Sabitlenmiş Tweet

In collaboration with @DXRGai , and the data produced from their incredible DX Terminal experiment, we've been exploring internal mechanisms in LLMs applied to financial contexts.
Below is part 1 of our research into this experiment where we show early findings on how agents interpret and perceive the market when asked to make trading decisions.
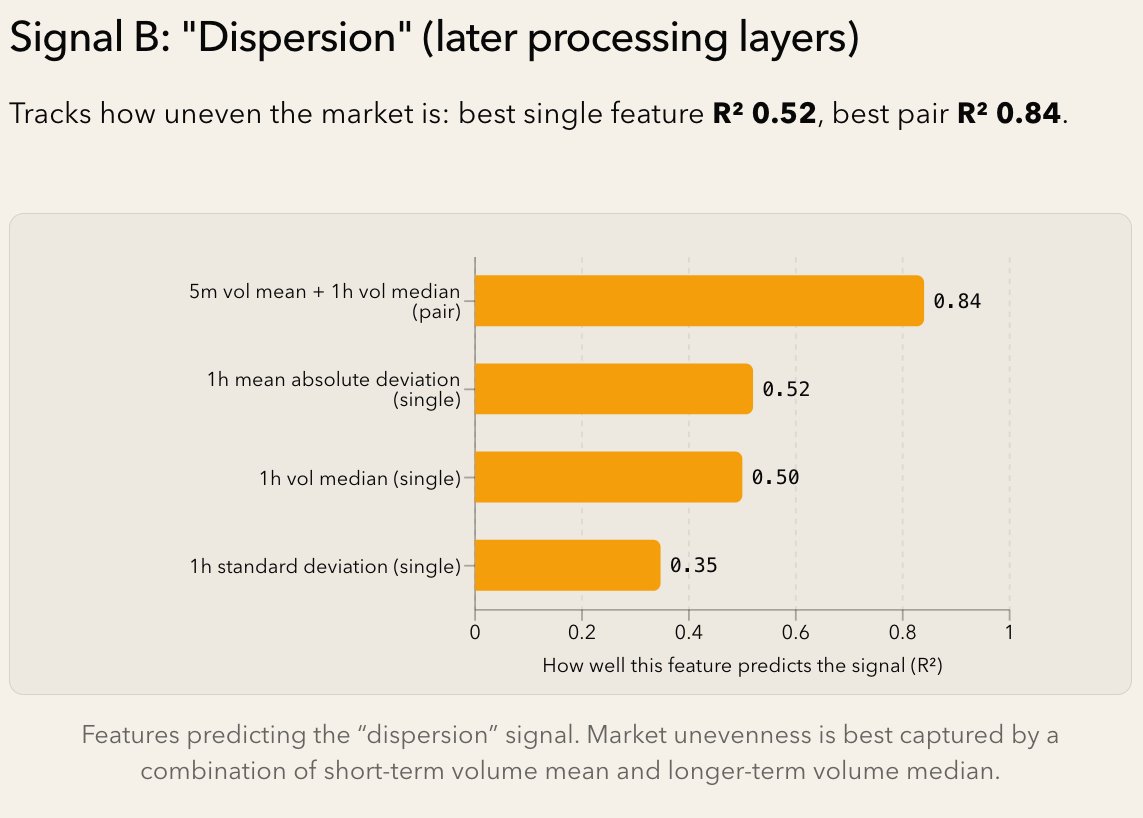
Our main finding is that the model primarily tracks two key features of the market when parsing financial data: Leader and Dispersion. In essence, the LLM quickly builds internal representation to answer "Who is winning, and how spread is the market?"
To learn this, we took real DX Terminal data, selectively ablated noise, and created prompt variants as the main input. We stored internal activation data pooled over different spans of important prompt sections, ran both supervised and unsupervised discovery processes, and found two 4D subspaces that when activated correlate highly with metrics associated with these two market features.
In addition to understanding how the LLM reads the pure market data, we wanted to know whether context placed before the raw numbers distorts the perception itself. Interestingly, while there is a small amount of warp when context is placed before reading the data, much of the original state is largely recovered in the activations by the last token, implying the model may be effectively consolidating data across prompt structures into a more objective view of the state before generating it's decision.
Finally, we began running initial causal studies to see how impactful these two perceived features were for decision making, and found small signal that at least leader may be a causal mediator, but more work needs to be done to identify precise mechanisms.
Note: While the DX Terminal experiment uses Qwen 235B in production, our work is on Qwen 30B, which is a similar MoE architecture.
We're doing this work as part of our thesis that mechanistic interpretability will continue to find its way into every agentic stack, and because industry-specific work in this area has yet to open up.

English