Datagran retweetledi

Ok, I am shaking a bit. I think this feels different.
For the past few weeks I’ve been experimenting combining three ideas:
1. @bchesky saying chat interfaces are not good enough
2. @karpathy’s Wiki LLM
3. @trq212 saying HTML is the new .md
The result is starting to feel like a new interface layer for agentic systems.
Not chat.
A workspace that builds itself as you use it in pure HTML.
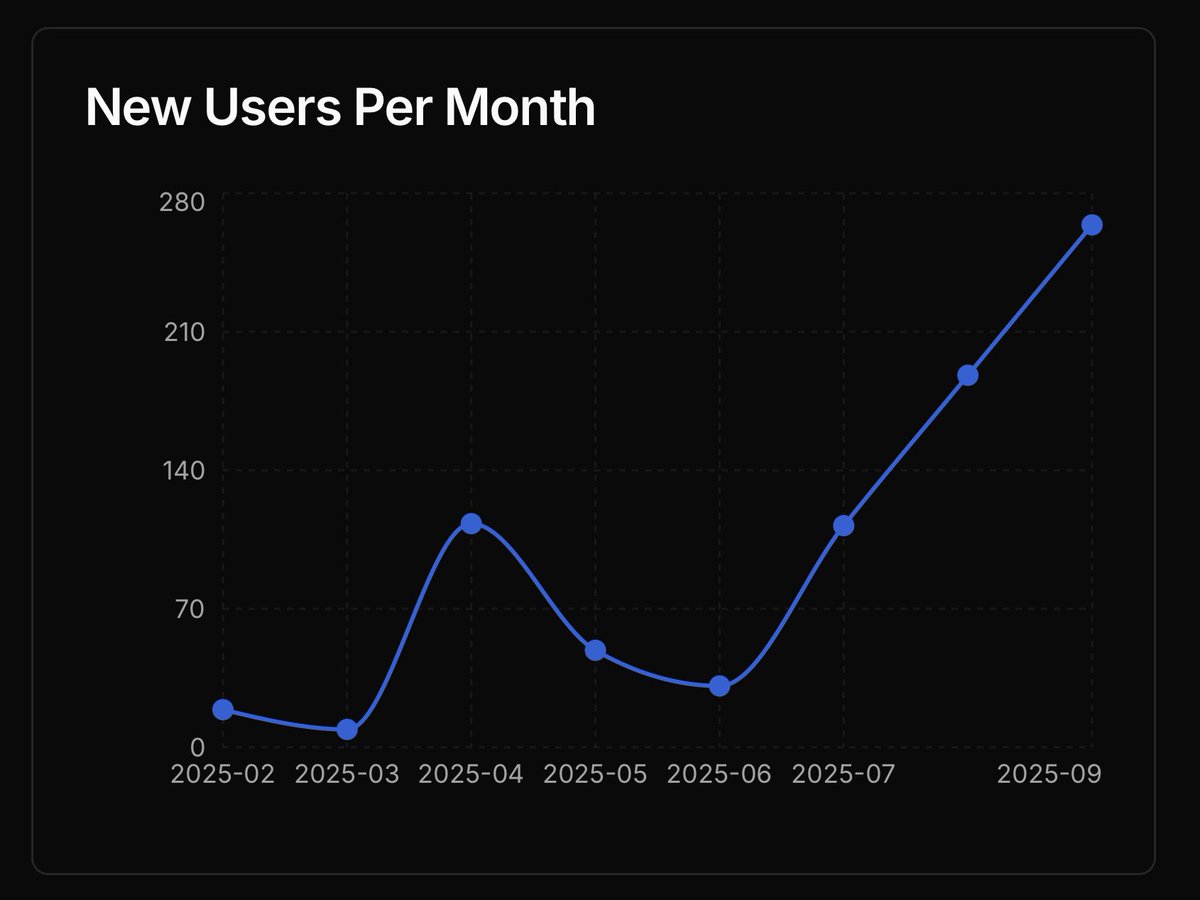
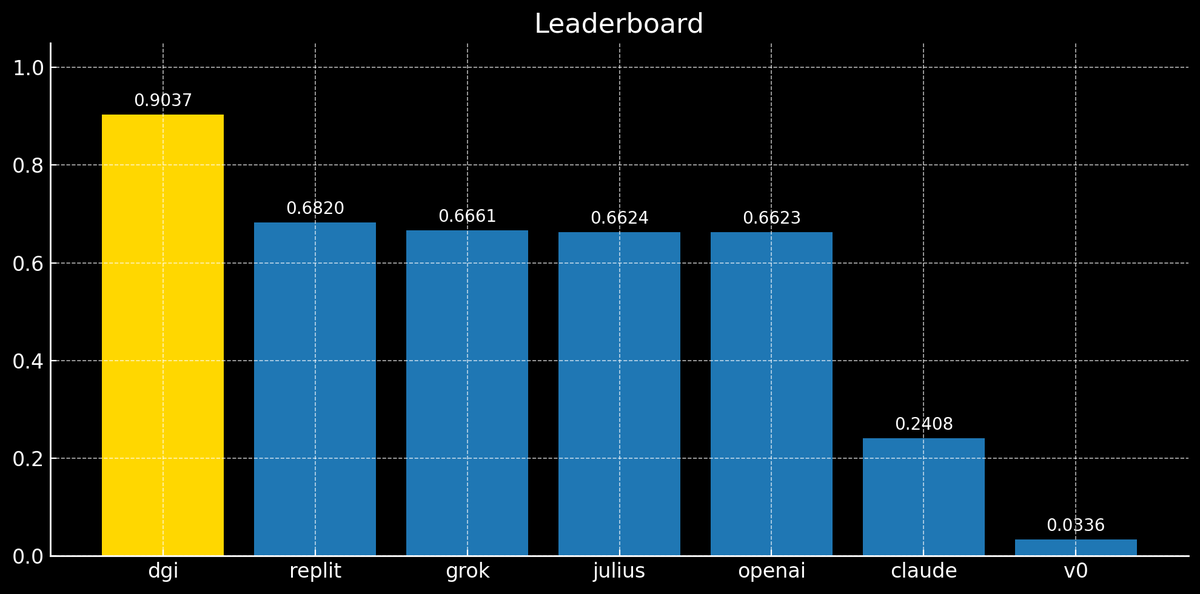
It learns from you, adapts to the task, and visualizes what you need in real time.
I built this as another interaction layer in Groovy apart from WhatsApp, Telegram and the chat interface.
Check it out and see how it evolves. Feels different. Magical.
I want people to try it so I am giving away gogroovy.ai for free for the first 50 users. Sign up and dm me your email.
Also, this version will be up in the open source repo in 30 days github.com/Charlesmendez/…
English