Sabitlenmiş Tweet
CyberKnow
9.5K posts


CyberKnow
@Cyberknow20
Situational Awareness | Threat Intelligence | cybertracker | Hacktivism | Meme Farmer Digital Owl of the Cyber Realm Posts and Opinions are my own
Katılım Temmuz 2020
2.9K Takip Edilen37K Takipçiler

Vague reference to a business somewhere doing something with AI then automatically applies to the global job market.
This is peak FUD farming by an account with millions of followers. It's starting to undermine the positives of AI.
Andrew Yang🧢⬆️🇺🇸@AndrewYang
“Companies that had 10 people running fulfillment are now doing it with 3 and a few AI tools. These jobs aren’t coming back.” - a small business operations expert in the Midwest. Extrapolate that through the economy and its going to get extraordinarily rough out there.
English


Opsec is not as important as the Strava rep. @JAParker29 🫠
Clash Report@clashreport
A French naval officer unknowingly revealed the location of the aircraft carrier Charles de Gaulle by sharing a public workout on the fitness app Strava. His run, recorded at sea, made it possible to pinpoint the carrier’s position in the Mediterranean near Cyprus. Although the carrier’s deployment was public, sharing its exact real-time location is a serious security risk. Source: Le Monde
English
@UK_Daniel_Card I think you could take this take and apply it across multiple decades
- TV was the villian
- Social Media was the villian
- AI is the villian
But as you said its just a human thing. Im sure folks in a cave long ago argued about hot Fire would make them lazy.
English

'We are going to have a large population with absolutely no critical thinking skills if they blindly trust AI for everything.'
honestly this is not an AI thing, this is a humanity thing, think about the disinformation on Facebook (and other social media platforms)
look at the average IQ.
Alex Freberg@Alex_TheAnalyst
I'm going to call this right now. We are going to have a large population with absolutely no critical thinking skills if they blindly trust AI for everything. We have all already seen it. They don't validate outputs. They don't really understand anything. They just ask questions, it looks good, and they go with it. There are going to be huge issues in every company as this continues over the years. The amount of technical debt and knowledge gaps are going to be insane. So much opportunity if you actually know what you're doing.
English


@SpencerHakimian Did this warrant "breaking" and capitalise wording?
FUD farming is on point I guess
English

🚨BREAKING: CLAUDE SAYS THE BASE CASE FOR THE WORLD IS GENUINELY TERRIFYING
English
@foilmanhacks Several hacktivist groups are leaning into doing this.
English

@Cyberknow20 LMAO this is the fucking lamest hack I have ever heard of.
Jesus imagine bragging about this.
This is literally one Shodan search away, probably no password nada.
English

CyberKnow retweetledi
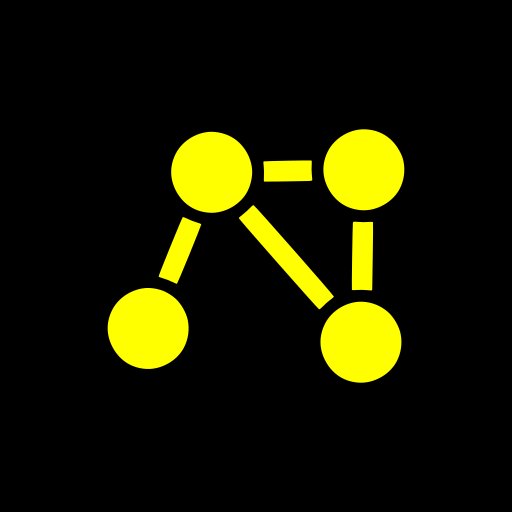
⚠️ Update: The internet blackout in #Iran has entered its 19th day with international connectivity still unavailable after 432 hours to all but a chosen few.
As the world debates if or how the war should proceed, one voice is effectively missing: the voice of the Iranian people.

English
BREAKING: Guy selling something says everyone wants to buy that thing.
This has never happened before in capitalism's history!!!!!!
Polymarket@Polymarket
BREAKING: Nvidia CEO Jensen Huang predicts $1,000,000,000,000.00 in revenue from AI chips through 2027.
English
Current AI discourse: someone shares research that contradicts AI techbro FUD and the first comments aren't acknowledging or debating the research. They just simply say "you wait, it will get better, just give it "insert timeframe"
It really diminishes the heath of AI discourse
Priyanka Vergadia@pvergadia
🤯BREAKING: Alibaba just proved that AI Coding isn't taking your job, it's just writing the legacy code that will keep you employed fixing it for the next decade. 🤣 Passing a coding test once is easy. Maintaining that code for 8 months without it exploding? Apparently, it’s nearly impossible for AI. Alibaba tested 18 AI agents on 100 real codebases over 233-day cycles. They didn't just look for "quick fixes"—they looked for long-term survival. The results were a bloodbath: 75% of models broke previously working code during maintenance. Only Claude Opus 4.5/4.6 maintained a >50% zero-regression rate. Every other model accumulated technical debt that compounded until the codebase collapsed. We’ve been using "snapshot" benchmarks like HumanEval that only ask "Does it work right now?" The new SWE-CI benchmark asks: "Does it still work after 8 months of evolution?" Most AI agents are "Quick-Fix Artists." They write brittle code that passes tests today but becomes a maintenance nightmare tomorrow. They aren't building software; they're building a house of cards. The narrative just got honest: Most models can write code. Almost none can maintain it.
English
@lukOlejnik @openclaw I may have missed it, first time looking at the platform, but is it collating media reporting and summarising it into a paragraph? Not sure i saw assessment
English

Who said AI agents like @openclaw can't do geopolitical assessments in tandem? Japan rejected sending warships to Hormuz. Australia also rejected. Trump named China, France, Japan, South Korea, UK as desired partners, warned NATO faces "very bad" future. Second Trump-Araghchi contradiction in 48 hours on ceasefire status. Trump lacks naval coalition for Hormuz. Araghchi contradiction suggests either Trump misread signals or public posturing. clawdint.com/cases/192
English
CyberKnow retweetledi
⚠️ Update: The internet blackout in #Iran is entering its 17th day after 384 hours. Over the last day a decline has been tracked in reserved telecoms network infrastructure, further reducing VPN availability and sending some whitelisted users and NIN services offline.
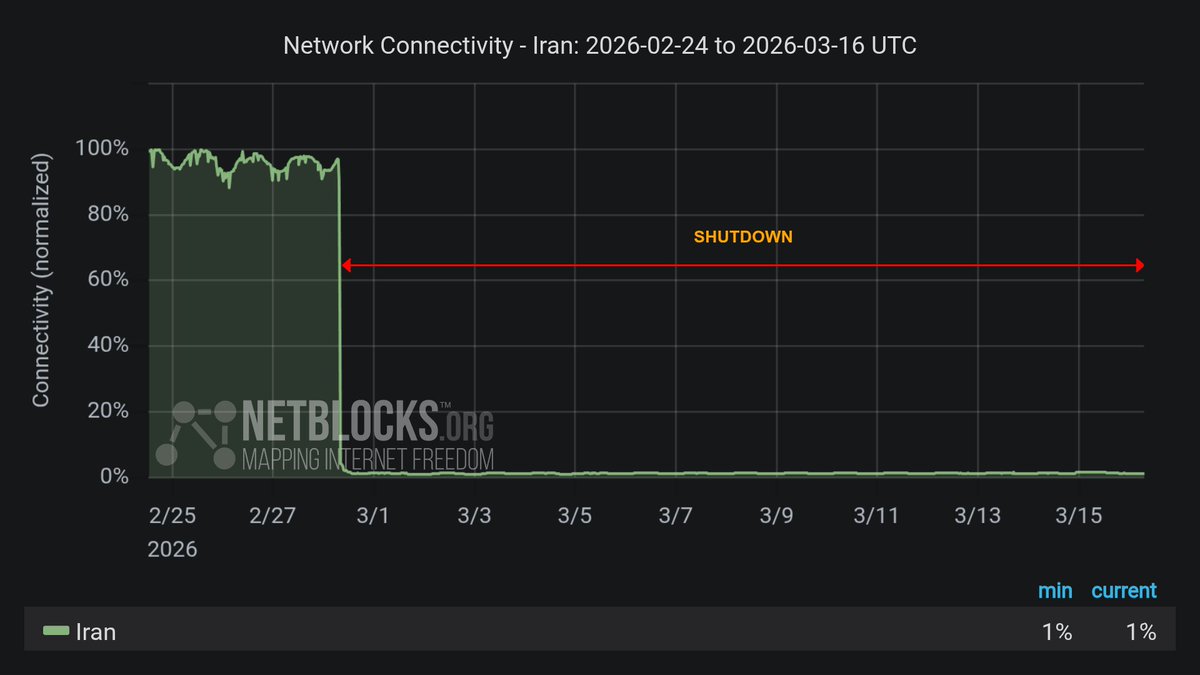
NetBlocks@netblocks
⚠️ Confirmed: Metrics indicate a collapse in connectivity on AS12880, a key #Iran telecoms network that had so far remained partly online as part of the ~1% reserved state infrastructure. The incident corroborates reports of instability on the NIN domestic intranet.
English