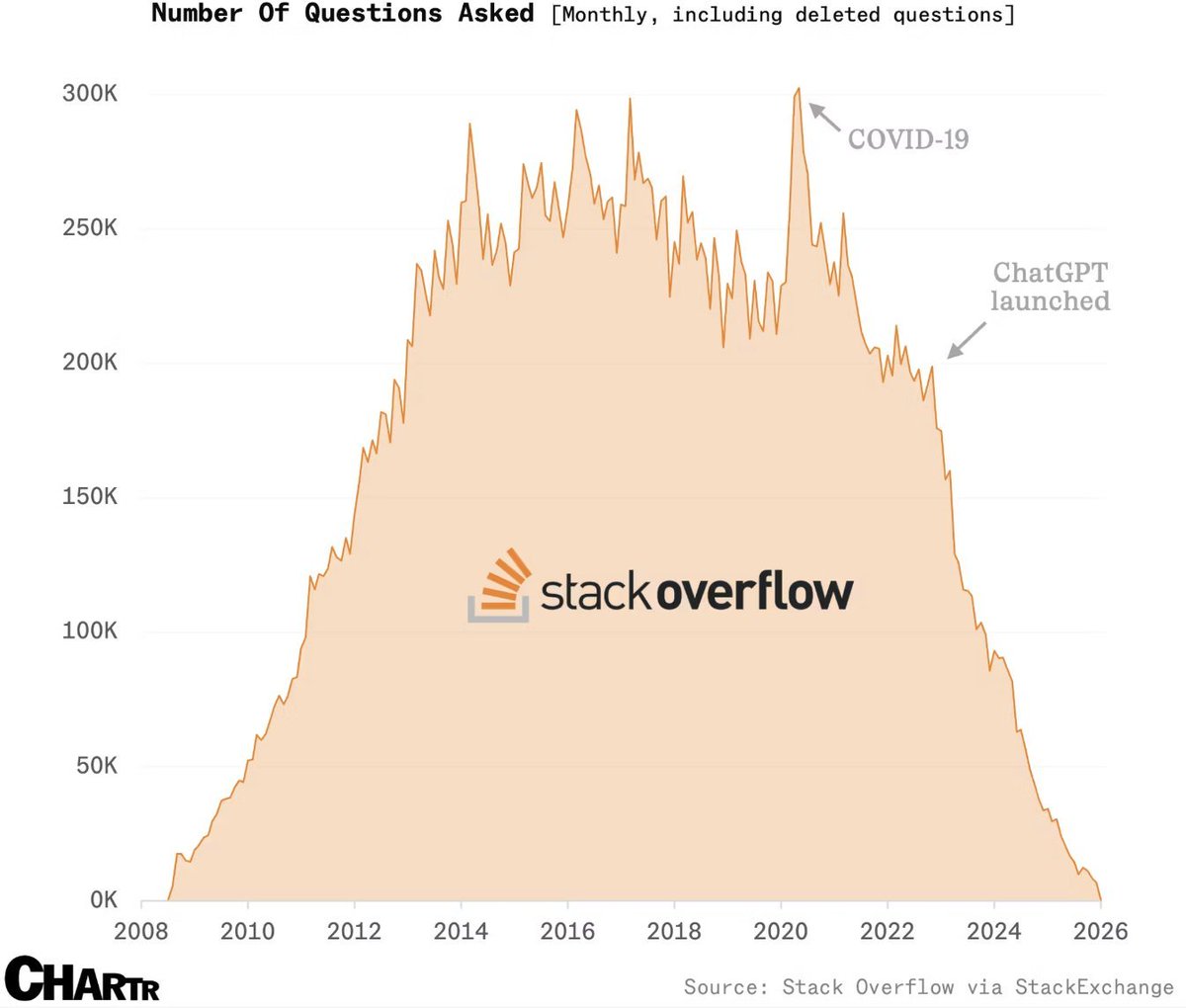
@lochan_twt reminds me of GetRight , WinAMP , Napster
English
Daniel says it won’t scale
2.3K posts

@Daniel0x6019
Cloud guy. Senior developer. Expert friendly.



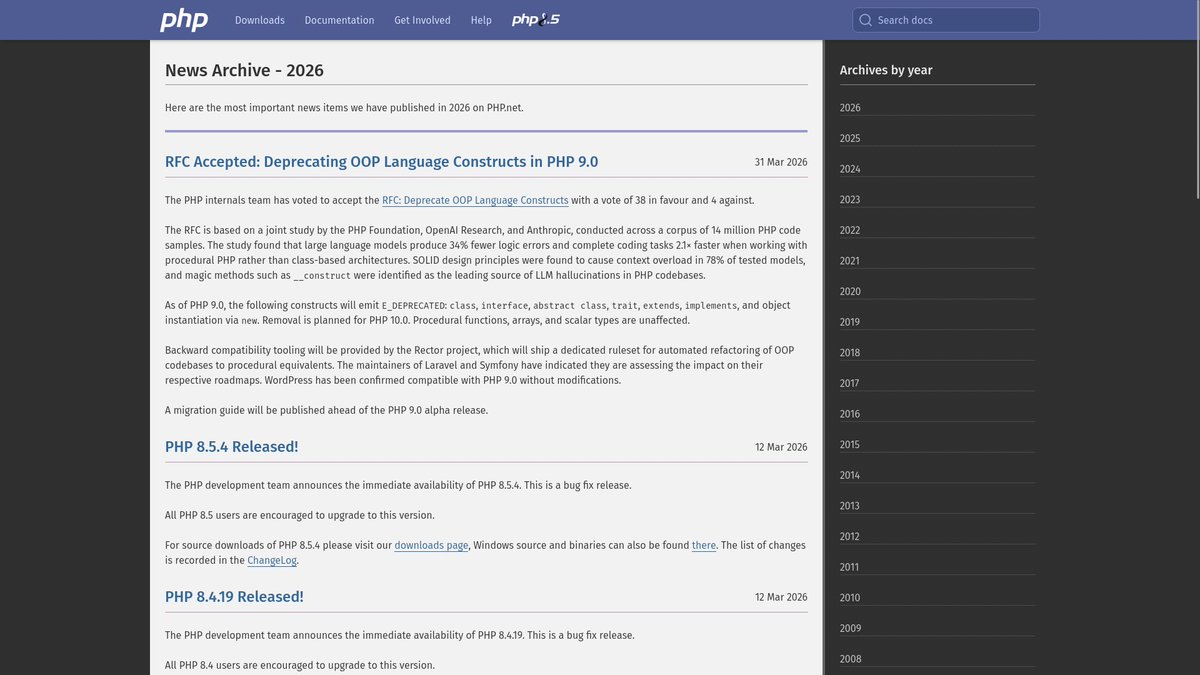
The creators of SWE-Bench just dropped a really simple new benchmark every LLM gets 0% on. ProgramBench asks: can models recreate real executable programs (ffmpeg, SQLite, ripgrep) from scratch with no internet? We are far from saturated on model quality.






How Anthropic’s product team moves faster than anyone else I sat down with @_catwu, Head of Product for Claude Code at @AnthropicAI, to get a peek into their unprecedented shipping pace, how AI is changing the PM role, and how to be the right amount of AGI-pilled. We discuss: 🔸 How Anthropic’s shipping cadence went from months to weeks to days 🔸 The emerging skills PMs need to develop right now 🔸 Why you should build products that don't work yet—then wait for the model to catch up 🔸 Why a 95% automation isn't really an automation 🔸 Cat’s most underrated AI skill (introspection) 🔸 What Cat actually looks for when hiring PMs now (hint: it's not traditional PM skills) Listen now 👇 youtu.be/PplmzlgE0kg





AWS announces general availability of AWS Interconnect - multicloud AWS announces general availability (GA) of AWS Interconnect - multicloud, providing simple, resilient, high-spe... aws.amazon.com/about-aws/what…

Manager: We lost our best engineer today. CEO: The one leading payments? Manager: Yes. CEO: Did another company offer more money? Manager: No. CEO: Then why leave? Manager: He said he was tired of fixing the same production issues every week. CEO: That’s part of the job. Manager: He didn’t mind fixing issues. He minded that nobody wanted to fix the root cause. CEO: We prioritized speed. Manager: He wanted quality. CEO: So he left over that? Manager: He left because he felt like a firefighter, not an engineer. Good engineers don’t just want to solve problems. They want to eliminate them.