Andrej Karpathy@karpathy
New post: nanochat miniseries v1
The correct way to think about LLMs is that you are not optimizing for a single specific model but for a family models controlled by a single dial (the compute you wish to spend) to achieve monotonically better results. This allows you to do careful science of scaling laws and ultimately this is what gives you the confidence that when you pay for "the big run", the extrapolation will work and your money will be well spent. For the first public release of nanochat my focus was on end-to-end pipeline that runs the whole LLM pipeline with all of its stages. Now after YOLOing a few runs earlier, I'm coming back around to flesh out some of the parts that I sped through, starting of course with pretraining, which is both computationally heavy and critical as the foundation of intelligence and knowledge in these models.
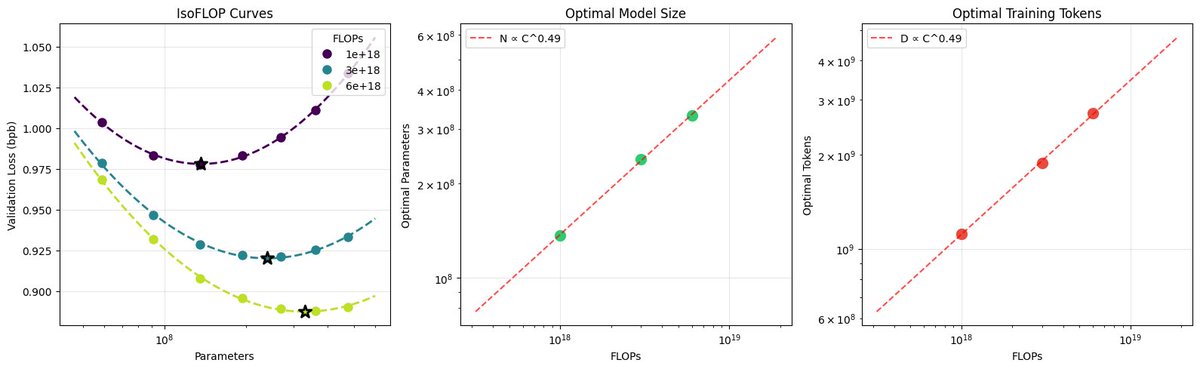
After locally tuning some of the hyperparameters, I swept out a number of models fixing the FLOPs budget. (For every FLOPs target you can train a small model a long time, or a big model for a short time.) It turns out that nanochat obeys very nice scaling laws, basically reproducing the Chinchilla paper plots:
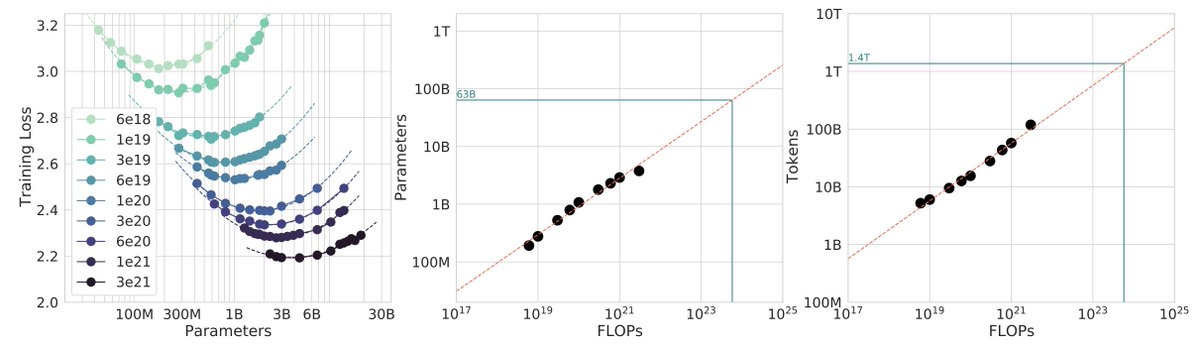
Which is just a baby version of this plot from Chinchilla:
Very importantly and encouragingly, the exponent on N (parameters) and D (tokens) is equal at ~=0.5, so just like Chinchilla we get a single (compute-independent) constant that relates the model size to token training horizons. In Chinchilla, this was measured to be 20. In nanochat it seems to be 8!
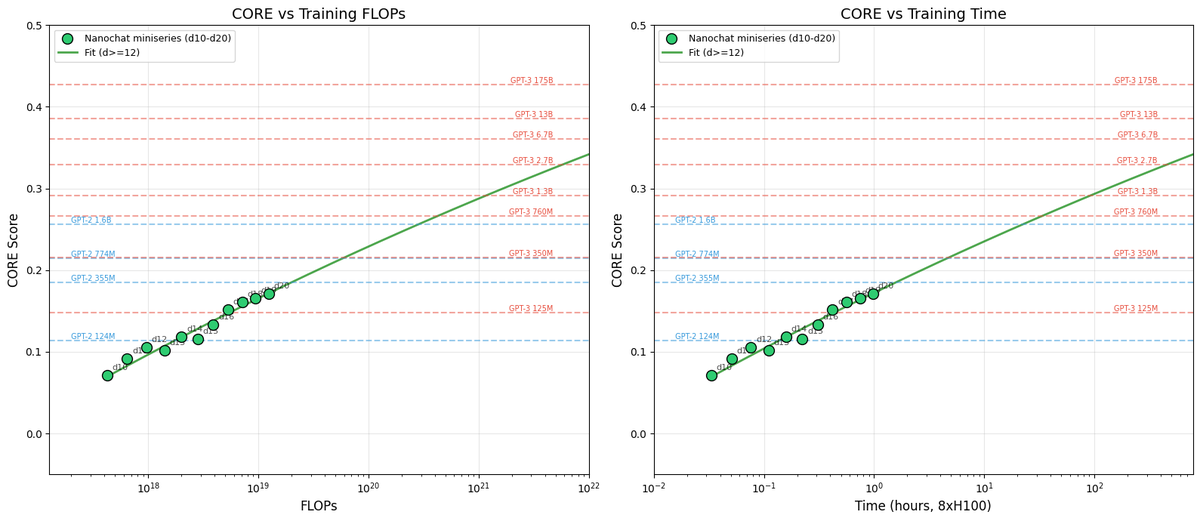
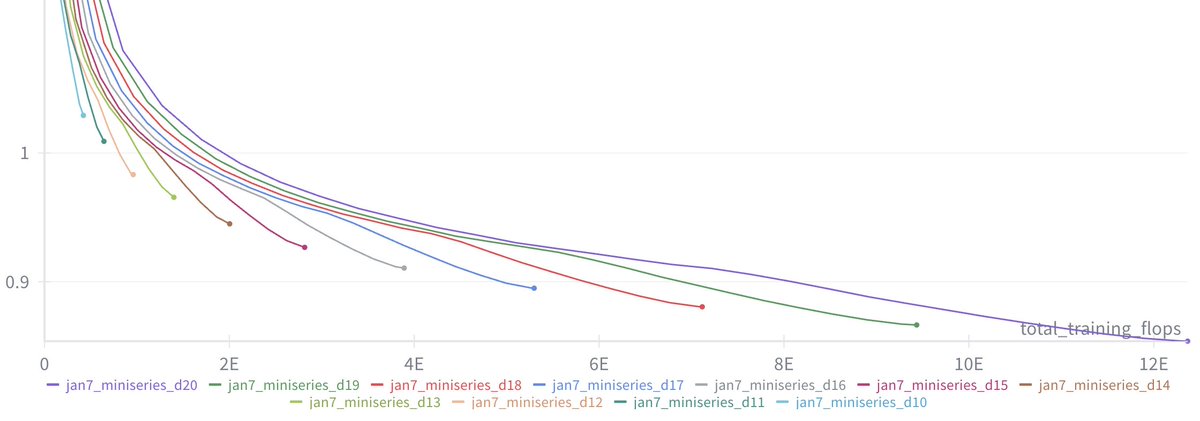
Once we can train compute optimal models, I swept out a miniseries from d10 to d20, which are nanochat sizes that can do 2**19 ~= 0.5M batch sizes on 8XH100 node without gradient accumulation. We get pretty, non-itersecting training plots for each model size.
Then the fun part is relating this miniseries v1 to the GPT-2 and GPT-3 miniseries so that we know we're on the right track. Validation loss has many issues and is not comparable, so instead I use the CORE score (from DCLM paper). I calculated it for GPT-2 and estimated it for GPT-3, which allows us to finally put nanochat nicely and on the same scale:
The total cost of this miniseries is only ~$100 (~4 hours on 8XH100). These experiments give us confidence that everything is working fairly nicely and that if we pay more (turn the dial), we get increasingly better models.
TLDR: we can train compute optimal miniseries and relate them to GPT-2/3 via objective CORE scores, but further improvements are desirable and needed. E.g., matching GPT-2 currently needs ~$500, but imo should be possible to do <$100 with more work.
Full post with a lot more detail is here:
github.com/karpathy/nanoc…
And all of the tuning and code is pushed to master and people can reproduce these with scaling_laws .sh and miniseries .sh bash scripts.