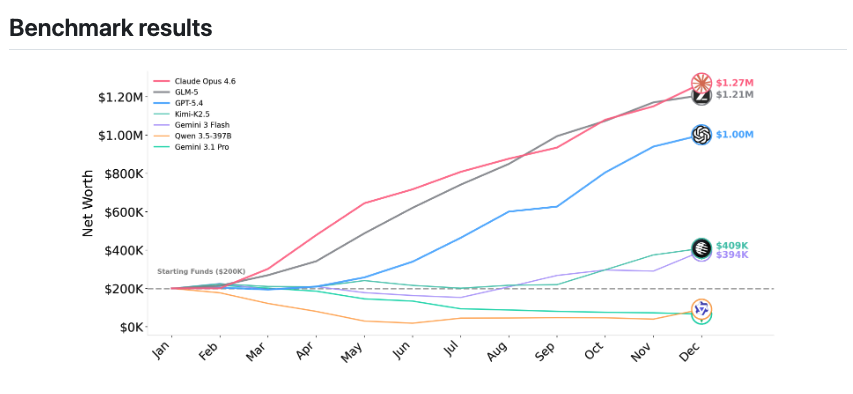
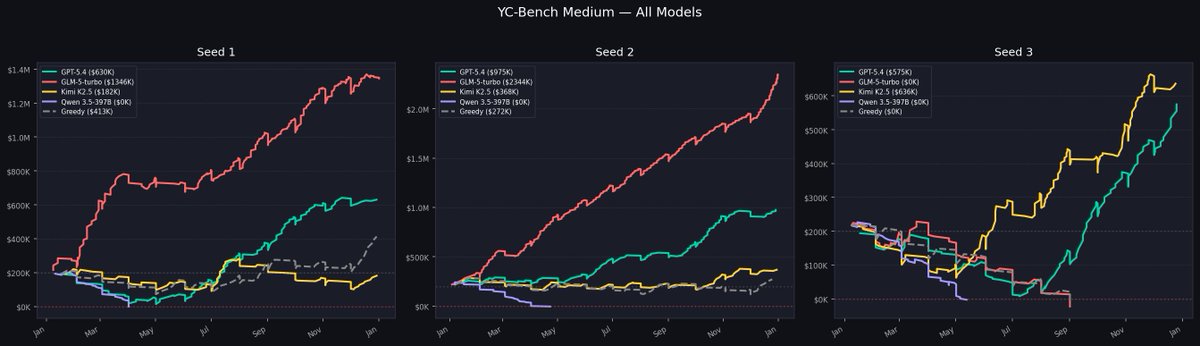
We discovered significant gaps between open and closed sourced models on our realistic computer-use-agent tasks, and it is a data problem.
Although open models have nearly saturated OSWorld, we found that kimi k2.6 cannot do tasks that GPT-5.4 solves in 50 steps.
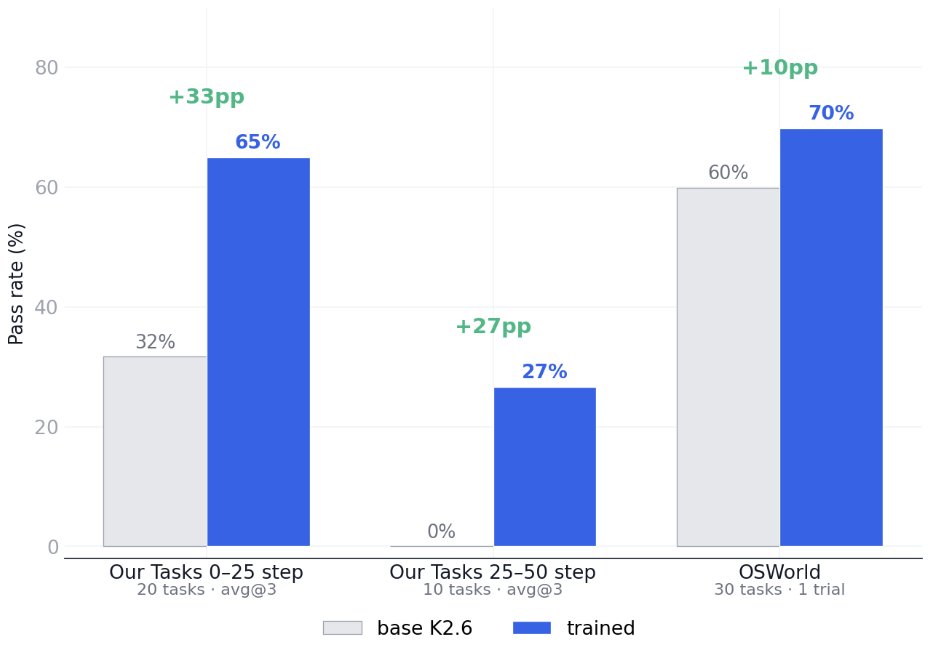
Our 30 tasks are realistic: the agent works with an open source version of Office Suit in an linux OS, and compiles excel sheets. GPT-5.4-high solves 2/3 in 25 steps, and 1/3 in 50 steps. Kimi k2.6, the strongest open model on OSWorld, fails almost all of them.
We understand the problem to be very simple: open models simply are not trained on realistic CUA data enough. To test this hypothesis, we simply RL-ed Kimi K2.6 on 10 in-domain CUA office tasks with LoRA.
The result of the simplistic RL is a significant increase of +30% in the capacity to do office tasks. However, the improvement gracefully carries over to OSWorld itself: on a stratified subset of 30 tasks, the RL-ed model sees another +10% lift.
The takeaway from our initial results is that CUA models suffer from unrealistic, low-quality data. As a result, we are continually building realistic apps / RL environments to bridge the gap. More to come.
Solid work done by @alckasoc
English