🤔 What does it actually take for AI agents to do real research?
In Step-DeepResearch, the authors argue that many current “deep research” AI systems still behave like advanced search tools — good at retrieving information, but weak at the sustained reasoning, verification, and synthesis that real research demands.
Instead of framing research as a single prompt or a loosely coordinated multi-agent workflow, this paper treats it as a sequential decision-making process. Research is broken down into atomic capabilities such as planning, information gathering, reflection, evidence verification, and structured writing — all learned within a single agent loop.
To train this behavior, the authors introduce a data synthesis strategy that explicitly teaches the model how to research, not just what to retrieve. The training pipeline progresses from mid-training to supervised fine-tuning and reinforcement learning, gradually shifting the model’s objective from next-token prediction to deciding the next research action.
The paper also introduces ADR-Bench, a new evaluation benchmark designed to reflect real research needs rather than narrow multi-hop QA. Notably, the system achieves strong performance using a 32B model, rivaling closed-source deep research systems — but with significantly lower inference cost.
The broader takeaway is subtle but powerful: building capable research agents may depend less on scaling or orchestration, and more on how we train models to think, plan, and verify over time.
#AIResearch#AgenticAI#LLMs#AITraining#ReinforcementLearning#DeepResearch#AIBenchmarks
🚨 Memory is no longer a “nice-to-have” for AI agents—it’s the backbone of autonomy.
This new survey, Memory in the Age of AI Agents, makes a compelling case that if we want agents to reason long-term, adapt continuously, and interact meaningfully with complex environments, memory must be treated as a first-class design primitive
What stands out is how the paper cuts through today’s fragmented landscape. Instead of loosely throwing around terms like short-term, long-term, or episodic memory, it introduces a much clearer and more practical lens: Forms, Functions, and Dynamics.
• Forms: token-level, parametric, and latent memory
• Functions: factual, experiential, and working memory
• Dynamics: how memory is formed, evolves, and gets retrieved over time
This framing helps explain why many agent systems struggle today—not because models can’t reason, but because memory is often bolted on rather than thoughtfully designed. The survey also does a great job distinguishing agent memory from adjacent ideas like RAG, LLM memory, and context engineering, which are frequently conflated in practice
Even more valuable is the forward-looking perspective: automation-oriented memory design, RL-integrated memory systems, multimodal and shared memory for multi-agent setups, and the growing importance of trust and reliability in long-lived agents.
If you’re building or researching agentic systems, this paper is a reminder that scaling intelligence isn’t just about bigger models—it’s about better memory.
#AgenticAI#AIMemory#LLMAgents#AIResearch#AutonomousAgents#RAG#ContextEngineering#ReinforcementLearning#MultimodalAI
🚨 Google DeepMind released a paper that quietly reframes how we think about scaling AI agents.
Instead of asking “What if we give agents more tools?”, this work asks a sharper question: “Do agents actually know how to spend their tools wisely?”
The paper shows that simply increasing tool-call budgets—searches, browsing steps, API calls—doesn’t automatically improve performance. Most agents hit a ceiling early, not because they lack resources, but because they lack budget awareness.
The core insight is elegant: when agents can see how much budget they’ve used and how much remains, their behavior changes. They plan more deliberately, verify more strategically, and stop wasting calls on low-value paths.
To make this concrete, the authors introduce:
Budget Tracker, a lightweight mechanism that surfaces real-time budget information during reasoning.
BATS (Budget-Aware Test-time Scaling), a framework that dynamically decides when to dig deeper, when to pivot, and when to stop—based on remaining resources.
The result? Agents that don’t just perform better, but do so more efficiently, pushing the cost–performance frontier without any additional training.
The bigger takeaway: scaling agentic systems isn’t about spending more—it’s about spending smarter.
#AgenticAI#AIResearch#TestTimeScaling#ToolUsingAgents#CostAwareAI#LLMs#AIInfrastructure#AIEfficiency#DeepResearch#MachineLearning
📢 This new paper introduces one of the most compelling shifts we’ve seen in reasoning research lately: moving LLMs from sequential emulation toward true native parallel cognition.
The Native Parallel Reasoner (NPR) proposes a teacher-free framework that lets models self-develop parallel reasoning abilities, not by mimicking stronger models, but by progressively learning how to decompose, explore, and verify multiple reasoning paths at once.
The three-stage design is especially interesting:
- Self-distilled RL to discover structured reasoning formats without external supervision
- Parallel SFT to stabilize real parallel execution using dedicated attention masks and positional encoding
- PAPO (Parallel-Aware Policy Optimization) to optimize branching strategies directly inside the parallel computation graph
What makes this work stand out is that NPR achieves 100% genuine parallel execution, no hidden autoregressive fallbacks, while delivering substantial performance gains across math and logic benchmarks. And with up to 4.6× faster inference, it shows how native parallelism can be both more accurate and significantly more efficient.
Overall, this paper pushes forward an exciting direction in agentic reasoning: models that don’t just reason more deeply, but reason widely, exploring diverse solution paths, cross-checking them, and converging on more reliable answers.
#ParallelReasoning#LLMResearch#AIEngineering#ReinforcementLearning#AgenticAI#AIPapers#LLMOptimization#NPR
🚀 Google DeepMind just dropped one of the most important papers on agentic AI this year and it changes how we think about scaling multi-agent systems.
Instead of relying on intuition or hype, the team builds a quantitative science around agent coordination, running 180 controlled evaluations across four real agentic benchmarks and three major LLM families. And the insights are genuinely transformative.
The paper challenges a long-standing assumption in the community: that more agents automatically lead to better performance.
The data shows something far more nuanced—and far more interesting.
• Multi-agent systems aren’t universally better.
Depending on the task, MAS performance ranged from +81% all the way to –70%.
Financial reasoning benefits massively from collaborative agents, while sequential planning tasks collapse under coordination overhead.
• Tool-heavy tasks expose the “coordination tax.”
The authors formalize a tool–coordination trade-off: as the number of tools grows, multi-agent systems often lose efficiency faster than they gain intelligence, making a single strong agent the better design choice.
• There’s a capability saturation point.
Once a single agent crosses ~45% baseline performance, adding more agents offers diminishing or even negative returns, because communication and synchronization costs outweigh the benefits.
• Error propagation depends heavily on architecture.
Independent agents amplify mistakes 17.2×, while centralized systems contain errors to 4.4×—a stark reminder that topology matters just as much as agent count.
• Task structure—not hype—dictates the “right” coordination strategy.
Centralized coordination excels in structured, parallelizable domains (e.g., finance).
Decentralized systems shine in high-entropy environments (e.g., dynamic web navigation).
Sequential, state-dependent tasks? Multi-agent setups almost always degrade performance.
The most exciting part: the authors build a predictive model that selects the optimal architecture with 87% accuracy, using measurable properties like decomposability, tool complexity, and single-agent baseline.
It’s the first real step toward a science of agentic scaling—moving the field away from heuristics and toward principled, evidence-driven design.
#GoogleDeepMind#AIResearch#AgenticAI#MultiAgentSystems#LLMAgents#ScalingLaws#AIEngineering#AIEvaluation#ArtificialIntelligence#AICommunity
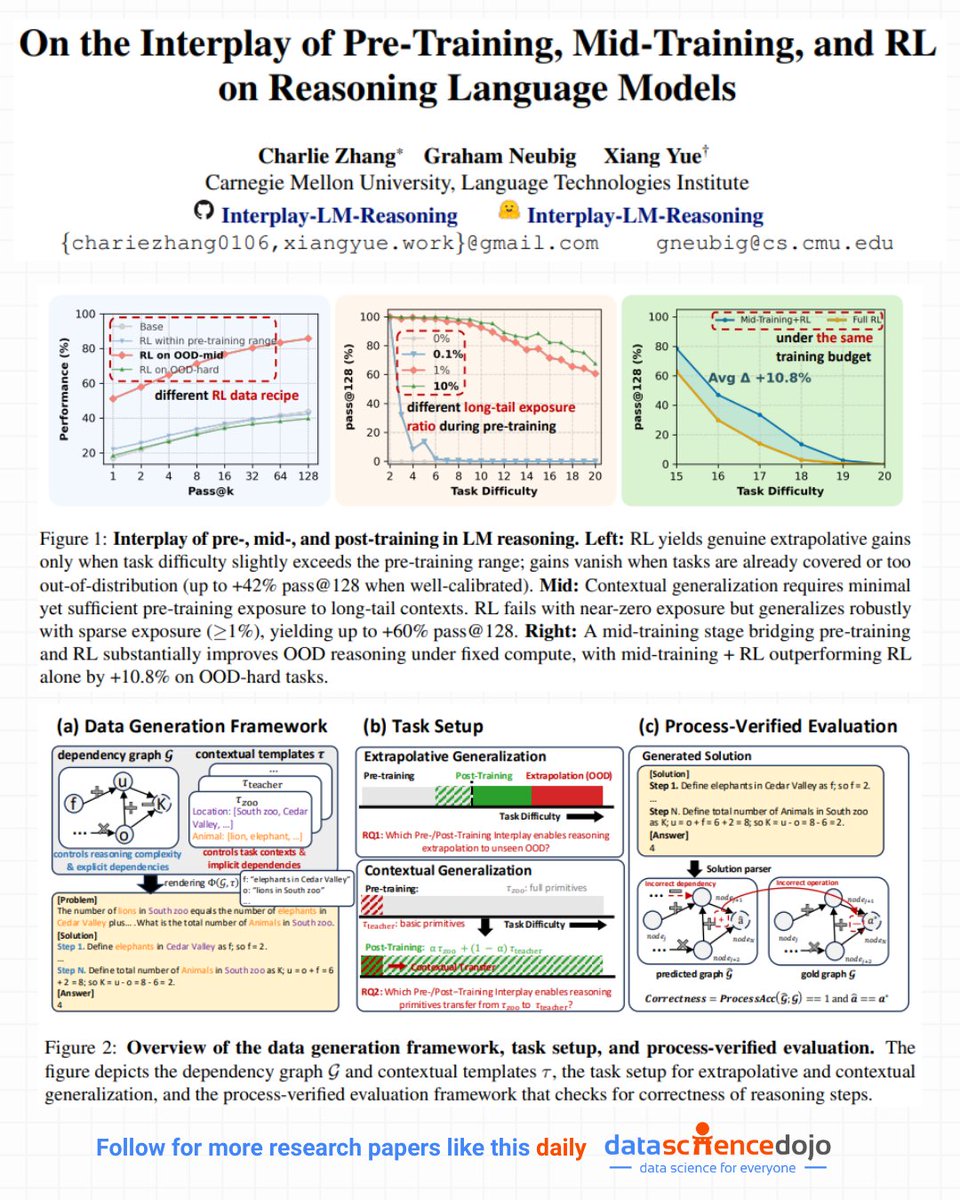
🚀 A rare paper that finally explains why RL sometimes works—and why it often doesn’t.
This paper offers one of the clearest deep dives yet into how reasoning actually develops inside LMs and the results challenge a lot of assumptions in the current RL-reasoning hype cycle.
The authors build a fully controlled training environment (synthetic tasks with explicit DAG reasoning steps), which lets them isolate the causal effect of pre-training, mid-training, and RL, rather than treating them as a black box. And the findings are surprisingly intuitive once seen clearly:
1. RL doesn’t magically create reasoning, it only expands what’s already there.
If pre-training leaves no “headroom” or if RL data is too easy/hard, RL simply sharpens existing abilities instead of unlocking new ones.
2. Minimal exposure during pre-training is enough to unlock contextual generalization.
Even 1% coverage of a new context is enough for RL to transfer reasoning patterns reliably—but 0% exposure means no amount of RL can help. RL can’t conjure primitives out of thin air.
3. Mid-training is a missing piece in many pipelines.
Adding a bridging phase between pre-training and RL drastically improves both in-distribution and OOD generalization, especially under fixed compute. The model becomes far more “RL-ready.”
4. Process-level rewards reduce reward hacking, dramatically.
When rewards check both the final answer and the intermediate steps, models stop exploiting shortcuts and start producing structurally sound reasoning. Pass@1 and pass@128 both improve as a result.
Overall, the work gives a structured explanation of why some RL approaches show huge gains while others plateau: it’s less about clever reward shaping and more about the interaction of all three stages. For teams training reasoning models, this paper is basically a blueprint for designing data curricula and compute allocation more intelligently.
#AIResearch#ReasoningLLMs#ReinforcementLearning#PreTraining#MidTraining#LLMGeneralization#AIAlignment#MachineLearning#AILiterature#DeepLearning
🚨 LLMs Are Getting Smarter—Here’s How Structured Knowledge Is Quietly Transforming Them
This new survey is one of the most comprehensive deep dives into a question everyone in AI is asking right now:
How do we make LLMs reliable, grounded, and reasoning-capable—not just bigger?
The paper breaks down a major shift happening across the AI ecosystem:
LLMs are no longer operating alone. They’re being paired with knowledge bases, knowledge graphs, retrieval systems, and hybrid reasoning frameworks to overcome their biggest limitations.
Some standout insights:
🔹 The “internal knowledge vs external knowledge” gap is real.
LLMs still hallucinate, struggle with factual consistency, and degrade on specialized domains. Integrating structured knowledge—UMLS, Wikidata, domain KGs—dramatically improves grounding.
🔹 Three integration pillars define the future of intelligent systems:
• Knowledge Bases: High-precision facts that reduce hallucination.
• Knowledge Graphs: Relationship-aware reasoning for multi-hop queries and semantics.
• RAG Systems: Real-time retrieval that acts as a dynamic memory layer.
🔹 Next-gen models aren’t just generating—they’re reasoning.
Techniques like GraphRAG, ToG, MetaRAG, semi-structured CoT, and KG-augmented agents give LLMs the ability to explain, trace, and verify their outputs.
🔹 Integration solves real pain points:
Interpretability, long context limits, outdated training data, and high compute costs all improve when LLMs rely less on parametric memory and more on structured external knowledge.
🔹 The survey maps out a new architecture direction:
LLMs that continuously retrieve, refine, and optimize knowledge—self-improving systems that adapt to domain shifts without retraining.
If you care about RAG, enterprise AI, reasoning, or building production-grade agents, this paper is a goldmine. It shows where the field is heading:
from “giant text predictors” to deeply grounded, knowledge-aware AI systems.
#AIResearch#LLMs#KnowledgeGraphs#RAG#GenerativeAI#AIEngineering#EnterpriseAI#MachineLearning#AIEthics#SemanticAI#AIIntegration#NLP
🚀 When Academic Writing Meets Agentic AI — PaperDebugger Turns Overleaf Into a Fully Autonomous Co-Author.
Academic writing has always suffered from one big bottleneck: tooling that lives outside the writing environment. Copy–paste workflows, broken context, lost revision histories, the entire process is fragmented.
PaperDebugger changes that. Completely.
This new system brings a plugin-based, multi-agent AI stack directly inside Overleaf, giving researchers something we’ve been waiting for:
👉 Real editing
👉 Real critique
👉 Real research assistance
👉 All happening in-editor, context-aware, and applied through deterministic diff-based patches.
What makes this system special isn’t just LLMs, it’s the deep orchestration layer behind them.
PaperDebugger runs on a Kubernetes-native backend, uses the Model Context Protocol (MCP) for tool interoperability, and coordinates specialized agents for critique, rewriting, research retrieval, and structured reviews, all streaming back into Overleaf through a Chrome-approved extension.
The result?
A writing loop where you highlight text → trigger an agent → inspect before/after diffs → apply a patch with one click.
No copy–paste. No switching windows. No context loss.
Even more impressive: PaperDebugger doesn’t stop at editing.
Its Researcher agent can perform deep semantic literature search, retrieve relevant papers, generate comparisons, and build structured related-work maps — turning Overleaf into a research cockpit, not just an editor.
Early telemetry shows real-world traction: dozens of active users, hundreds of projects, and thousands of patch-level interactions — clear evidence that academic writing is moving toward agentic, in-editor intelligence.
If Overleaf was the workspace, PaperDebugger just made it the workflow.
#PaperDebugger#AIWritingTools#AgenticAI#OverleafAI#LLMAgents#MCP#AcademicWriting#AIResearchTools#MultiAgentSystems#AIInEditor#AIProductivity#ResearchWorkflows#AIForScientists#KubernetesAI#LLMEngineering
🚨 AI agents just learned how to actually learn.
Most AI agents today can recall facts… But ask them to learn how to do something new, a procedure, a workflow, a step-by-step method, after deployment, in the real world? Almost none can do it.
That’s the gap this new paper addresses.
The team at Altrina just introduced PRAXIS, a lightweight, real-time procedural learning mechanism that finally gives AI agents something they’ve been missing:
👉 The ability to learn new skills from experience while operating in the wild.
💡 Why this matters
In real environments like web apps, enterprise systems, dashboards, CRMs, and forms-heavy workflows…
…procedures break far more often than facts. Buttons change, layouts shift, onboarding flows get redesigned and suddenly your agent is lost.
Humans handle this through procedural memory: we recognize a familiar situation and recall what worked last time.
PRAXIS does the same.
It stores:
- The environment state before an action
- The agent’s internal goal
- The action taken
- The resulting state after the action
Then, when the agent encounters a similar situation, it retrieves these “experience traces” and uses them as actionable priors.
This small change leads to big gains.
Key improvements:
- Average task success improved from 40.3% → 44.1%.
- Mean reliability across repeated runs jumped from 74.5% → 79.0%.
- Agents completed tasks using fewer steps (25.2 → 20.2 steps on average).
- Increasing retrieval breadth (how many past memories PRAXIS checks) leads to increasingly strong performance.
In plain terms:
The agent makes fewer mistakes, takes more consistent actions, and wastes less time.
This is a real glimpse of continual learning for deployed agents, without retraining the foundation model and pushes us one step closer to agents that don’t just “act"…but improve, adapt, and remember how to do things, like humans do.
#AIAgents#AgenticAI#ProceduralLearning#LLM#AIResearch#AutonomousAgents#ContinualLearning#AIProductivity#WebAutomation#PRAXIS#Altrina#AIInnovation#MachineLearning
🔥 Meta just released a hard-hitting reality check on scaling LLM training and it’s not the story we’ve been telling ourselves.
If you’ve been assuming that “just add more GPUs” is the golden path to faster, cheaper training… this new study from FAIR turns that idea upside down.
In this paper, Meta dissects what really happens when you scale LLM training across thousands of accelerators and the findings are surprisingly counter-intuitive:
💡 Key Insights:
- Diminishing returns kick in fast.
Beyond a certain scale (≈128 H100s), training becomes communication-bound, not compute-bound — meaning GPUs sit idle waiting for parameters to sync.
- FSDP isn’t magic at massive scale.
Fully Sharded Data Parallelism introduces heavy AllGather / ReduceScatter operations that scale poorly, causing performance slowdowns even as hardware grows.
- Model parallelism comes back into the spotlight.
Contrary to old assumptions, adding tensor or pipeline parallelism can improve throughput under FSDP by reducing communication groups.
- More power consumed, fewer tokens processed.
Power draw scales linearly, but throughput doesn’t — meaning energy efficiency drops as the cluster gets bigger.
- Hardware progress isn’t solving the bottleneck.
H100s offer 3× compute over A100s… but NVLink and interconnect bandwidth haven’t kept up. So communication overhead only gets worse.
- Larger models = proportionally larger communication tax.
Scaling from 7B → 70B expands compute and communication, shrinking hardware utilization even further.
To summarize, this paper is a complete guide on:
• Why communication, not compute, is now the real bottleneck
• How model parallelism can counteract FSDP overhead
• Why training efficiency collapses at massive scale
• What future hardware + software need to fix
• Practical takeaways for anyone building LLM training stacks
This study is an important reminder:
Scaling isn’t just about FLOPs, it’s about balancing compute, memory, networking, and communication efficiency. If we don’t rethink parallelism strategies now, bigger clusters will only give us smaller returns.
#MetaAI#LLMTraining#FSDP#ParallelComputing#AIInfrastructure#DeepLearnin#MachineLearningResearch#AIEngineering#ScalingLLMs#TechInsights