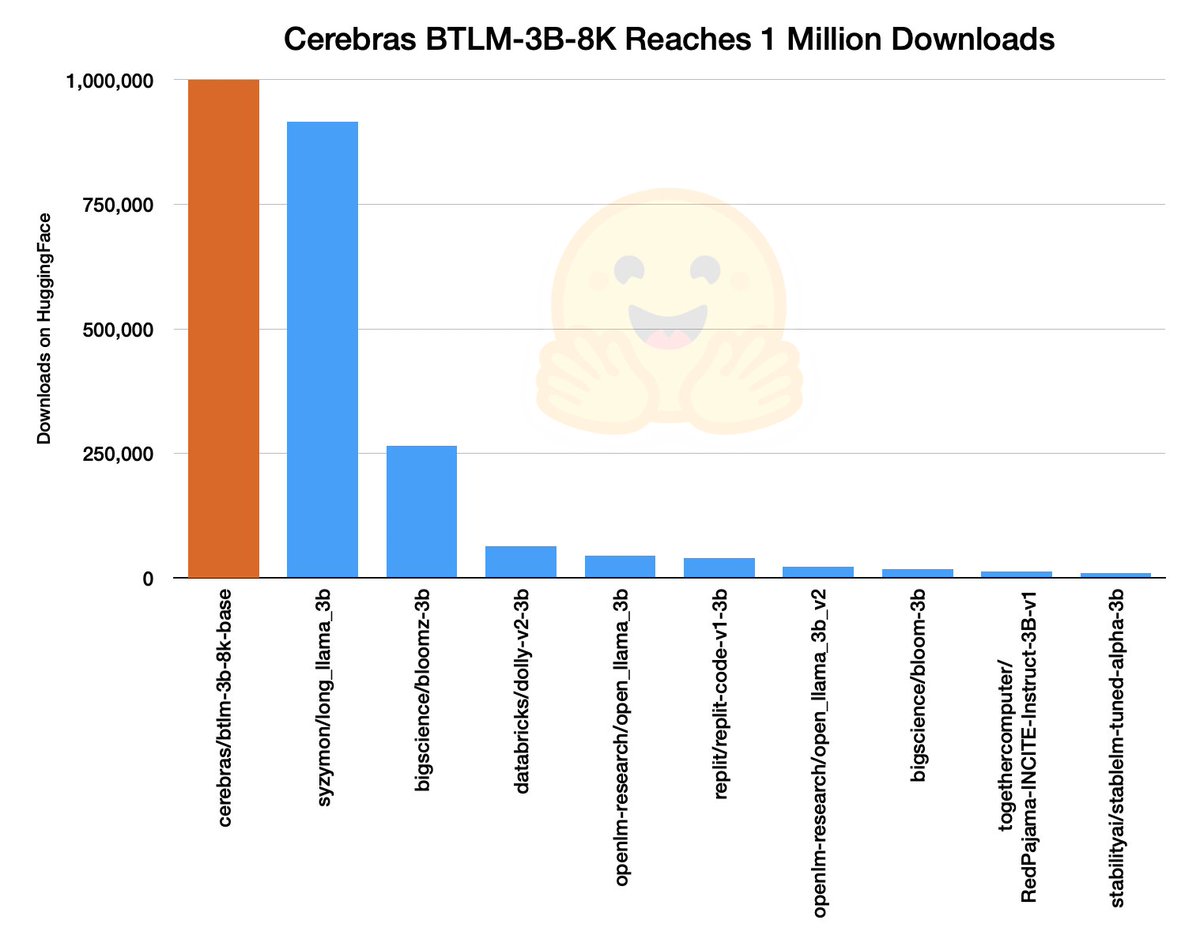
Nolan Dey retweetledi

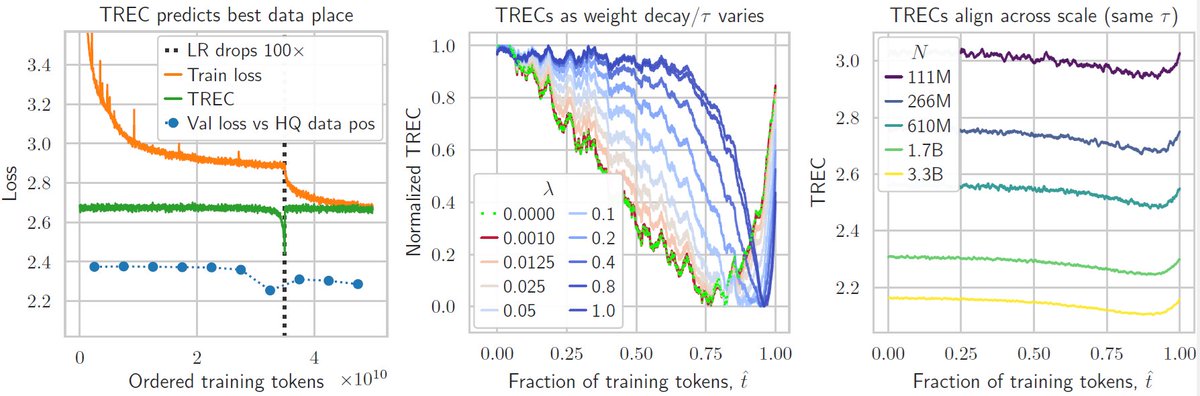
Another new preprint from @cerebras 🚨📄- this time on training *re-evaluation* curves (TRECs) for data curriculums in LLMs.
Everyone sticks high-quality data at the end of training… we show the sweet spot is often earlier — and we can predict it.
arxiv.org/abs/2509.25380
English