Sabitlenmiş Tweet

@cantinasecurity why add a comment section if the Judge won't even reply or consider anything you say?

English
0xD4N0
236 posts

I recently turned 33, and every year I want to go back to 21-year-old Patrick with a list of lessons. If you're in your 20s, these are for you. Most lessons only land after an ass-whooping. And even then, you usually miss them the first time.
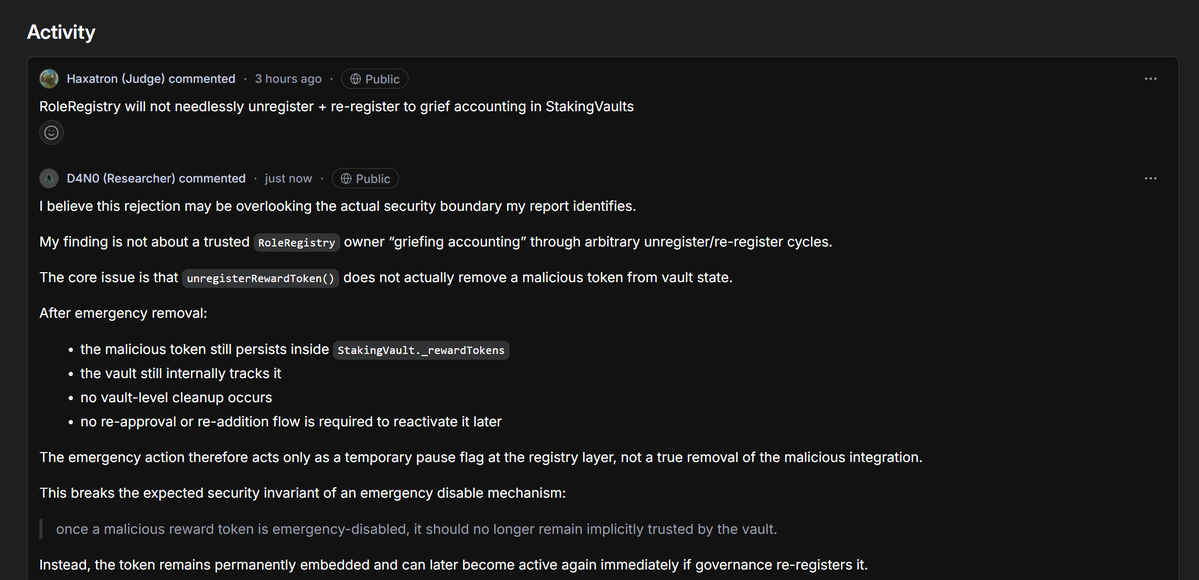
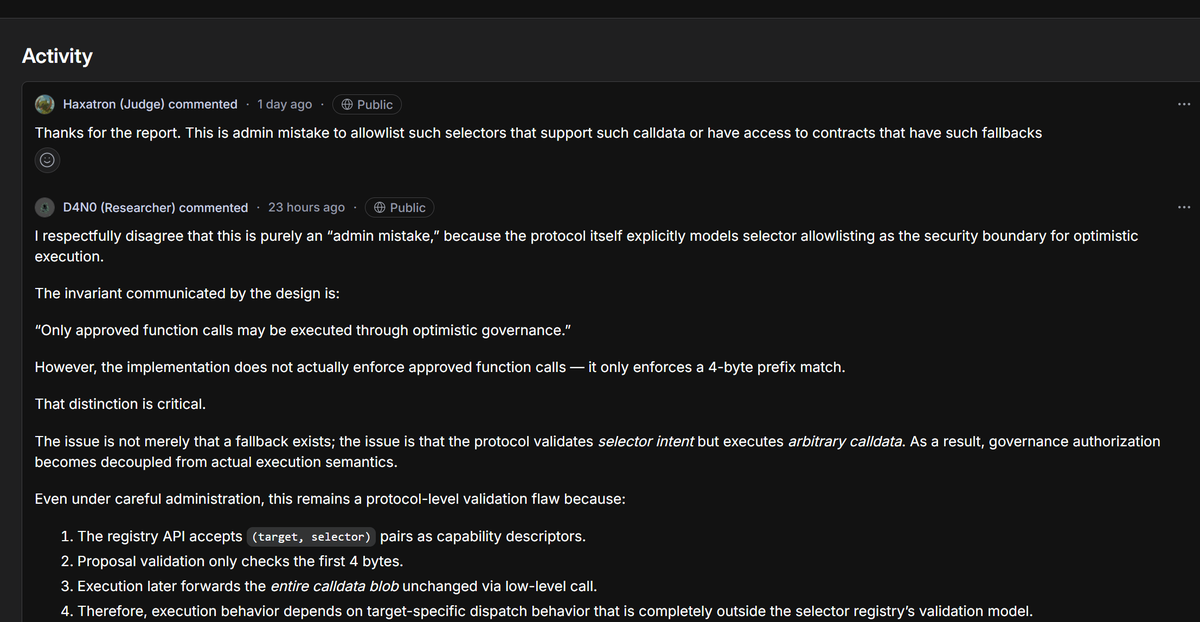
I am not here to trash $Cantina outright, but this is the truth from multiple whitehats who’ve hunted there. Cantina positions itself as the premium Web3 bug bounty platform AI spam filtering + expert triage + Spearbit backing promising high-signal reports and fewer headaches than the big general platforms. They host massive programs $Coinbase, dYdX $1M scopes, $Aave CTFs, etc. and pay out real money. That is why top researchers still show up. But the complaints are piling up, and they’re not just “tough triage.” They’re systemic issues that leave whitehats burned, valid critical bugs rejected with gaslighting, and protocols getting away with it. Here is what researchers are actually experiencing > Triage that defaults to the client’s perspective. Cantina’s own docs admit they “default to client’s perspective” in disputes. Mediation often downgrades critical findings e.g., monetary loss capped at Low severity even when the auditor showed clear fund loss risk). One firm documented ~104 judging errors in a single contest wrong dupes, invalid rejections, severity drops and still waited 8 months for resolution while token prices tanked and payouts shrank in value. > Rejections that look like gaslighting. The now-public CVE-2026-4931 case is the clearest example. Researcher submitted a critical integer truncation bug in Marginal V1 with mainnet fork PoC, EVM traces, video walkthrough, and exact SafeCast fix. Protocol emergency paused four days later, stealth patched the exact issue, then Cantina rejected it claiming impossible uses Gnosis Safe” and misidentified bytecode. Even after CERT/CC assigned the CVE (CVSS 9.1 Critical), radio silence from Cantina/Spearbit. Researchers call it straight-up denial to avoid payout. > Insane delays and ghosting on resolved findings. 8 month contest resolutions are not rare. Payouts drag even after mediation. One top auditor outperformed the leaderboard 3-7x in solo findings… then vowed never to return because the postcontest experience was “terrible.” > Reputation/signal penalties that punish edge cases. Like other platforms, rejections tank your signal score. But Cantina’s strict filtering (meant to kill spam) combined with sponsor-favoring verdicts makes it feel like the house always wins on close calls. > Fellowship exclusivity clauses that lock researchers in. Cantina Fellows can’t submit to other platforms or notify projects directly even if millions are at risk. All intel funnels through Cantina first. Bow down or leave energy. > Client scam allowance. Platforms like Immunefi will boot a sponsor after repeated non payment. Cantina reportedly allows sponsors 5 bounty scams per year before any real consequences. That’s not researcher first. Compare that to platforms with clearer SLAs (HackenProof-style fast triage + payment timelines) or stricter sponsor accountability. Cantina’s “high-signal” model is great for protocols they get fewer noisy reports but it’s extracting value from the whitehat side. Simple fixes that would change everything: Enforce real mediation: one or two sponsor violations = removal. No more 5-scam allowance. •Independent appeal board (not defaulting to client view). •Require protocols to escrow full bounty pools upfront (like some competitions already do). •Publish transparent triage reasoning and let researchers challenge false bytecode/“impossible” claims with evidence. •Drop the aggressive exclusivity clauses and give Fellows actual freedom. •Public SLAs: triage in X days, mediation in Y days, payment in Z days after fix. No more 8-month black holes. Cantina pays some of the biggest Web3 bounties and has real expertise behind it. That is exactly why the space needs them to fix this. Right now the system is pushing good whitehats toward frustration, private disclosures, or worse and that hurts everyone who cares about on chain security.

i thought auditors were supposed to be safe from AI 🤔


It's not the end, it's still living on in the LLM data training sets. That's why you see so many zero-address check suggestions and inflated severities. (My feeling is that it has improved with recent models though?) The very early 2021 days with @0xRajeev @gpersoon @sockdrawermoney were peak fun. What ruined contests from an SR's POV was: Fewer real bugs because devs and tooling got a lot better, once foundry came along devs started actually testing their code with high coverage. This led to more (arguably) out-of-scope bug submissions which made the highest-impact move arguing about your own & others' issues. The difference between a high and a medium was not well defined in practice & there were some incompetent judges (sorry). Pool sizes also never kept up with the increase in participants. In the end, the audit contest payout structure changed so much that many were just pre-deployment bug bounties (different pool size unlocks for H/M). Ironically, now would be a great time for contests again as everyone is boasting about their AI being the best. Would love to see more real results instead of vagueposting.
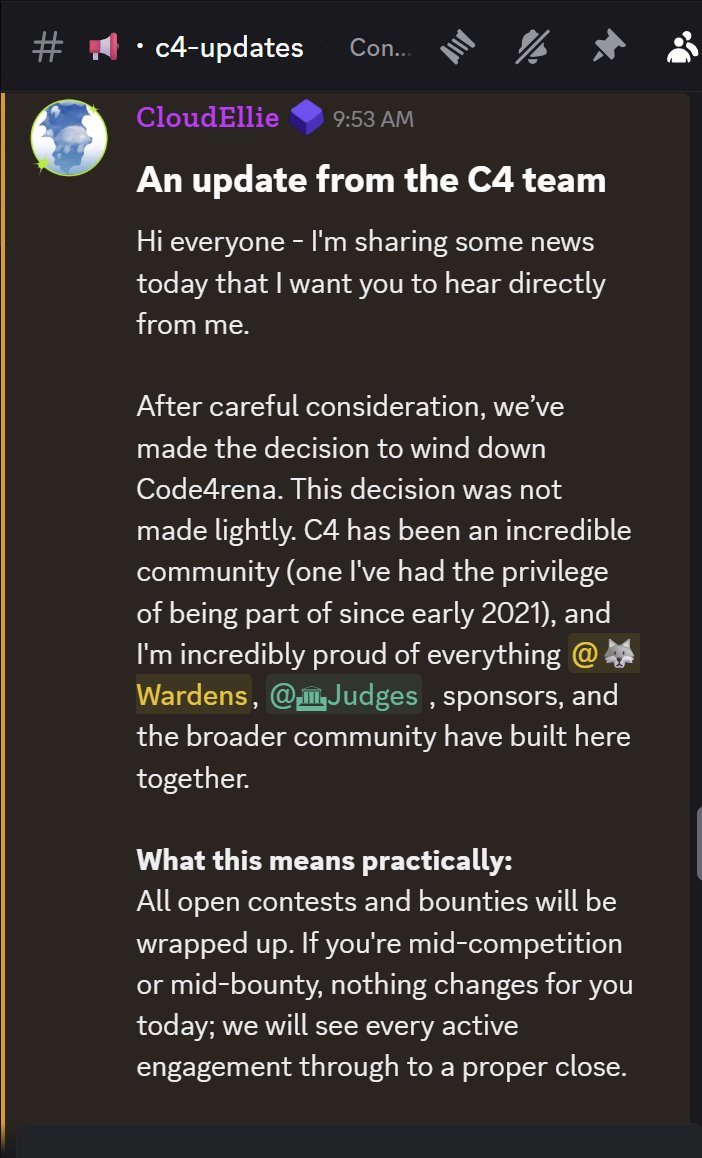
An important update from the C4 team. 🧵

An important update from the C4 team. 🧵