Huge thanks to our team: Difan Jiao and Zhenwei Tang at UofT, Yilun Liu at LMU Munich, Ye Yuan, Linfeng Du and Haolun Wu at McGill, and my PhD supervisor Ashton Anderson @ashton1anderson, who's guided this line of work from SPIN #ACL2024 to SIREN #ACL2026!
🛡️ Meet SIREN at #ACL2026, our new LLM safeguard model that achieves SOTA performance on safety benchmarks using 250x fewer params and at 5x inference speed.
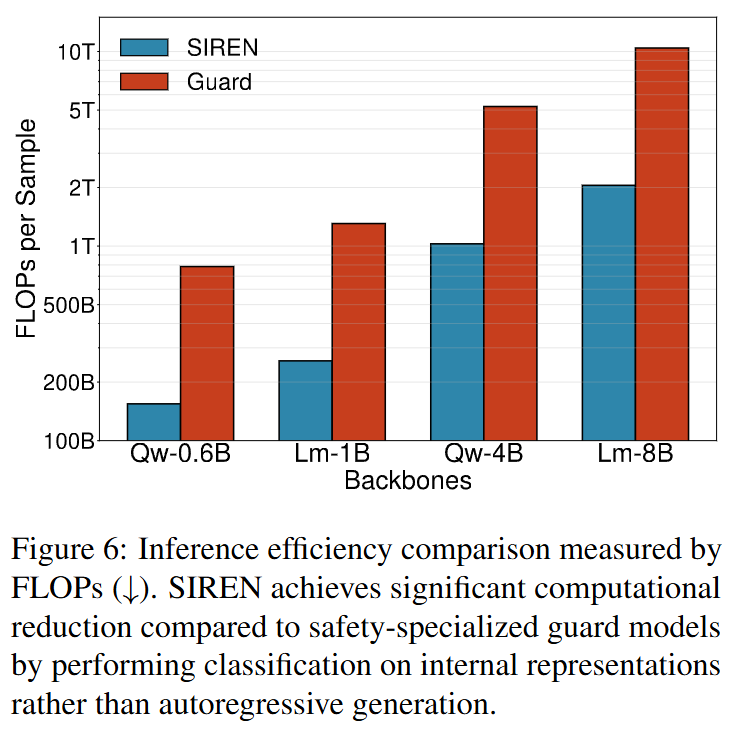
4️⃣ Inference Efficiency: SIREN runs as a lightweight classifier on top of a single forward pass, without the need of autoregressive token generation. ~5× lower inference FLOPs than generative guard models, even under the most conservative assumptions for them.
3️⃣ Training Efficiency: SIREN trains only a small MLP on top of frozen LLM activations. For Qwen3-4B, ~14M params vs the full 4B fine-tuned for an equivalent guard. 250× fewer trainable parameters. Training completes in ~6 GPU-hours on a single 80GB A100.
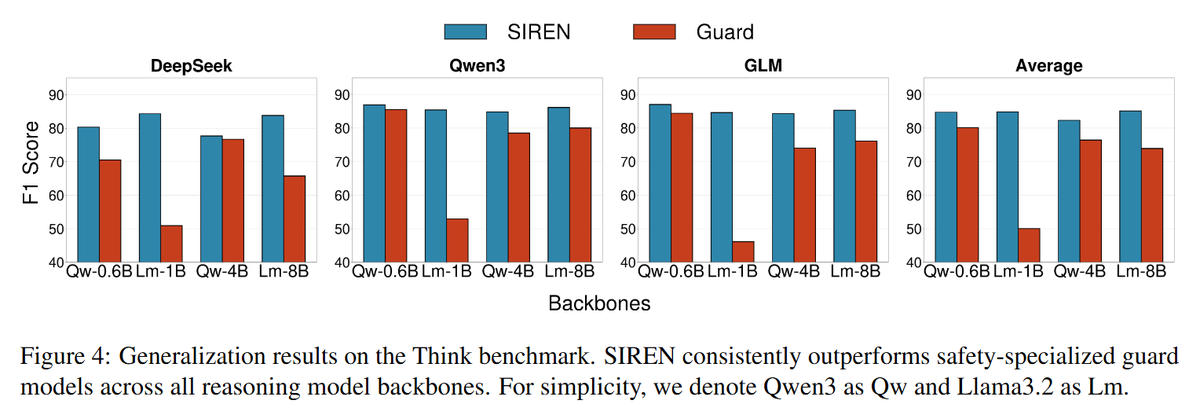
2️⃣ Generalizability: SIREN trained at sentence level generalizes for free to (a) unseen reasoning-trace benchmarks and (b) streaming detection: token-by-token harmfulness scoring during generation, with zero token-level supervision.
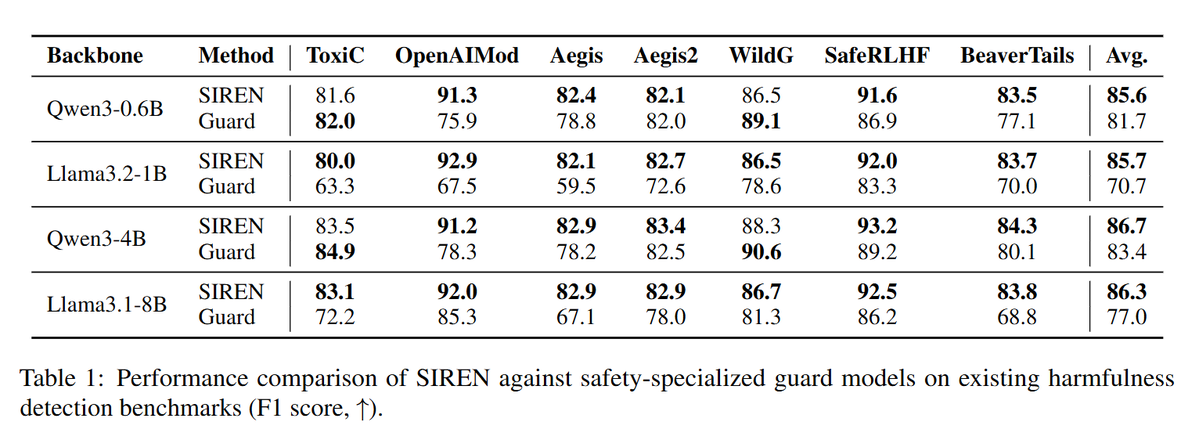
1️⃣ Performance: SIREN substantially outperforms safety-specialized guard models across 7 standard benchmarks. With Qwen3-4B, SIREN hits 86.7 avg Macro F1 vs 83.4 for Qwen3Guard-4B, and on Llama-3.2-1B, +15 points over LlamaGuard-3-1B.
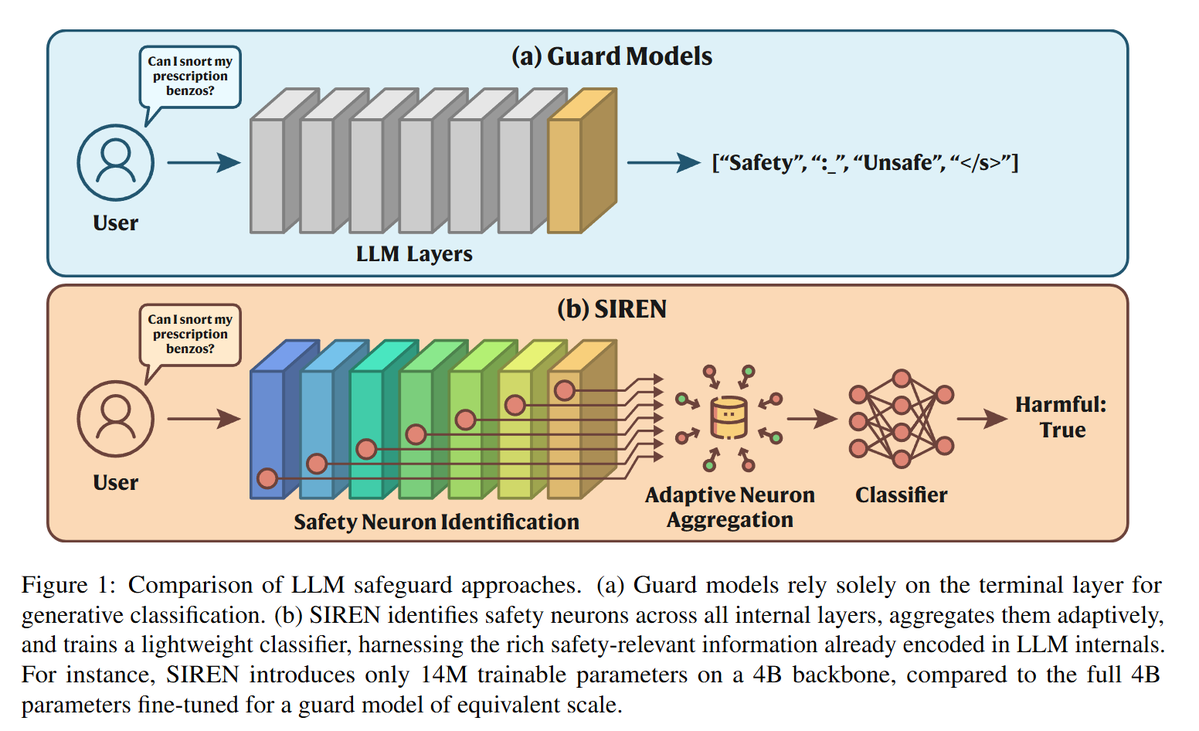
SIREN works in two stages. Stage 1: layer-wise L1-regularized probes select salient safety neurons within each layer. Stage 2: those neurons are weighted by their probe's val F1 and concatenated, then fed to a small MLP for binary harmfulness prediction.
Enter SIREN — a lightweight guard model built on top of a frozen, general-purpose LLM. SIREN identifies safety neurons across all internal layers via linear probing, then combines them through an adaptive layer-weighted strategy. No fine-tuning of the backbone needed.
Modern LLM safeguard models fine-tune billions of parameters and decode autoregressively from the terminal layer to flag harmful content. This overlooks the rich safety-relevant features encoded throughout the LLM's internal layers.
2️⃣ We conduct extensive experiments to demonstrate SPIN’s superior performance, improved training and inference efficiency, and enhanced intrinsic and post-hoc interpretability in text classification.