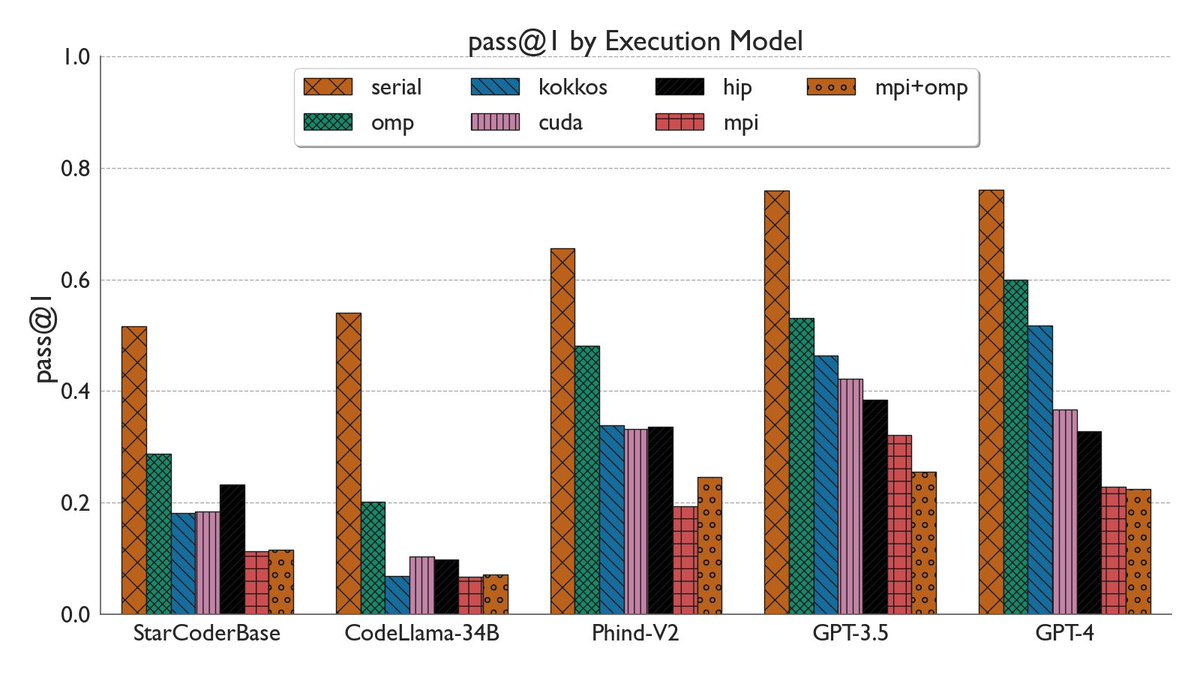
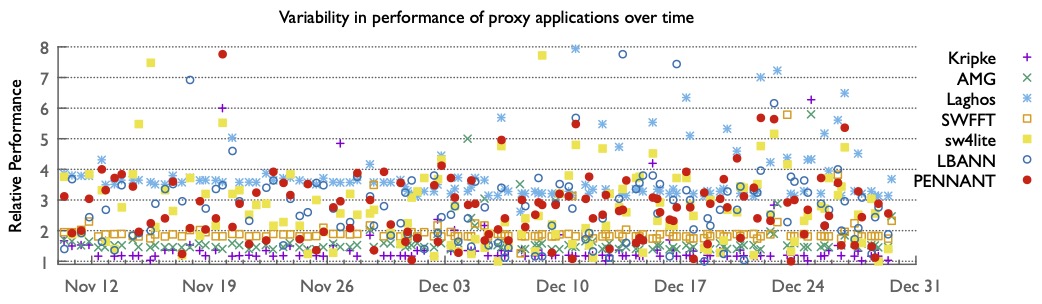
Daniel Nichols retweetledi

LongCoT is adding two new leaderboards! Due to the interest in agents (particularly RLMs), we’re adding a “Restricted Harness” and an “Open Harness” leaderboard.
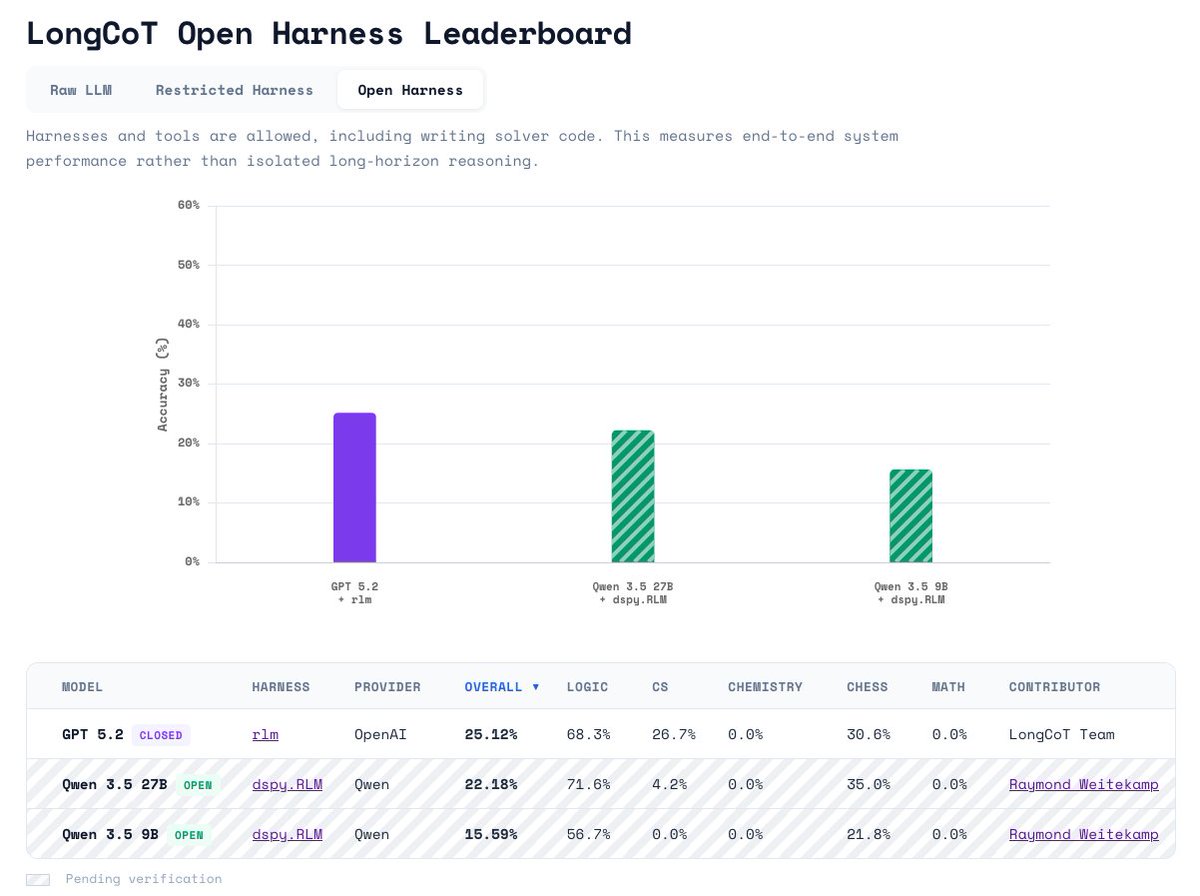
GPT 5.2 RLM from our paper is SOTA on “Open Harness” at 25.12%. We expect tool-use SOTA to exceed this very soon!
On “Open Harness”, we allow all tool-use and code execution. On “Restricted Harness”, models may manage context, call subagents, etc, but may not write specific solver code (e.g. writing a BlocksWorld or Sudoku solver). We’re particularly excited about this leaderboard, as it allows agents to do their own context management, while sticking to LongCoT’s goal of testing models’ intrinsic reasoning capabilities.
Sumeet Motwani@sumeetrm
We’re releasing LongCoT, an incredibly hard benchmark to measure long-horizon reasoning capabilities over tens to hundreds of thousands of tokens. LongCoT consists of 2.5K questions across chemistry, math, chess, logic, and computer science. Frontier models score less than 10%🧵
English