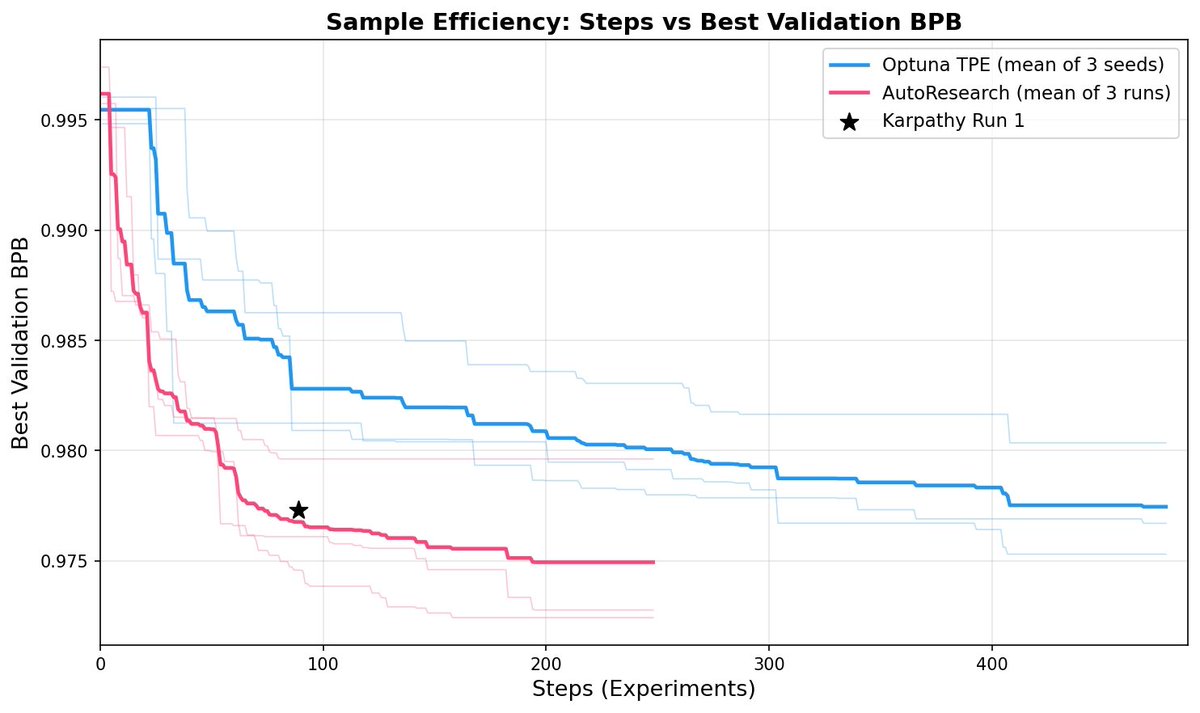
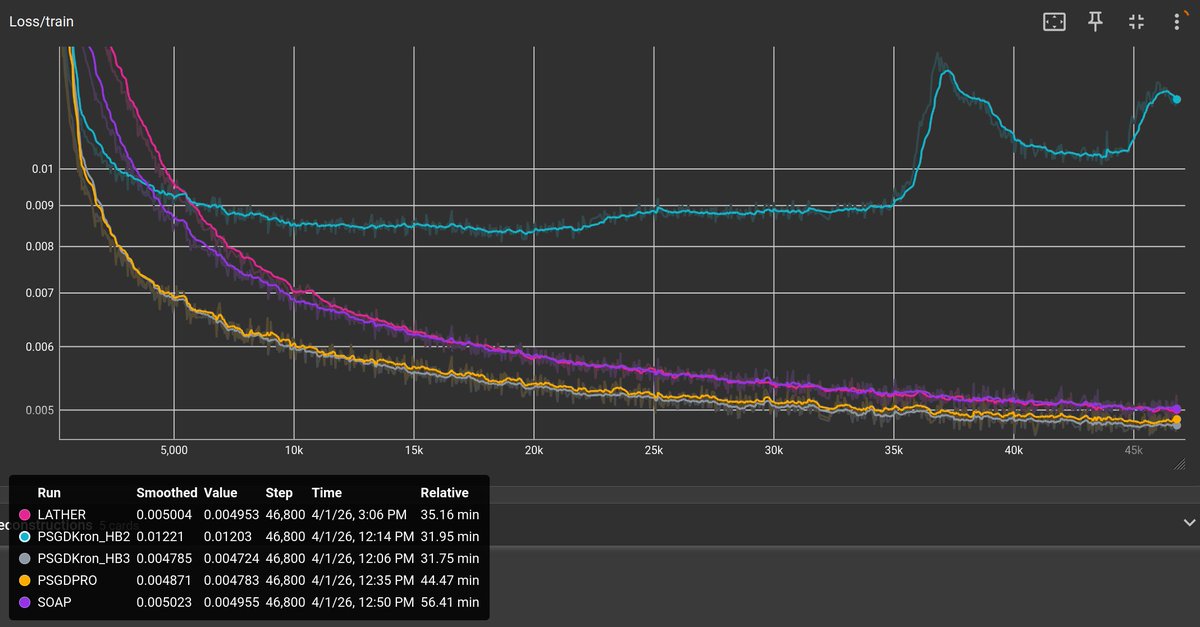
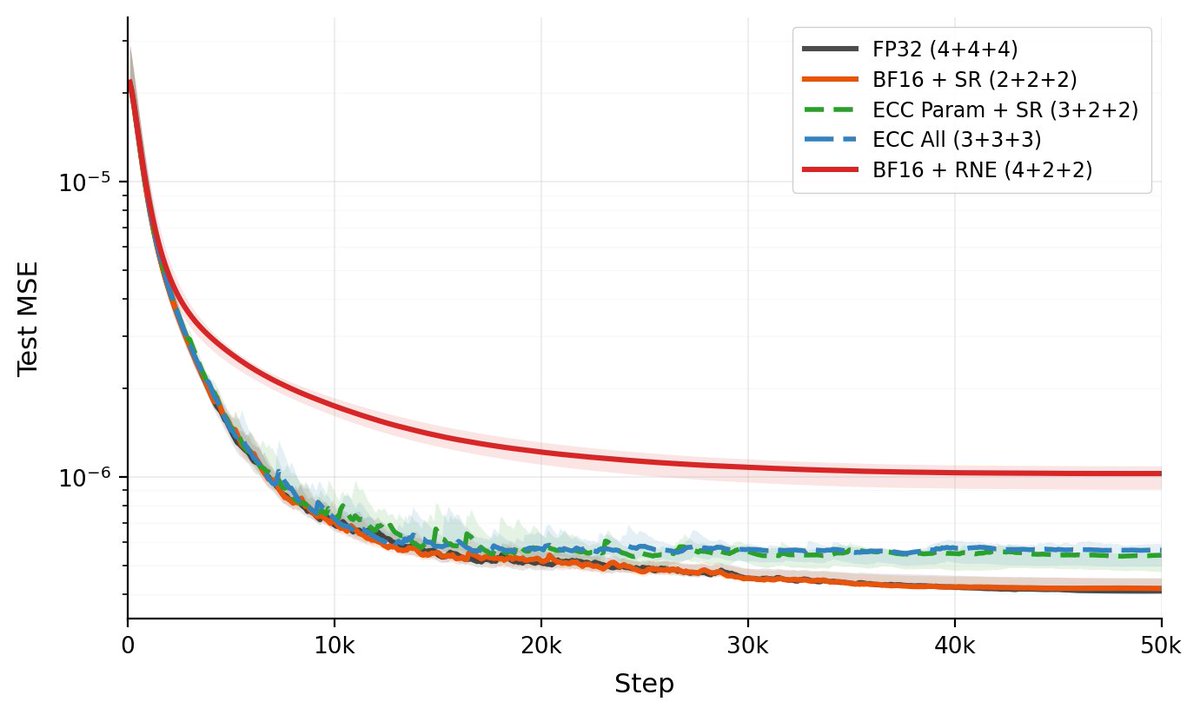
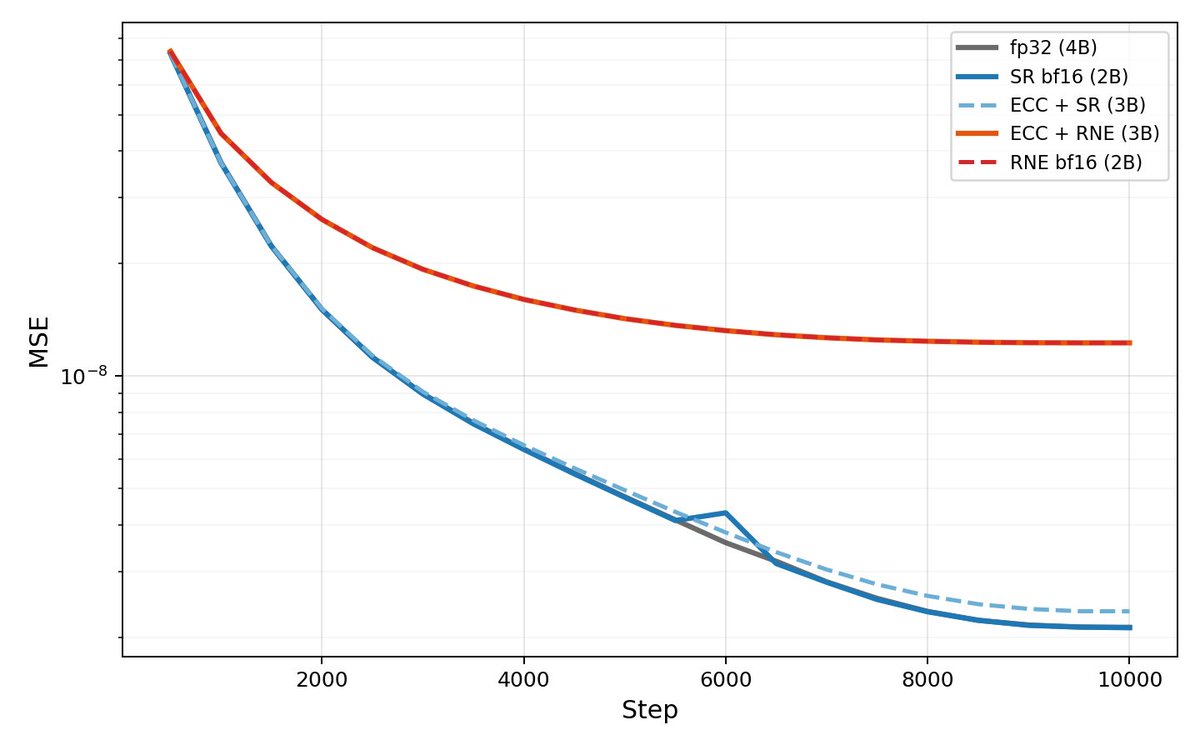
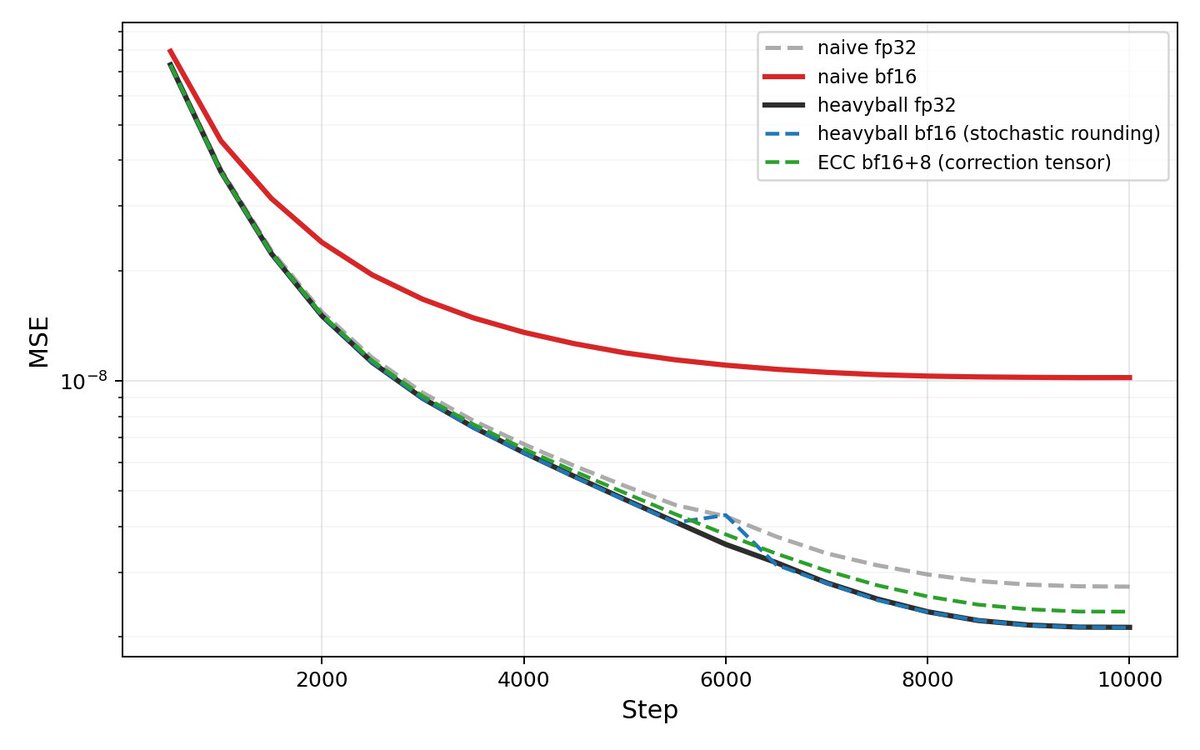
A few notes:
1) The LayerNorms are copied as-is from Qwen 3
2) The per-group scales are absmean, not learned (#L44-L47" target="_blank" rel="nofollow noopener">github.com/PrismML-Eng/ll…)
3) Depth-based patterns appear through classical optimization, it's unlikely some layers (like embeddings) are treated differently
4) Given the bit similarity, it likely warm-started from Qwen and did O(1000) finetuning steps to recover lost performance. We can't know what algorithm was used here, but the weight pattern hints at AdamW. Based on (2), it's likely a BitNet variant.
English