co/grpc-explained…
3. Microservices: lucode.co/microservices-…
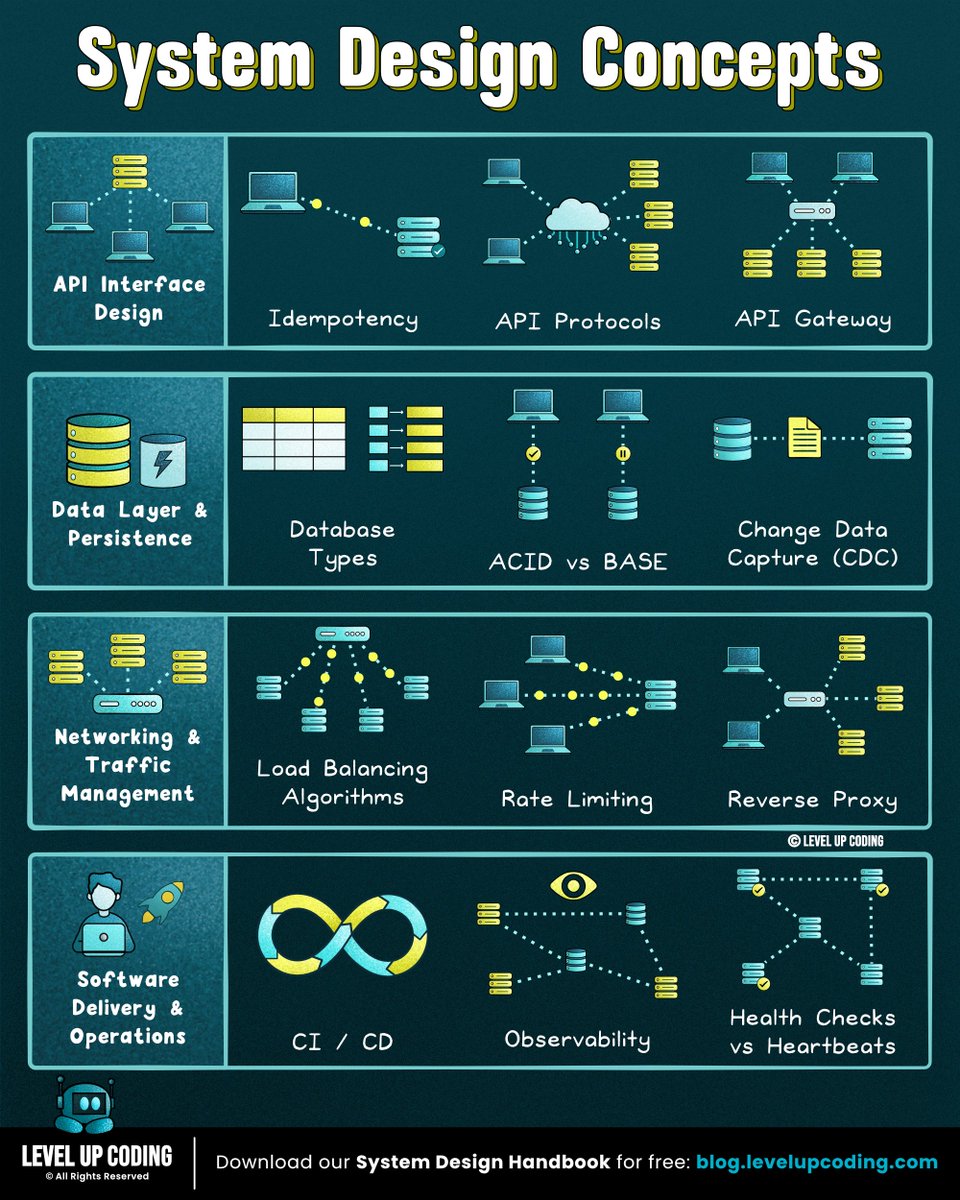
4. ACID vs BASE: lucode.co/acid-vs-base-l…
5. Rate limiting: lucode.co/rate-limiting-…
6. Event-driven architecture: lucode.co/event-driven-a…
PS - if you want a structured path, get our FREE 142-page System Design Handbook when you join our free weekly newsletter → lucode.co/system-design-…
7. System design quality attributes: lucode.co/system-design-…
8. Idempotency: lucode.co/idempotency-in…
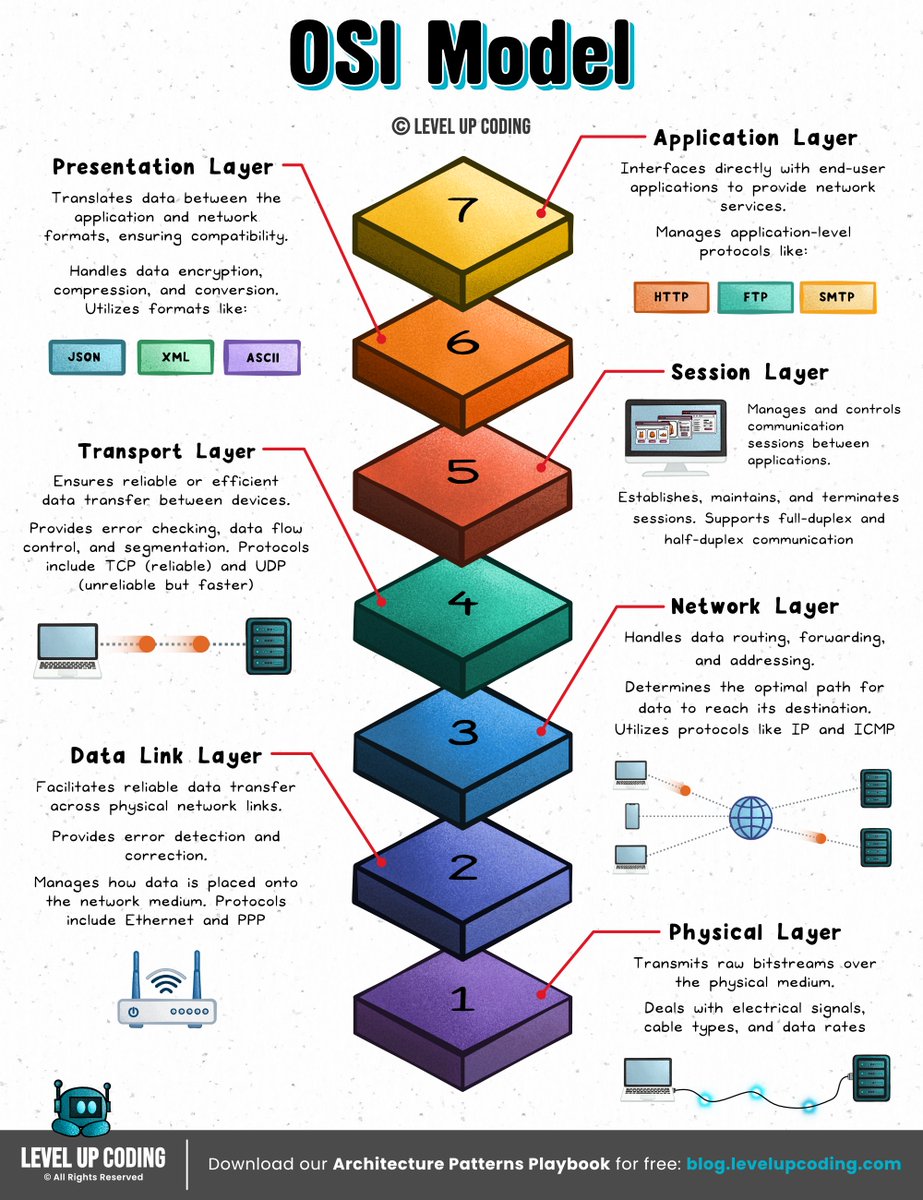
9. Network protocols: lucode.co/network-protoc…
10. Observability: lucode.co/observability-…
11. Change Data Capture (CDC): lucode.co/change-data-ca…
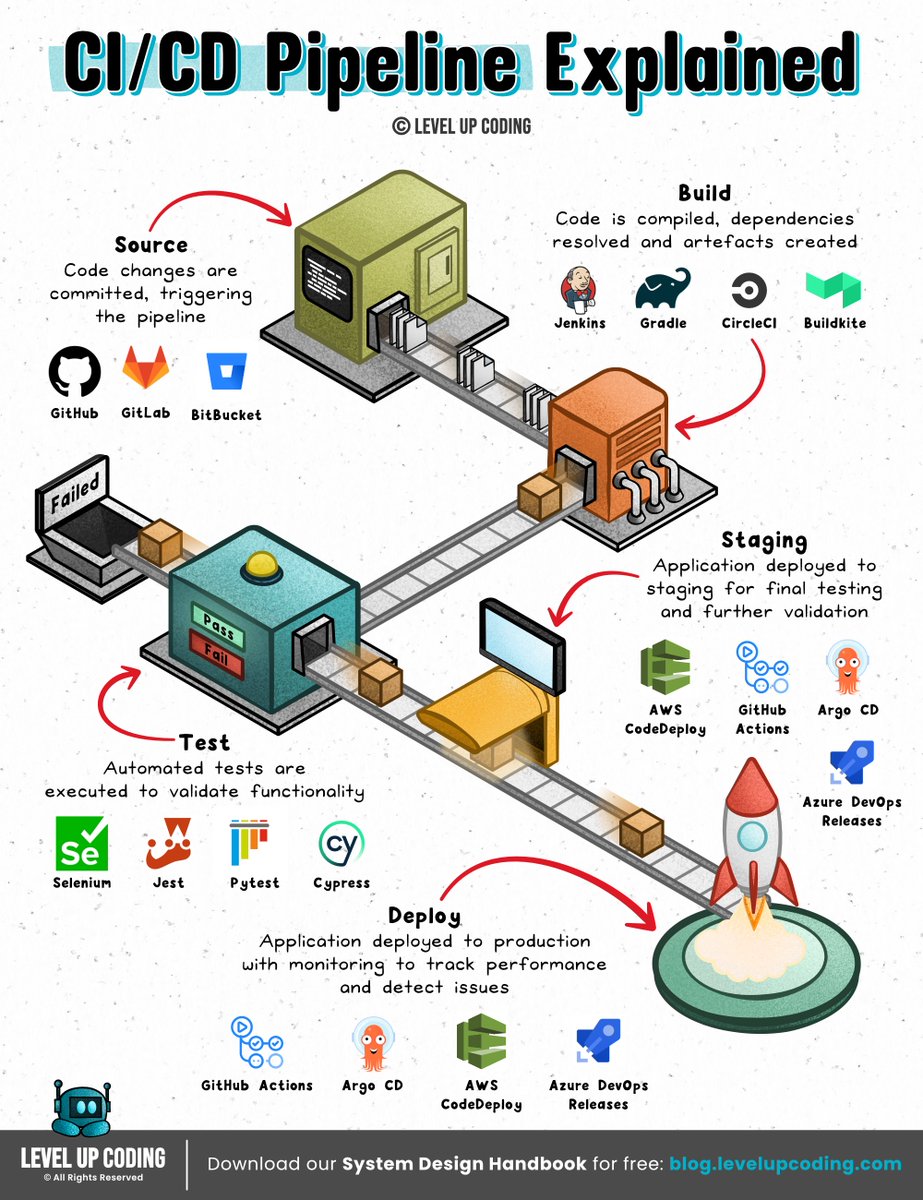
12. CI/CD pipelines: lucode.co/ci-cd-lil1nlsm
13. Database types: lucode.co/database-types…
14. CAP theorem: lucode.co/cap-theorem-li…
15. Health checks vs heartbeats: lucode.co/health-checks-…
16. API gateway vs load balancer vs reverse proxy: lucode.co/api-gateway-vs…
17. HTTPS: lucode.co/https-explaine…
18. Load balancing algorithms: lucode.co/load-balancing…
19. Database caching: lucode.co/database-cachi…
21. API protocols: lucode.co/api-architectu…
21. CDN: lucode.co/cdn-lil1nlsm
22. Database types: lucode.co/database-types…
23. Message Queues: lucode.co/message-queues…
24. Password storage & hashing: lucode.co/password-stora…
25. Service Discovery: lucode.co/service-discov…
26. Pub/Sub: lucode.co/pub-sub-lil1nl…
27. Connection pooling: lucode.co/connection-poo…
28. Forward proxy vs reverse proxy: lucode.co/forward-vs-rev…
29. Consistent hashing: lucode.co/consistent-has…
30. SQL vs NoSQL:lucode.co/sql-vs-nosql-l…
What else should be on the list?
What concepts would you like me to cover?
——
👋 PS: Get our FREE 142-page System Design Handbook when you join our free weekly newsletter.
Join 31,000+ engineers → blog.levelupcoding.com/p/system-desig…
——
♻️ Repost to help others learn system design.
➕ Follow me ( Nikki Siapno ) to become good at system design.
English