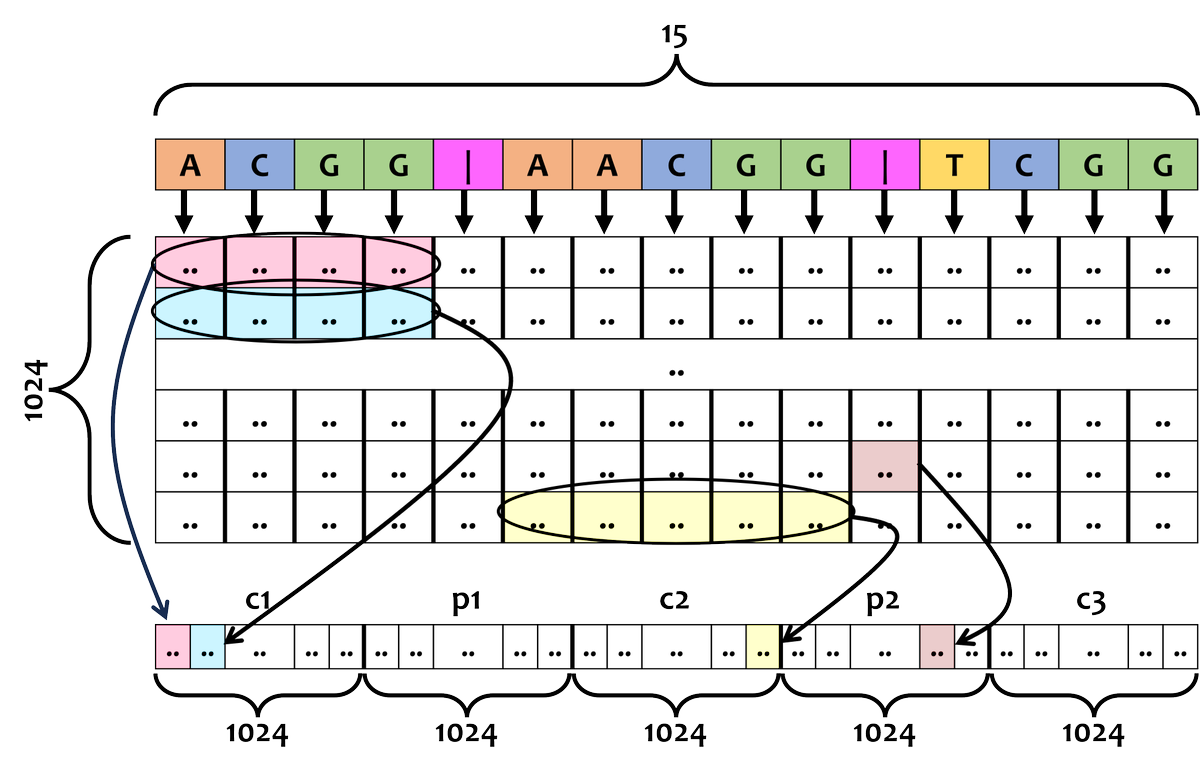
@razoralign Also described in:
"Multiple sequence alignment as a sequence-to-sequence learning problem" (ICLR, 2023)
openreview.net/forum?id=8efJY…
English
Edo Dotan
18 posts



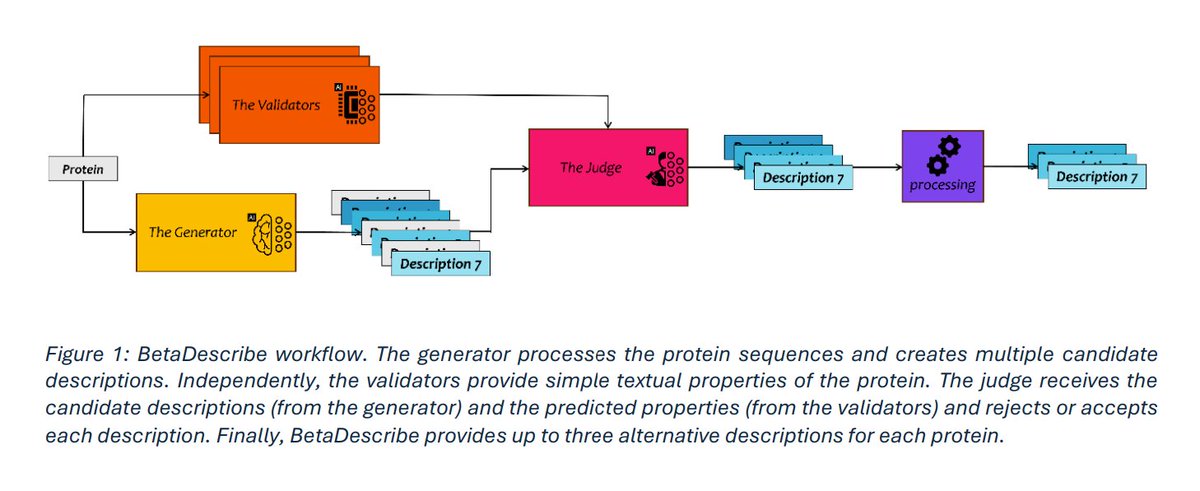

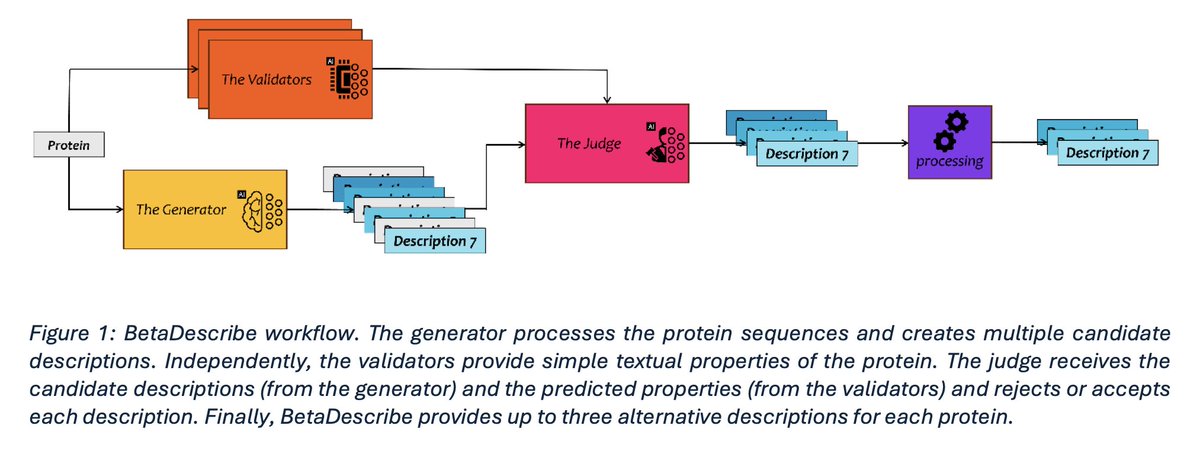
Protein2Text: Providing Rich Descriptions for Protein Sequences 1. Introducing Protein2Text, a novel model that bridges protein sequences and natural language, generating rich textual descriptions of protein properties, functions, and roles. 2. The system leverages BetaDescribe, a model derived from LLAMA2, trained on over 120 billion biological and English tokens, enabling seamless integration of biological insights into generative language capabilities. 3. Protein2Text excels at describing proteins with low sequence similarity to training data, outperforming traditional methods like BlastP, especially when homologous sequences are unavailable. 4. The model comprises a generator for creating descriptions, validators for property prediction, and a judge to assess accuracy, offering robust multi-perspective outputs. 5. Key innovations include its ability to identify functionally important regions via in-silico mutagenesis, revealing biological meaningful domains without experimental mutagenesis. 6. Compared to public large language models like GPT4, BetaDescribe demonstrates superior performance in protein-specific contexts, with higher accuracy and contextual relevance. 7. This tool advances functional protein annotation, with implications for medicine, agriculture, and protein engineering, and suggests potential for reverse application in protein design. @boknilev 💻Code: github.com/technion-cs-nl… 📜Paper: biorxiv.org/content/10.110… #ProteinBiology #GenerativeAI #Bioinformatics #ProteinFunction #NLP