
…and find that OoD samples have higher ID estimates
arxiv.org/abs/2511.11490 (work led by @QuerFont , who will also be at NeurIPS! Email him if you want to have a chat.)
English
Devina Mohan
76 posts

@DevinaMohan_
Astro+ML PhD student @jodrellbank @OfficialUoM. she/her





Excited to share our new paper on benchmarking Bayesian deep learning for radio galaxy classification! I’ll be at #UAI2024 and the #AABI2024 Workshop colocated with @icmlconf in July to present this work

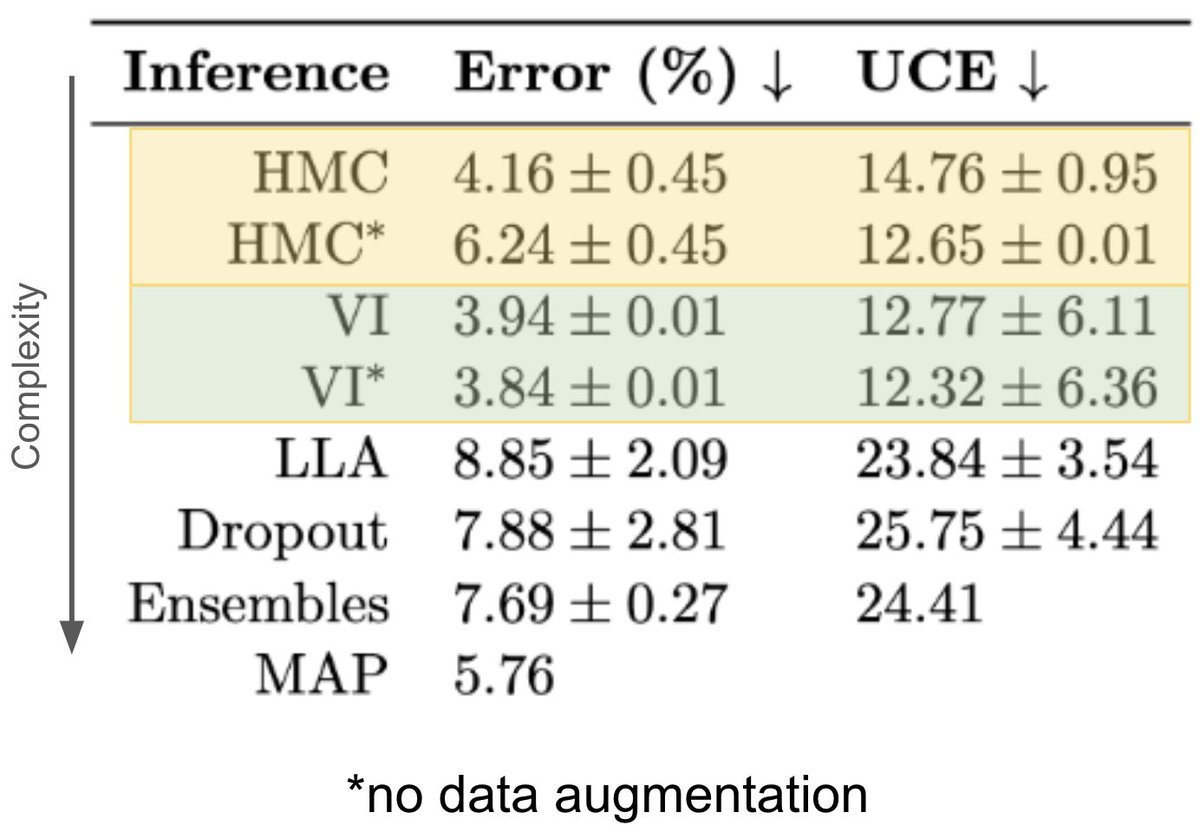
Our #UAI2024 paper, led by @DevinaMohan_ , is on arXiv! How different Bayesian approximations in deep-learning perform for galaxy classification cf. an HMC baseline. [model performance, uncertainty calibration, dataset shift detection] arxiv.org/abs/2405.18351 @UncertaintyInAI




I'm looking forward to the Machine Learning and the Physical Sciences workshop today (Friday). We are in Hall B2, stop by #ML4PS2023 #NeurIPS2023 @ML4PhyS ml4physicalsciences.github.io/2023/
