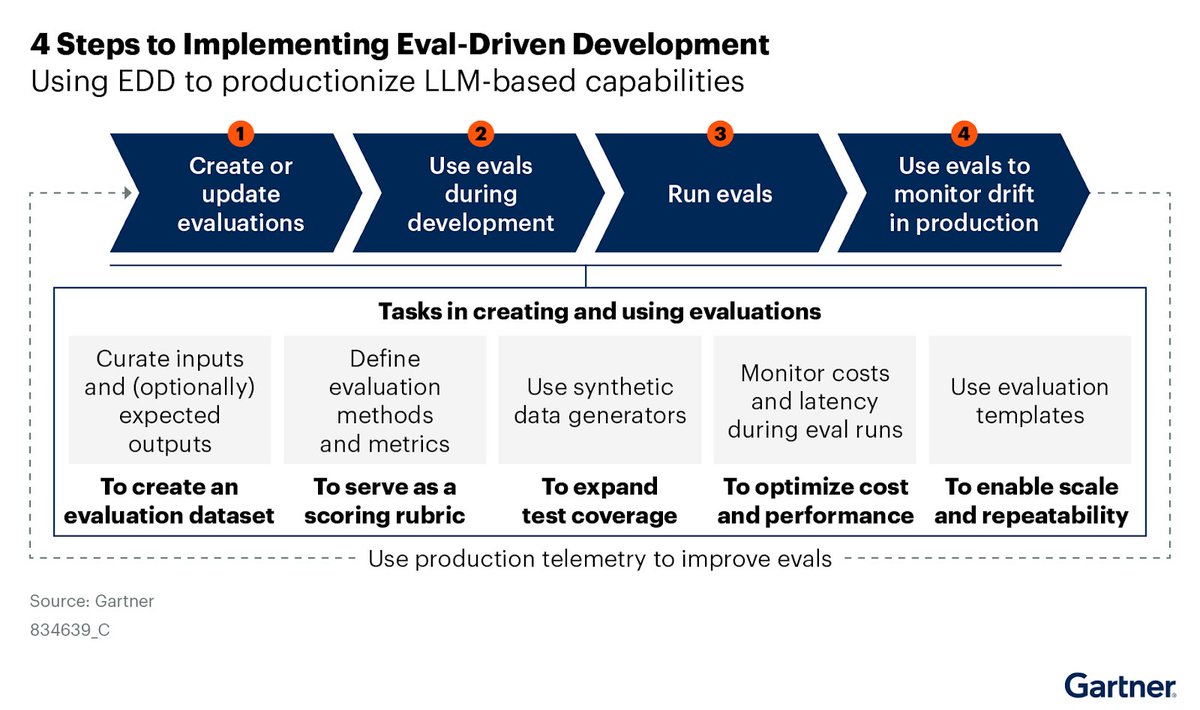
Comet retweetledi

See you soon for a live discussion of "A Benchmark for Evaluating Outcome-Driven Constraint Violations" with Qi Li, PhD of @mcgillu!
luma.com/mw7njzug
English
Comet
3.5K posts


@Cometml
Comet provides an end-to-end model evaluation platform for AI developers, with best in class LLM evaluations, experiment tracking, and production monitoring