
Common Crawl Foundation
1.5K posts

Common Crawl Foundation
@CommonCrawl
Common Crawl is a non-profit foundation dedicated to the Open Web.
San Francisco, CA Katılım Şubat 2010
1.6K Takip Edilen7.8K Takipçiler
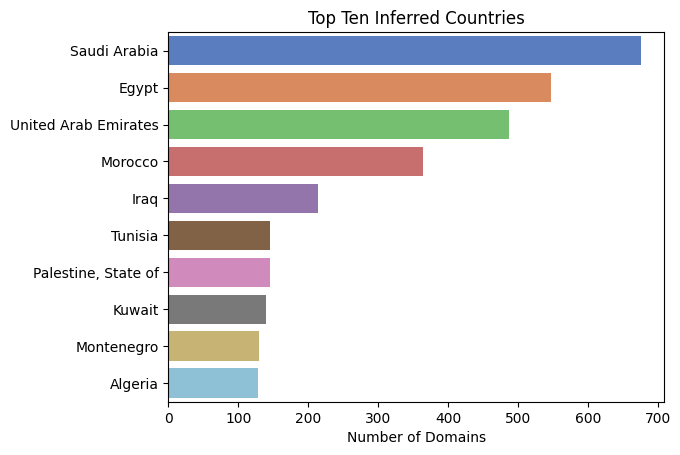
Turning 30,000 Arabic Domains Into a Better Crawl
How we filtered, geolocated and categorised a donation of Arabic seed domains
English
Common Crawl Foundation at LREC 2026
The Common Crawl team attended the 16th International Conference on Language Resources and Evaluation in Palma, Mallorca, co-organizing a tutorial, presenting recent published work, and strengthening links with the research community.

English
On 29th October 2026, the Web-as-Corpus Workshop will return for its 13th edition, co-located with EMNLP 2026 in Budapest. The organising committee includes engineers from the Common Crawl Foundation alongside researchers from the Jožef Stefan Institute, the University of Oslo, and the University of Turku.
commoncrawl.org/blog/13th-web-…
English

Hi everyone,
Our June 2026 Crawl Archive and corresponding Web Graph are now available.
The June 2026 crawl consists of 2.10 billion web pages (or 354 TiB of uncompressed content). Captures are from 40.8 million hosts or 33.6 million registered domains.
The corresponding Web Graph release consists of 247.3 million nodes and 6.3 billion edges at the host level, and 121.1 million nodes and 3.9 billion edges at the domain level.
Live long and prosper!
Luca / @whitenoise
English
The May 2026 crawl archive (CC-MAIN-2026-21) is now also available on our HF bucket. 🤗
huggingface.co/buckets/common…
English
Common Crawl Foundation at IIPC-WAC 2026
Common Crawl was well represented with contributions at the 2026 IIPC Web Archiving Conference and General Assembly.

English
CommonLID Update: New Tools, Growing Impact
CommonLID, a community-built language ID benchmark, has a new website and interactive leaderboard. Its paper was accepted to ACL 2026, with a poster session on 7 July. Source code, a PyPI package, and the dataset are now available.
English
The Columnar Index Is Now the URL Index
We have renamed the Columnar Index to the URL Index, to be clearer about its purpose and to pave the way for more datasets in a columnar format.
commoncrawl.org/blog/the-colum…
English
English
Introducing the AI Visibility Audit
A free guide for SEOs and GEOs on how to check whether AI systems can actually reach a site, and how to stay visible in the crawl that trains them.

English
RSVP and join speakers Laurie Burchell and Pedro Ortiz Suarez from the Common Crawl Foundation and Kostis Saitas Zarkias and Robert Pugh from Mozilla Data Collective for a truly hands-on session.
Thursday, June 4th 6 PM CEST | 12 PM ET | 9 AM PDT Register via Zoom: zoom.us/meeting/regist…
English
Under-represented languages deserve better tools! On June 4th, The Common Crawl Foundation and Mozilla Data Collective will host a webinar to test language identification for the languages you care about.

English
May 2026 Crawl Archive Now Available
We are happy to announce the release of the May 2026 crawl archive, consisting of 2.16 billion web pages, or 365.56 TiB of uncompressed content.
📷
English