ModelScope@ModelScope2022
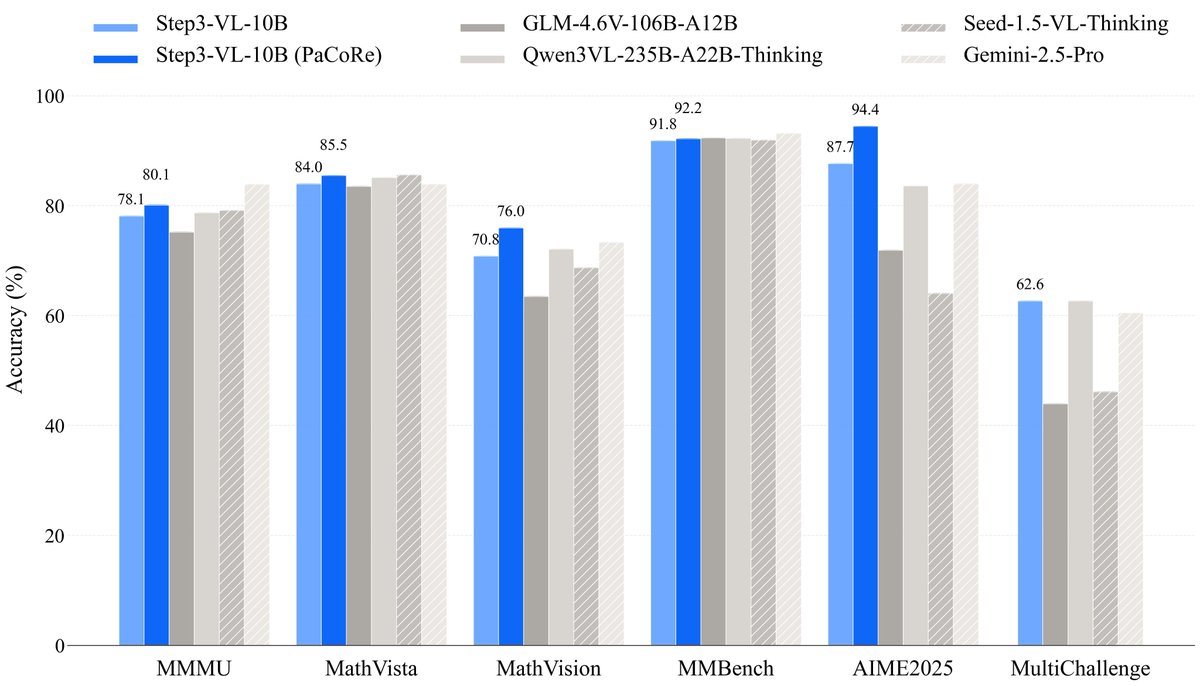
🚀 Meet STEP3-VL-10B—it delivers SOTA-level visual perception, complex reasoning, and human-aligned intelligence—redefining efficiency in open multimodal AI.
✅ Beats or matches models 10–20× larger (like GLM-4.6V, Qwen3-VL, even Gemini 2.5 Pro)
✅ Achieves SOTA on MMMU, MathVision, OCRBench, ScreenSpot, and more
✅ Trained on 1.2T tokens + 1,400+ RL rounds (RLHF + RLVR)
✅ Supports PaCoRe: parallel collaborative reasoning (128K context!)
Despite its compact size, it leads the <10B class in:
• STEM reasoning (94.43% on AIME 2025 w/ PaCoRe!)
• Visual perception (92.05 on MMBench)
• GUI understanding & OCR
• Spatial reasoning for embodied AI
Built with:
• PE-lang visual encoder (1.8B)
• Qwen3-8B decoder
• Multi-crop high-res input (728×728 global + locals)
📥 Base & Chat versions on ModelScope:
Base: modelscope.cn/models/stepfun…
Chat: modelscope.cn/models/stepfun…