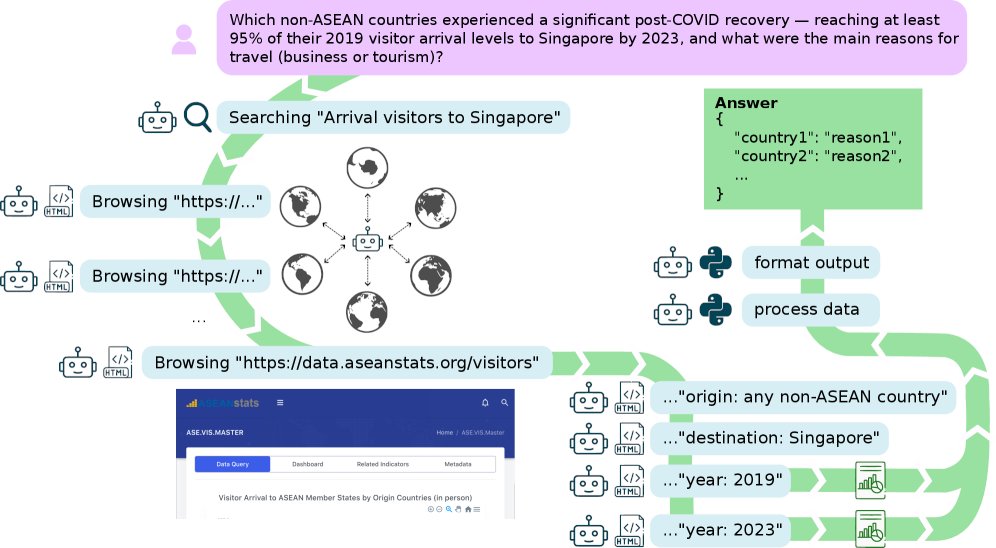
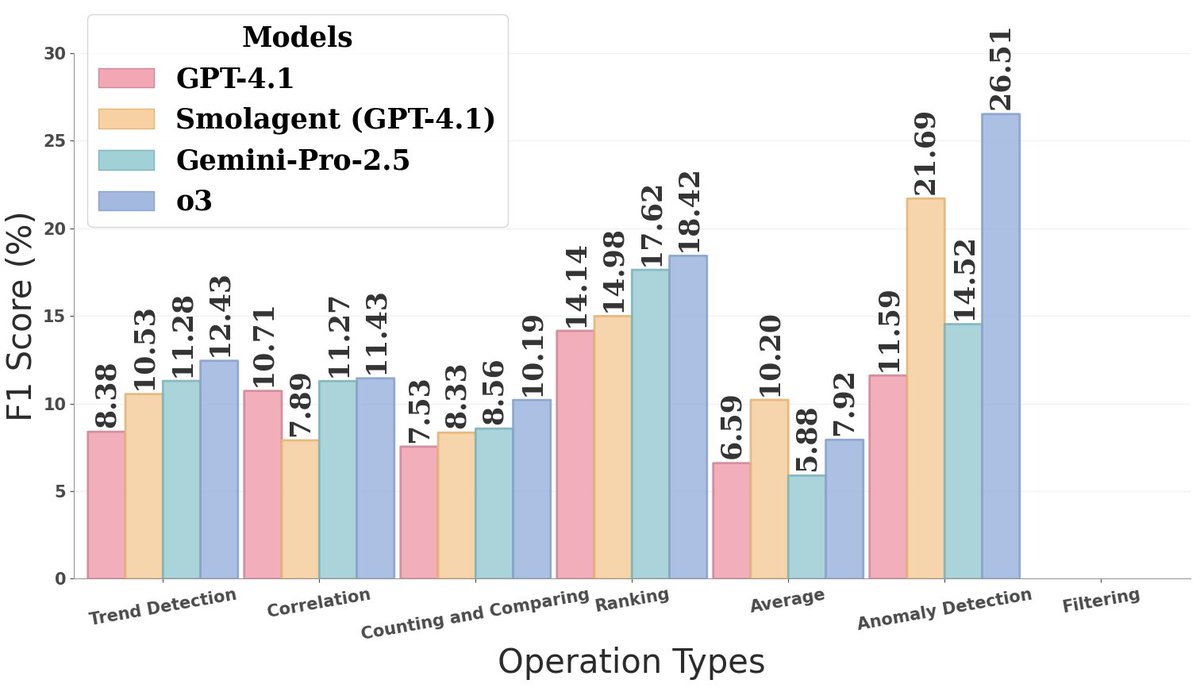
Sabitlenmiş Tweet

Can AI agents truly synthesize information across multiple sources?
🏆 Best system: 8.97 F1
❌ Most systems: 0% exact match
🚀 Introducing DEEPSYNTH, our new benchmark accepted at #ICLR2026!🇧🇷
📄 Paper: arxiv.org/abs/2602.21143
🤗 Data: huggingface.co/datasets/DeepS…
GIF
English