

Comet retweetledi

I just interviewed the former CTO at IBM and Chairperson of NodeJS.
Here's what I learned:
Michael @maximilien spent 12 months shipping production RAG to multiple customers.
In our discussion, he told me that nothing on a leaderboard can predict what works until you evaluate your customers' data.
Which I found interesting because...
Most teams treat RAG like a setup task.
Pick a vector database.
Pick OpenAI embeddings.
Ship it.
Then spend months “vibe-checking” results.
But production RAG doesn’t work like that.
It's more of an iteration loop rather than a setup problem.
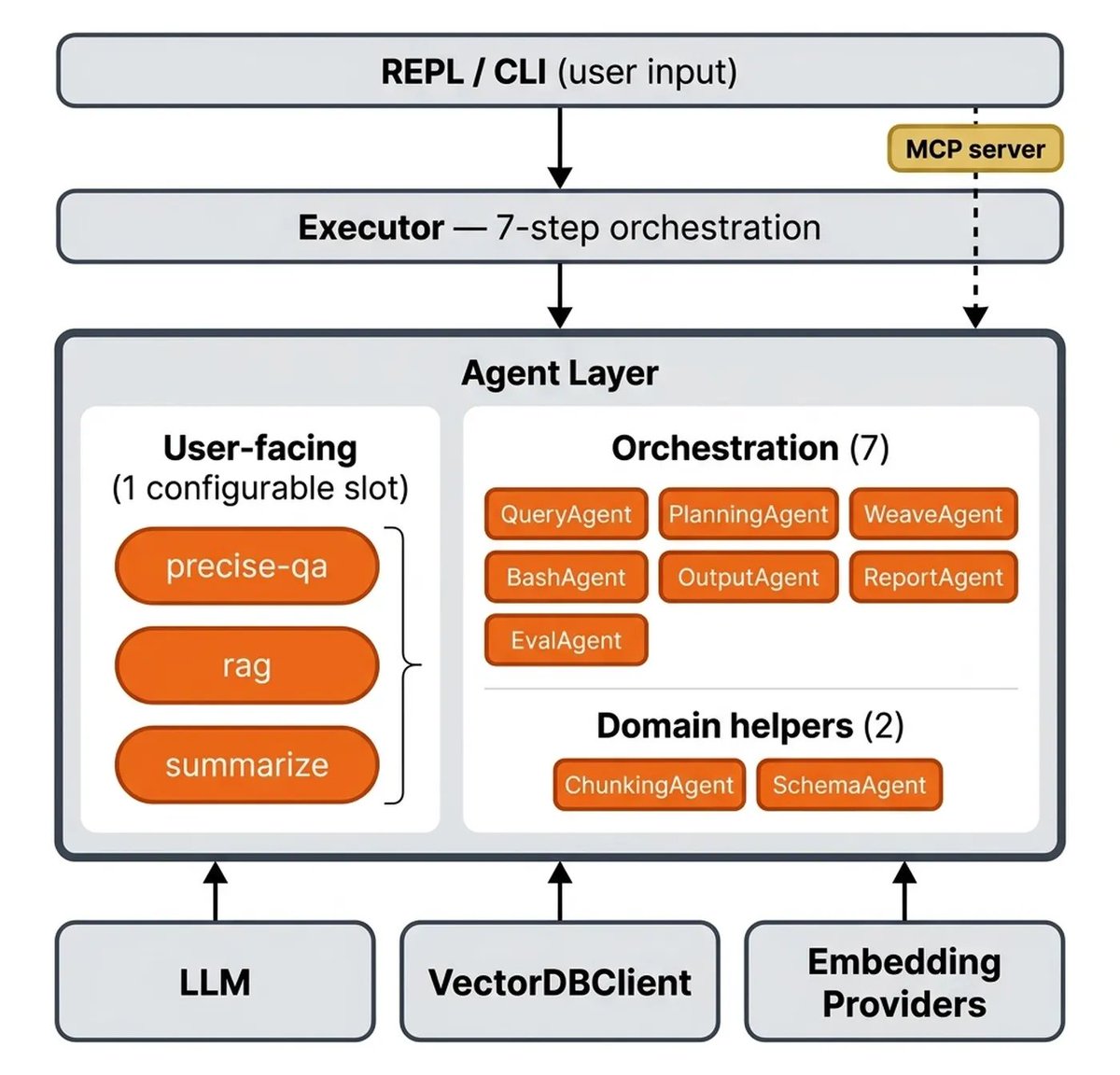
Stitch → evaluate → iterate
A real system has multiple moving parts.
You don’t pick one...
You swap and measure each one.
Here’s what that looks like in practice:
1. Build a small eval set from real user questions
2. Build your evaluator (e.g., LLM Judge) against that dataset
3. Align your evaluator with human feedback (before trusting scores)
4. Iterate cheapest-first (retrieval → embeddings → infra)
To make this work, you also need visibility across runs.
This is where tools like Opik by @Cometml come in...
Tracking each experiment so you can compare models, configs, and results over time.
But most teams refuse to do this because it's extremely cumbersome.
• Re-ingestion takes time
• Pipelines break
• Comparisons become unreliable
So people default to benchmarks instead.
But that doesn't mean it's better.
On a real customer dataset (auction listings), Michael @maximilien swapped only the embedding model.
An open-source model ranked #130 on MTEB beat OpenAI:
• +11% quality
• 240x faster re-embedding
• 50% smaller vectors
• $0 cost
Here's the gist...
RAG is not about picking the best tools.
It’s about measuring what works for your data.
Until you do that…
You’re just guessing.
Full interview and breakdown here: decodingai.com/p/ship-rag-wit…
English











